 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFVTM: A Recovery and Filtering Vertex Trichotomy Matching for Remote Sensing Image Registration
Apr 02, 2022
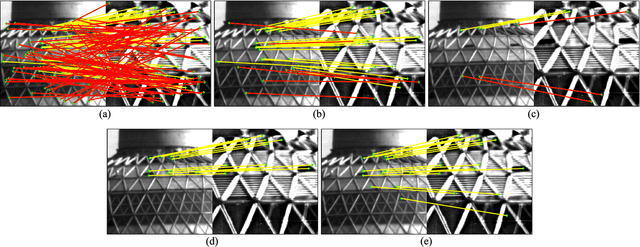
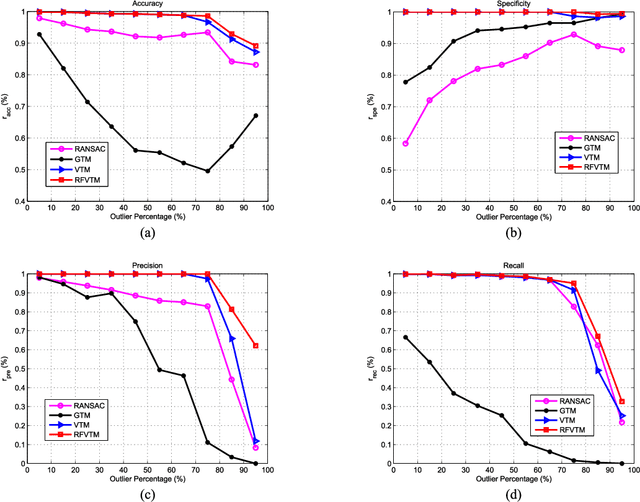

Reliable feature point matching is a vital yet challenging process in feature-based image registration. In this paper,a robust feature point matching algorithm called Recovery and Filtering Vertex Trichotomy Matching (RFVTM) is proposed to remove outliers and retain sufficient inliers for remote sensing images. A novel affine invariant descriptor called vertex trichotomy descriptor is proposed on the basis of that geometrical relations between any of vertices and lines are preserved after affine transformations, which is constructed by mapping each vertex into trichotomy sets. The outlier removals in Vertex Trichotomy Matching (VTM) are implemented by iteratively comparing the disparity of corresponding vertex trichotomy descriptors. Some inliers mistakenly validated by a large amount of outliers are removed in VTM iterations, and several residual outliers close to correct locations cannot be excluded with the same graph structures. Therefore, a recovery and filtering strategy is designed to recover some inliers based on identical vertex trichotomy descriptors and restricted transformation errors. Assisted with the additional recovered inliers, residual outliers can also be filtered out during the process of reaching identical graph for the expanded vertex sets. Experimental results demonstrate the superior performance on precision and stability of this algorithm under various conditions, such as remote sensing images with large transformations, duplicated patterns, or inconsistent spectral content.
A Deep-Unfolded Reference-Based RPCA Network For Video Foreground-Background Separation
Oct 02, 2020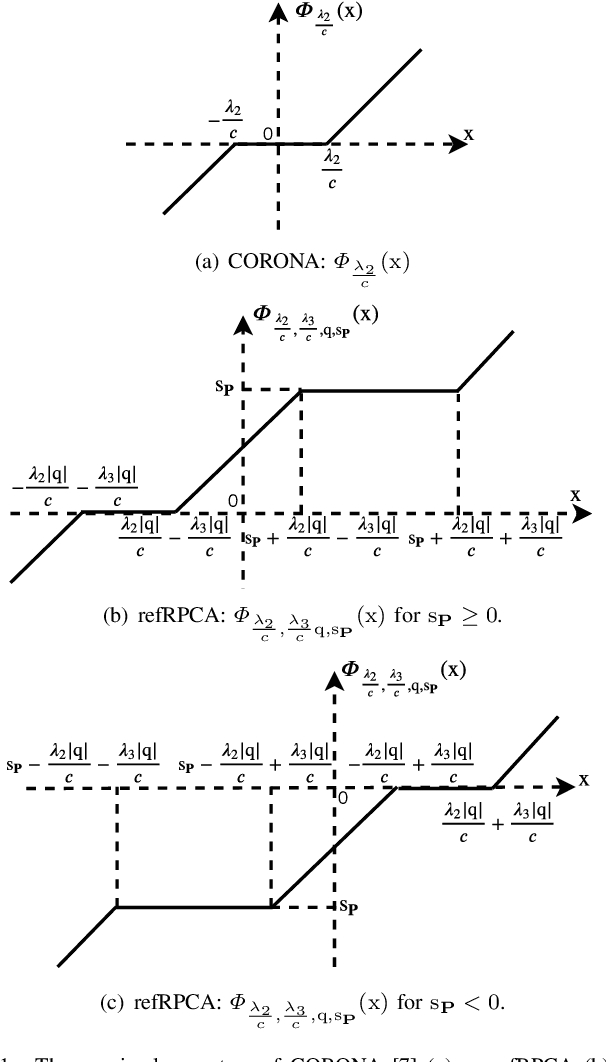
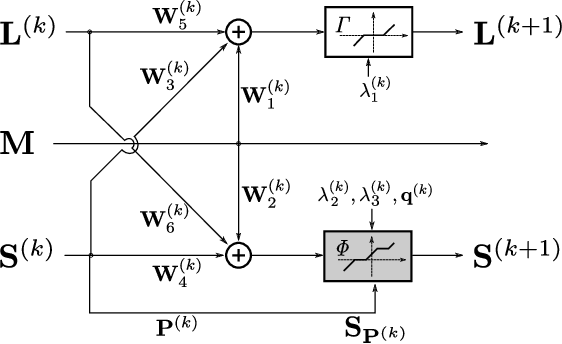
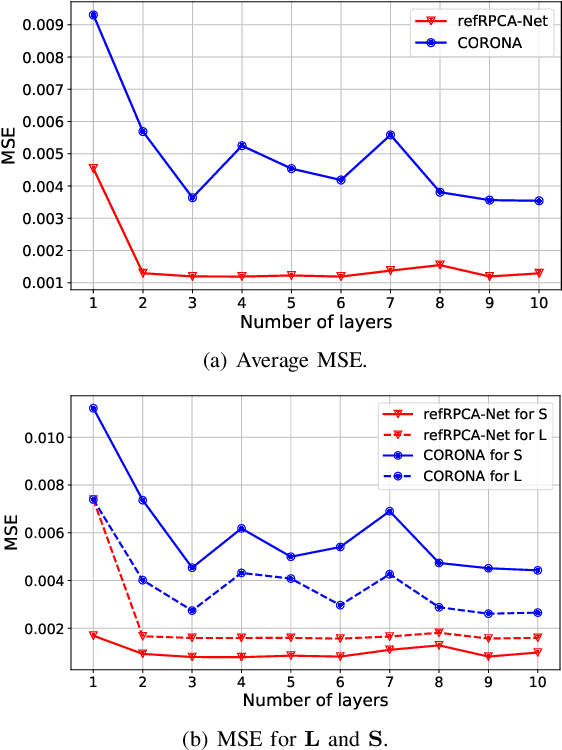

Deep unfolded neural networks are designed by unrolling the iterations of optimization algorithms. They can be shown to achieve faster convergence and higher accuracy than their optimization counterparts. This paper proposes a new deep-unfolding-based network design for the problem of Robust Principal Component Analysis (RPCA) with application to video foreground-background separation. Unlike existing designs, our approach focuses on modeling the temporal correlation between the sparse representations of consecutive video frames. To this end, we perform the unfolding of an iterative algorithm for solving reweighted $\ell_1$-$\ell_1$ minimization; this unfolding leads to a different proximal operator (a.k.a. different activation function) adaptively learned per neuron. Experimentation using the moving MNIST dataset shows that the proposed network outperforms a recently proposed state-of-the-art RPCA network in the task of video foreground-background separation.
Interpretable Deep Recurrent Neural Networks via Unfolding Reweighted $\ell_1$-$\ell_1$ Minimization: Architecture Design and Generalization Analysis
Mar 18, 2020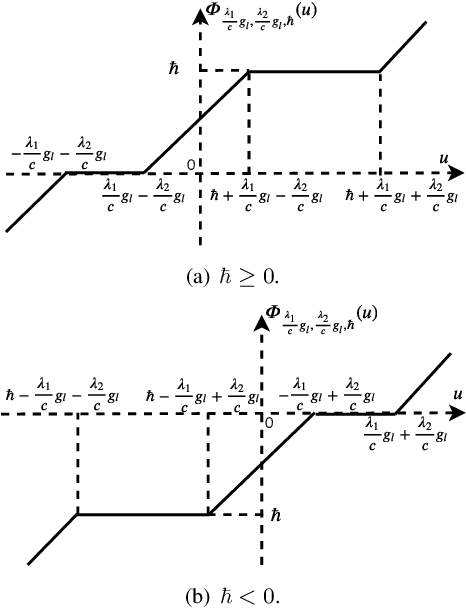

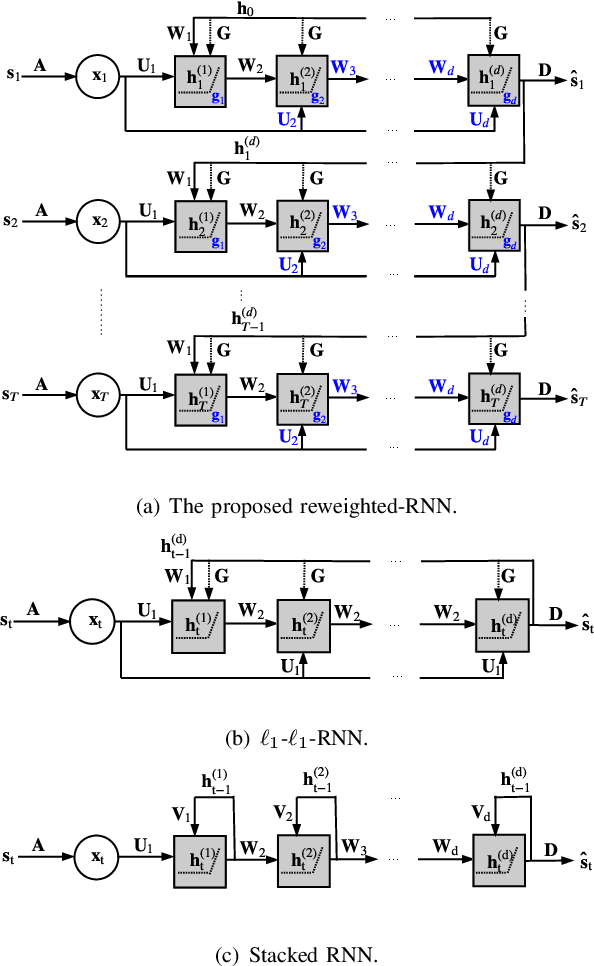
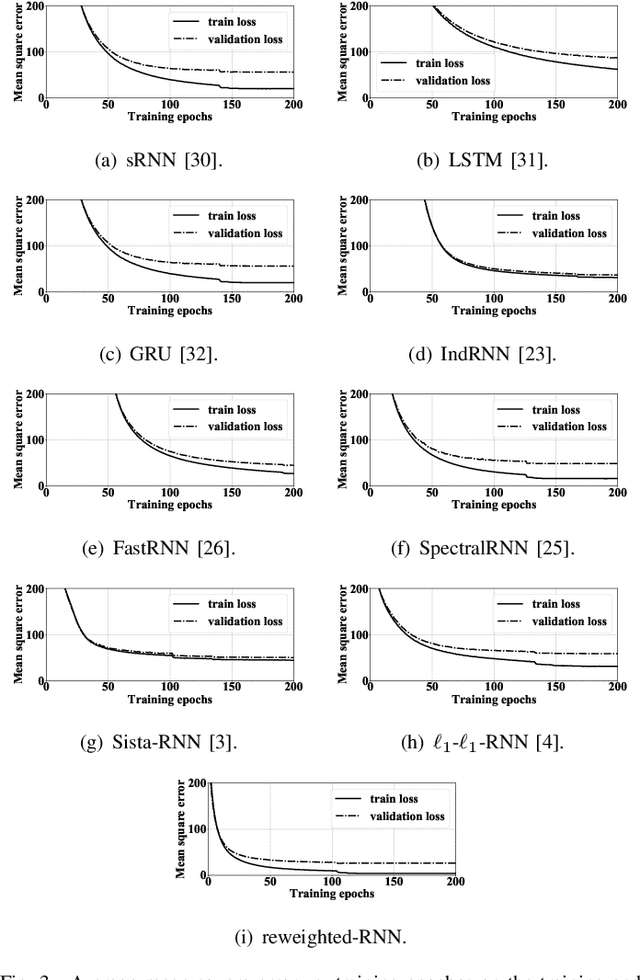
Deep unfolding methods---for example, the learned iterative shrinkage thresholding algorithm (LISTA)---design deep neural networks as learned variations of optimization methods. These networks have been shown to achieve faster convergence and higher accuracy than the original optimization methods. In this line of research, this paper develops a novel deep recurrent neural network (coined reweighted-RNN) by the unfolding of a reweighted $\ell_1$-$\ell_1$ minimization algorithm and applies it to the task of sequential signal reconstruction. To the best of our knowledge, this is the first deep unfolding method that explores reweighted minimization. Due to the underlying reweighted minimization model, our RNN has a different soft-thresholding function (alias, different activation functions) for each hidden unit in each layer. Furthermore, it has higher network expressivity than existing deep unfolding RNN models due to the over-parameterizing weights. Importantly, we establish theoretical generalization error bounds for the proposed reweighted-RNN model by means of Rademacher complexity. The bounds reveal that the parameterization of the proposed reweighted-RNN ensures good generalization. We apply the proposed reweighted-RNN to the problem of video frame reconstruction from low-dimensional measurements, that is, sequential frame reconstruction. The experimental results on the moving MNIST dataset demonstrate that the proposed deep reweighted-RNN significantly outperforms existing RNN models.
Designing recurrent neural networks by unfolding an l1-l1 minimization algorithm
Feb 18, 2019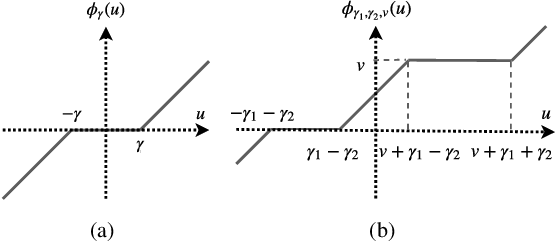
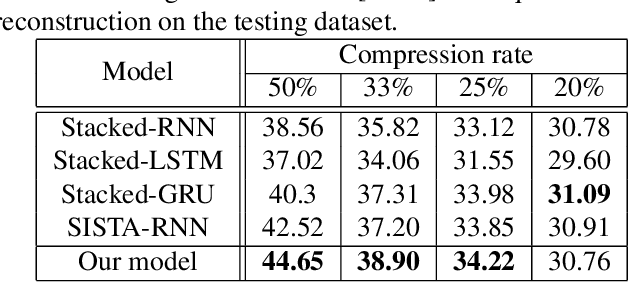
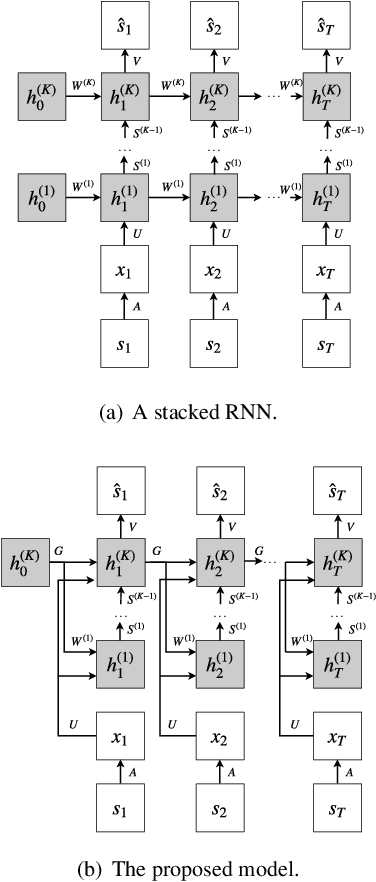
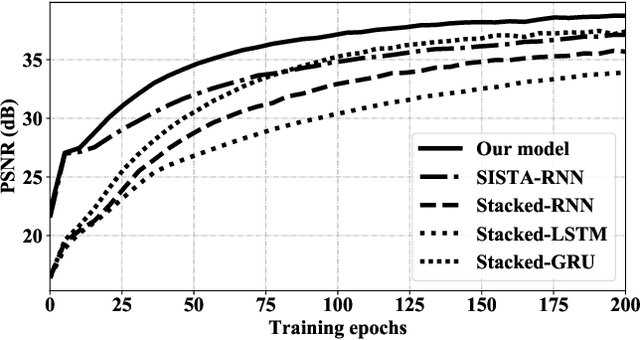
We propose a new deep recurrent neural network (RNN) architecture for sequential signal reconstruction. Our network is designed by unfolding the iterations of the proximal gradient method that solves the l1-l1 minimization problem. As such, our network leverages by design that signals have a sparse representation and that the difference between consecutive signal representations is also sparse. We evaluate the proposed model in the task of reconstructing video frames from compressive measurements and show that it outperforms several state-of-the-art RNN models.
Online Decomposition of Compressive Streaming Data Using $n$-$\ell_1$ Cluster-Weighted Minimization
Feb 08, 2018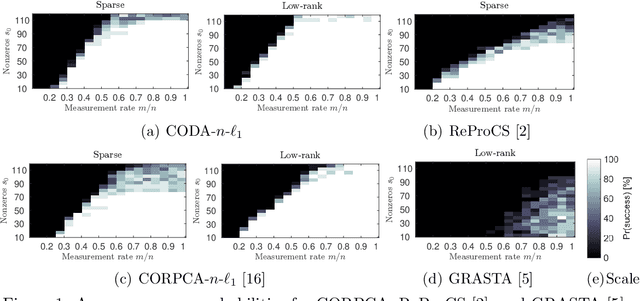

We consider a decomposition method for compressive streaming data in the context of online compressive Robust Principle Component Analysis (RPCA). The proposed decomposition solves an $n$-$\ell_1$ cluster-weighted minimization to decompose a sequence of frames (or vectors), into sparse and low-rank components, from compressive measurements. Our method processes a data vector of the stream per time instance from a small number of measurements in contrast to conventional batch RPCA, which needs to access full data. The $n$-$\ell_1$ cluster-weighted minimization leverages the sparse components along with their correlations with multiple previously-recovered sparse vectors. Moreover, the proposed minimization can exploit the structures of sparse components via clustering and re-weighting iteratively. The method outperforms the existing methods for both numerical data and actual video data.
Compressive Online Robust Principal Component Analysis with Optical Flow for Video Foreground-Background Separation
Oct 25, 2017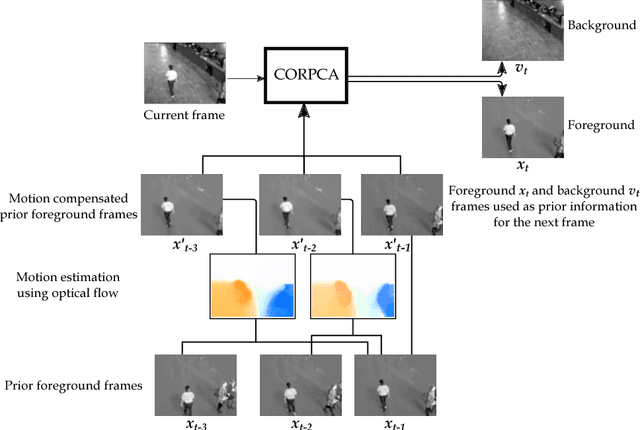



In the context of online Robust Principle Component Analysis (RPCA) for the video foreground-background separation, we propose a compressive online RPCA with optical flow that separates recursively a sequence of frames into sparse (foreground) and low-rank (background) components. Our method considers a small set of measurements taken per data vector (frame), which is different from conventional batch RPCA, processing all the data directly. The proposed method also incorporates multiple prior information, namely previous foreground and background frames, to improve the separation and then updates the prior information for the next frame. Moreover, the foreground prior frames are improved by estimating motions between the previous foreground frames using optical flow and compensating the motions to achieve higher quality foreground prior. The proposed method is applied to online video foreground and background separation from compressive measurements. The visual and quantitative results show that our method outperforms the existing methods.
Incorporating Prior Information in Compressive Online Robust Principal Component Analysis
May 27, 2017
We consider an online version of the robust Principle Component Analysis (PCA), which arises naturally in time-varying source separations such as video foreground-background separation. This paper proposes a compressive online robust PCA with prior information for recursively separating a sequences of frames into sparse and low-rank components from a small set of measurements. In contrast to conventional batch-based PCA, which processes all the frames directly, the proposed method processes measurements taken from each frame. Moreover, this method can efficiently incorporate multiple prior information, namely previous reconstructed frames, to improve the separation and thereafter, update the prior information for the next frame. We utilize multiple prior information by solving $n\text{-}\ell_{1}$ minimization for incorporating the previous sparse components and using incremental singular value decomposition ($\mathrm{SVD}$) for exploiting the previous low-rank components. We also establish theoretical bounds on the number of measurements required to guarantee successful separation under assumptions of static or slowly-changing low-rank components. Using numerical experiments, we evaluate our bounds and the performance of the proposed algorithm. In addition, we apply the proposed algorithm to online video foreground and background separation from compressive measurements. Experimental results show that the proposed method outperforms the existing methods.
Measurement Bounds for Sparse Signal Reconstruction with Multiple Side Information
Jan 18, 2017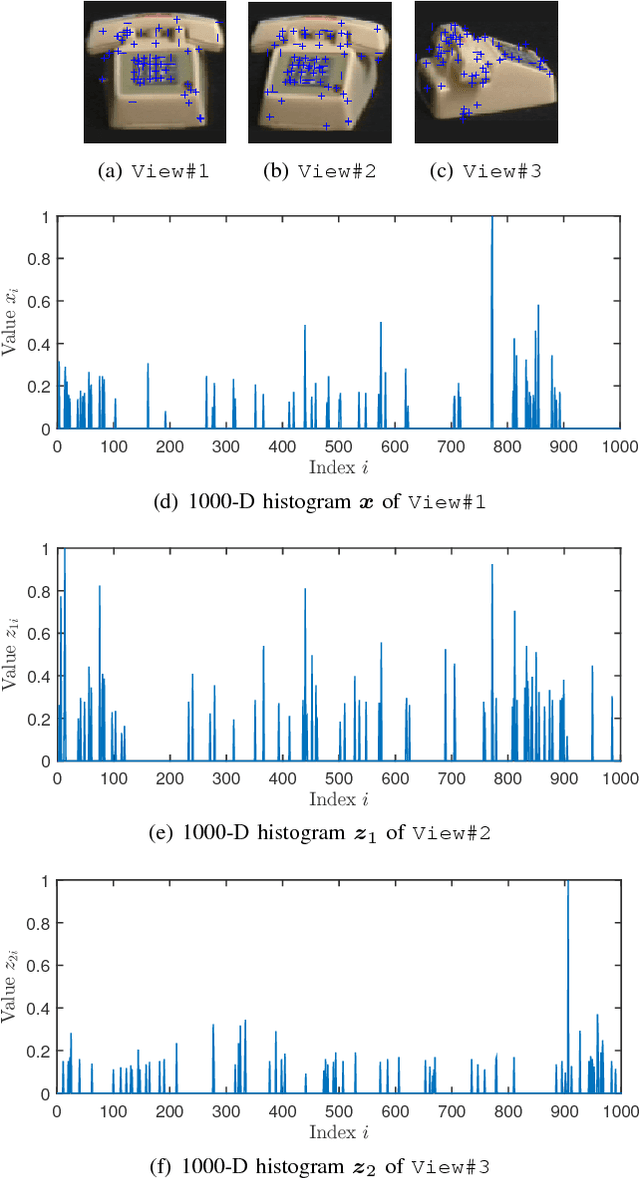
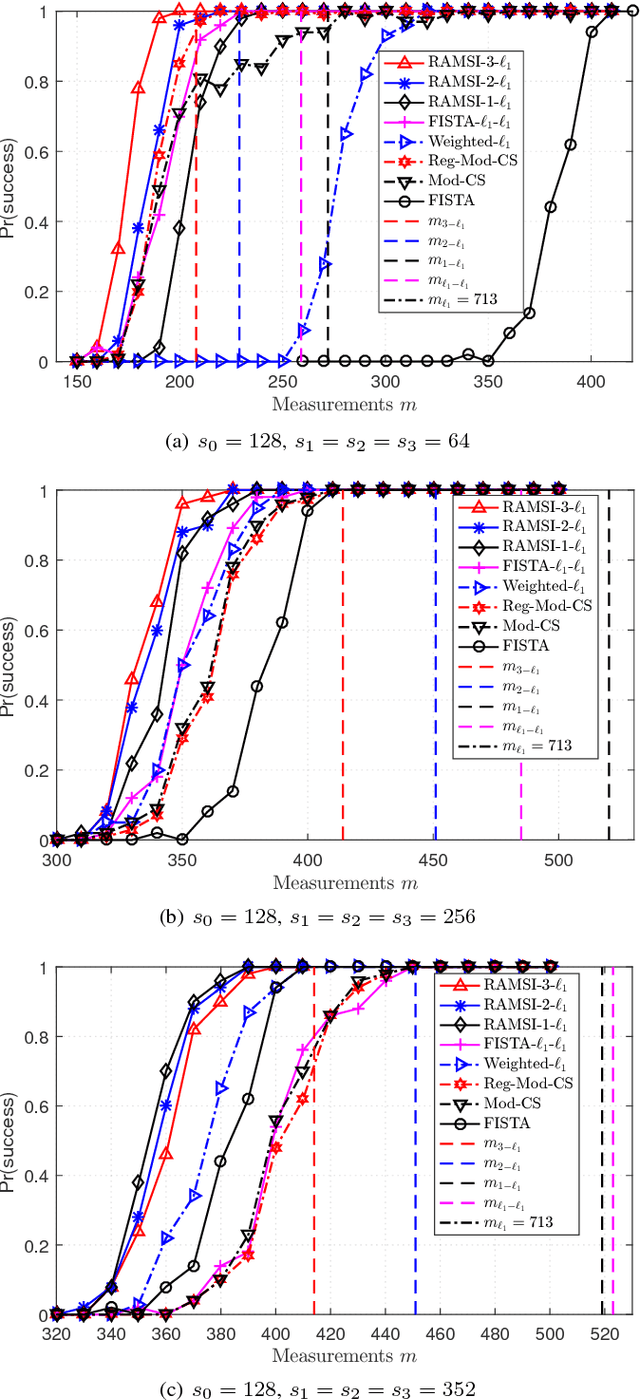
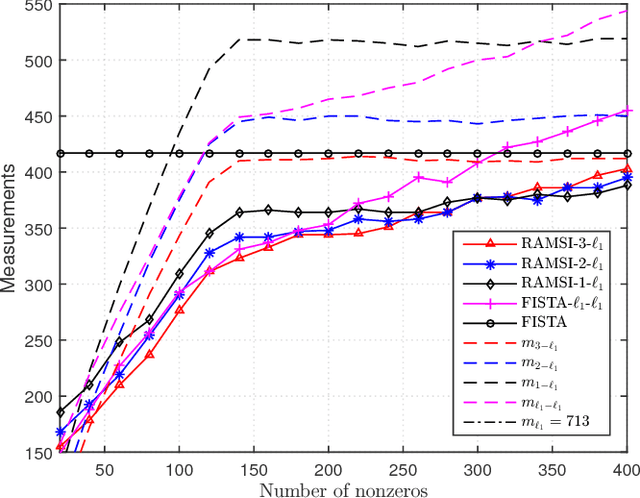
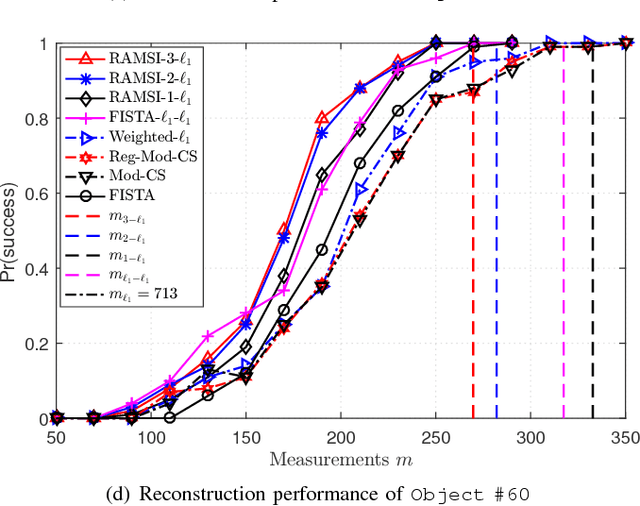
In the context of compressed sensing (CS), this paper considers the problem of reconstructing sparse signals with the aid of other given correlated sources as multiple side information. To address this problem, we theoretically study a generic \textcolor{black}{weighted $n$-$\ell_{1}$ minimization} framework and propose a reconstruction algorithm that leverages multiple side information signals (RAMSI). The proposed RAMSI algorithm computes adaptively optimal weights among the side information signals at every reconstruction iteration. In addition, we establish theoretical bounds on the number of measurements that are required to successfully reconstruct the sparse source by using \textcolor{black}{weighted $n$-$\ell_{1}$ minimization}. The analysis of the established bounds reveal that \textcolor{black}{weighted $n$-$\ell_{1}$ minimization} can achieve sharper bounds and significant performance improvements compared to classical CS. We evaluate experimentally the proposed RAMSI algorithm and the established bounds using synthetic sparse signals as well as correlated feature histograms, extracted from a multiview image database for object recognition. The obtained results show clearly that the proposed algorithm outperforms state-of-the-art algorithms---\textcolor{black}{including classical CS, $\ell_1\text{-}\ell_1$ minimization, Modified-CS, regularized Modified-CS, and weighted $\ell_1$ minimization}---in terms of both the theoretical bounds and the practical performance.
Distributed Coding of Multiview Sparse Sources with Joint Recovery
Jul 18, 2016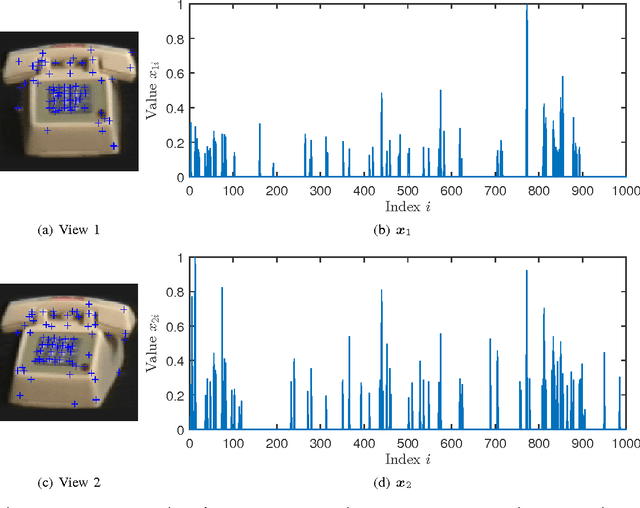
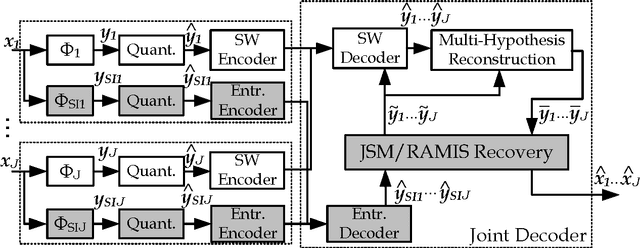
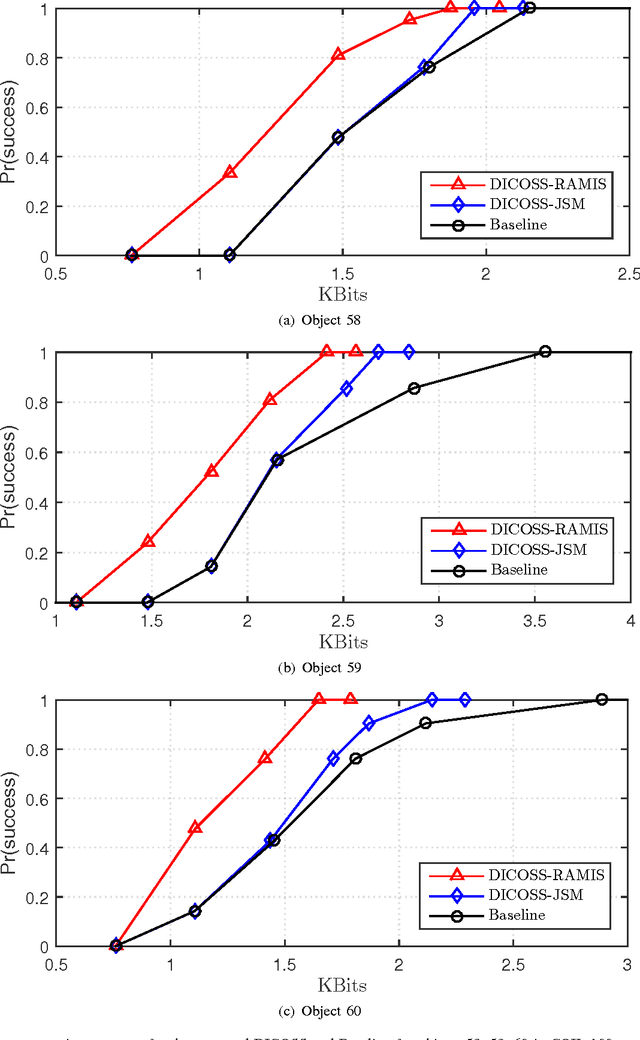
In support of applications involving multiview sources in distributed object recognition using lightweight cameras, we propose a new method for the distributed coding of sparse sources as visual descriptor histograms extracted from multiview images. The problem is challenging due to the computational and energy constraints at each camera as well as the limitations regarding inter-camera communication. Our approach addresses these challenges by exploiting the sparsity of the visual descriptor histograms as well as their intra- and inter-camera correlations. Our method couples distributed source coding of the sparse sources with a new joint recovery algorithm that incorporates multiple side information signals, where prior knowledge (low quality) of all the sparse sources is initially sent to exploit their correlations. Experimental evaluation using the histograms of shift-invariant feature transform (SIFT) descriptors extracted from multiview images shows that our method leads to bit-rate saving of up to 43% compared to the state-of-the-art distributed compressed sensing method with independent encoding of the sources.
Sparse Signal Reconstruction with Multiple Side Information using Adaptive Weights for Multiview Sources
May 22, 2016
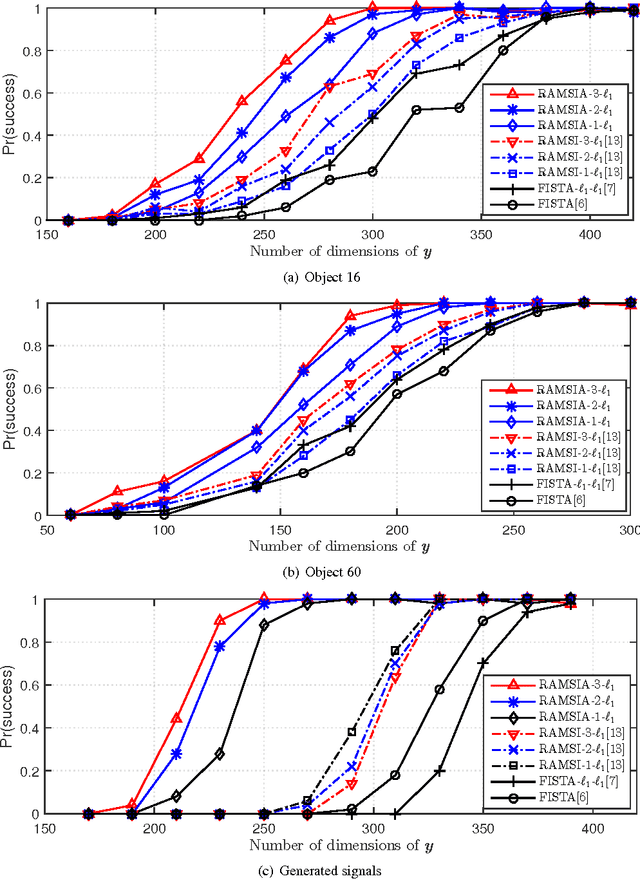
This work considers reconstructing a target signal in a context of distributed sparse sources. We propose an efficient reconstruction algorithm with the aid of other given sources as multiple side information (SI). The proposed algorithm takes advantage of compressive sensing (CS) with SI and adaptive weights by solving a proposed weighted $n$-$\ell_{1}$ minimization. The proposed algorithm computes the adaptive weights in two levels, first each individual intra-SI and then inter-SI weights are iteratively updated at every reconstructed iteration. This two-level optimization leads the proposed reconstruction algorithm with multiple SI using adaptive weights (RAMSIA) to robustly exploit the multiple SIs with different qualities. We experimentally perform our algorithm on generated sparse signals and also correlated feature histograms as multiview sparse sources from a multiview image database. The results show that RAMSIA significantly outperforms both classical CS and CS with single SI, and RAMSIA with higher number of SIs gained more than the one with smaller number of SIs.