 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the benefit of parameter-driven approaches for the modeling and the prediction of Satisfied User Ratio for compressed video
Jun 20, 2022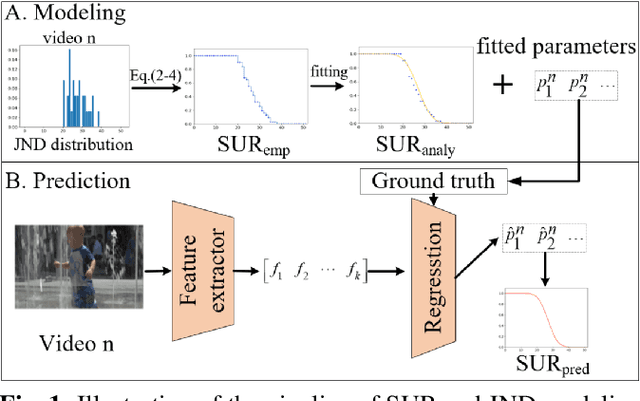

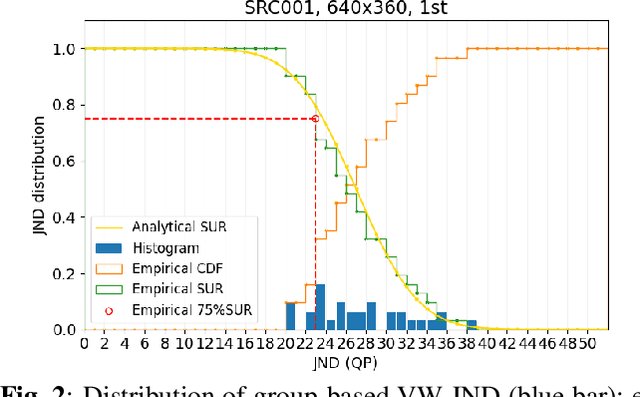
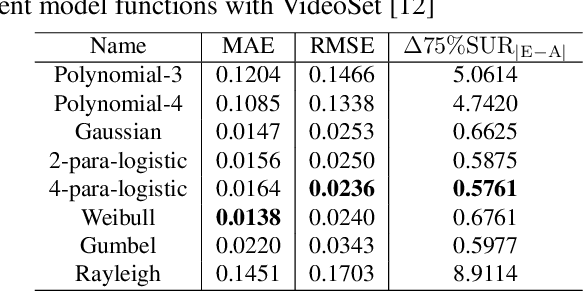
The human eye cannot perceive small pixel changes in images or videos until a certain threshold of distortion. In the context of video compression, Just Noticeable Difference (JND) is the smallest distortion level from which the human eye can perceive the difference between reference video and the distorted/compressed one. Satisfied-User-Ratio (SUR) curve is the complementary cumulative distribution function of the individual JNDs of a viewer group. However, most of the previous works predict each point in SUR curve by using features both from source video and from compressed videos with assumption that the group-based JND annotations follow Gaussian distribution, which is neither practical nor accurate. In this work, we firstly compared various common functions for SUR curve modeling. Afterwards, we proposed a novel parameter-driven method to predict the video-wise SUR from video features. Besides, we compared the prediction results of source-only features based (SRC-based) models and source plus compressed videos features (SRC+PVS-based) models.