 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITIScore: An Image-to-Text-to-Image Rating Framework for the Image Captioning Ability of MLLMs
Apr 04, 2026Recent advances in multimodal large language models (MLLMs) have greatly improved image understanding and captioning capabilities. However, existing image captioning benchmarks typically suffer from limited diversity in caption length, the absence of recent advanced MLLMs, and insufficient human annotations, which potentially introduces bias and limits the ability to comprehensively assess the performance of modern MLLMs. To address these limitations, we present a new large-scale image captioning benchmark, termed, ICBench, which covers 12 content categories and consists of both short and long captions generated by 10 advanced MLLMs on 2K images, resulting in 40K captions in total. We conduct extensive human subjective studies to obtain mean opinion scores (MOSs) across fine-grained evaluation dimensions, where short captions are assessed in terms of fluency, relevance, and conciseness, while long captions are evaluated based on fluency, relevance, and completeness. Furthermore, we propose an automated evaluation metric, \textbf{ITIScore}, based on an image-to-text-to-image framework, which measures caption quality through reconstruction consistency. Experimental results demonstrate strong alignment between our automatic metric and human judgments, as well as robust zero-shot generalization ability on other public captioning datasets. Both the dataset and model will be released upon publication.
EditHF-1M: A Million-Scale Rich Human Preference Feedback for Image Editing
Mar 16, 2026Recent text-guided image editing (TIE) models have achieved remarkable progress, while many edited images still suffer from issues such as artifacts, unexpected editings, unaesthetic contents. Although some benchmarks and methods have been proposed for evaluating edited images, scalable evaluation models are still lacking, which limits the development of human feedback reward models for image editing. To address the challenges, we first introduce \textbf{EditHF-1M}, a million-scale image editing dataset with over 29M human preference pairs and 148K human mean opinion ratings, both evaluated from three dimensions, \textit{i.e.}, visual quality, instruction alignment, and attribute preservation. Based on EditHF-1M, we propose \textbf{EditHF}, a multimodal large language model (MLLM) based evaluation model, to provide human-aligned feedback from image editing. Finally, we introduce \textbf{EditHF-Reward}, which utilizes EditHF as the reward signal to optimize the text-guided image editing models through reinforcement learning. Extensive experiments show that EditHF achieves superior alignment with human preferences and demonstrates strong generalization on other datasets. Furthermore, we fine-tune the Qwen-Image-Edit using EditHF-Reward, achieving significant performance improvements, which demonstrates the ability of EditHF to serve as a reward model to scale-up the image editing. Both the dataset and code will be released in our GitHub repository: https://github.com/IntMeGroup/EditHF.
A Cross-Font Image Retrieval Network for Recognizing Undeciphered Oracle Bone Inscriptions
Sep 10, 2024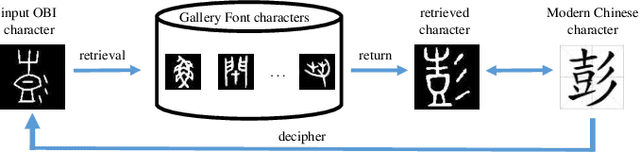
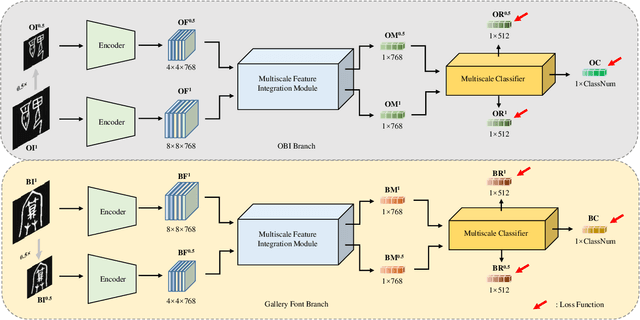
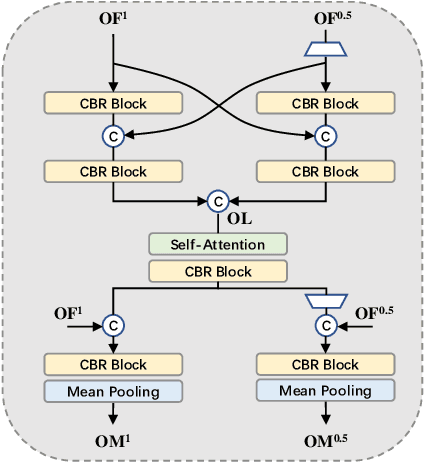

Oracle Bone Inscription (OBI) is the earliest mature writing system known in China to date, which represents a crucial stage in the development of hieroglyphs. Nevertheless, the substantial quantity of undeciphered OBI characters continues to pose a persistent challenge for scholars, while conventional methods of ancient script research are both time-consuming and labor-intensive. In this paper, we propose a cross-font image retrieval network (CFIRN) to decipher OBI characters by establishing associations between OBI characters and other script forms, simulating the interpretive behavior of paleography scholars. Concretely, our network employs a siamese framework to extract deep features from character images of various fonts, fully exploring structure clues with different resolution by designed multiscale feature integration (MFI) module and multiscale refinement classifier (MRC). Extensive experiments on three challenging cross-font image retrieval datasets demonstrate that, given undeciphered OBI characters, our CFIRN can effectively achieve accurate matches with characters from other gallery fonts.
A New Image Quality Database for Multiple Industrial Processes
Jan 29, 2024
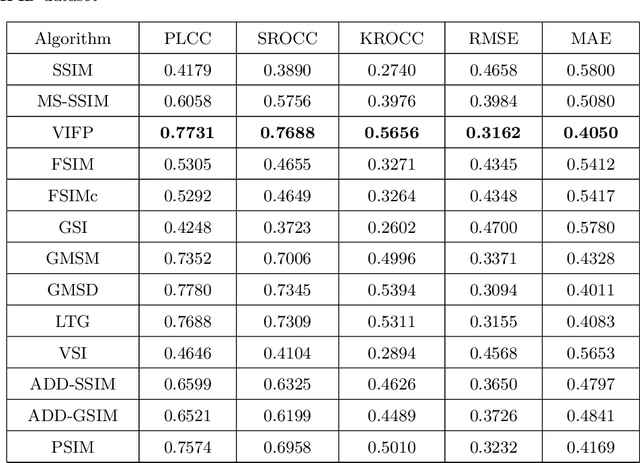
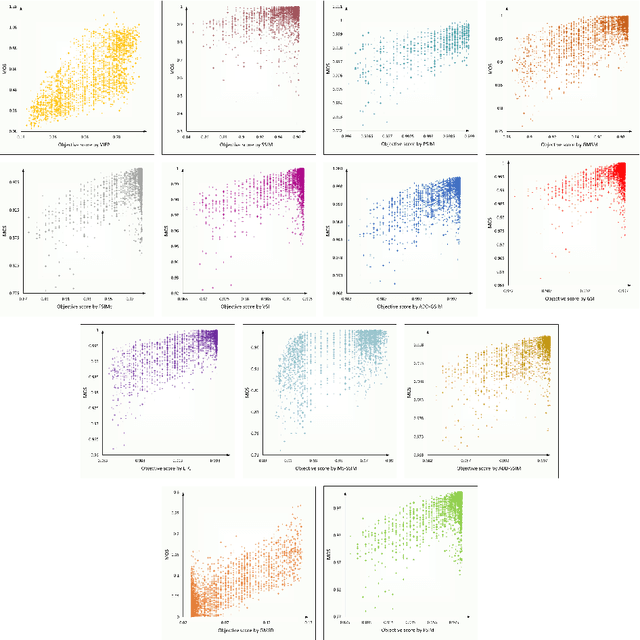
Recent years have witnessed a broader range of applications of image processing technologies in multiple industrial processes, such as smoke detection, security monitoring, and workpiece inspection. Different kinds of distortion types and levels must be introduced into an image during the processes of acquisition, compression, transmission, storage, and display, which might heavily degrade the image quality and thus strongly reduce the final display effect and clarity. To verify the reliability of existing image quality assessment methods, we establish a new industrial process image database (IPID), which contains 3000 distorted images generated by applying different levels of distortion types to each of the 50 source images. We conduct the subjective test on the aforementioned 3000 images to collect their subjective quality ratings in a well-suited laboratory environment. Finally, we perform comparison experiments on IPID database to investigate the performance of some objective image quality assessment algorithms. The experimental results show that the state-of-the-art image quality assessment methods have difficulty in predicting the quality of images that contain multiple distortion types.
Utility-Oriented Underwater Image Quality Assessment Based on Transfer Learning
May 07, 2022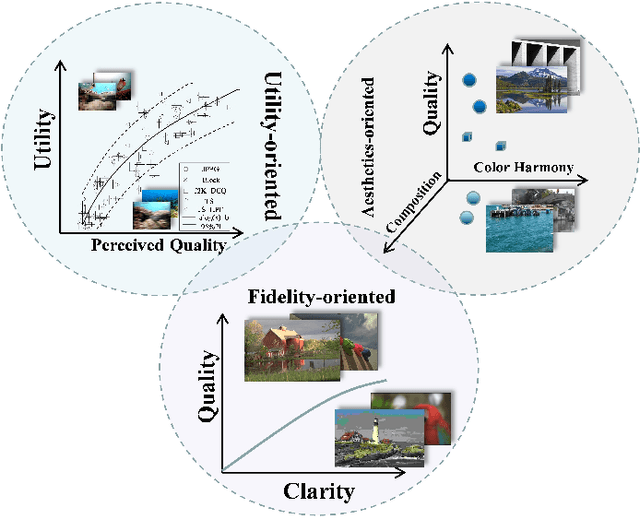

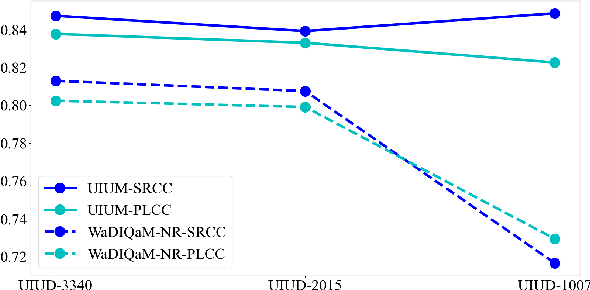
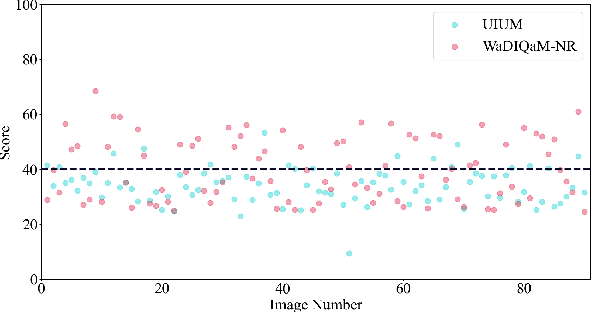
The widespread image applications have greatly promoted the vision-based tasks, in which the Image Quality Assessment (IQA) technique has become an increasingly significant issue. For user enjoyment in multimedia systems, the IQA exploits image fidelity and aesthetics to characterize user experience; while for other tasks such as popular object recognition, there exists a low correlation between utilities and perceptions. In such cases, the fidelity-based and aesthetics-based IQA methods cannot be directly applied. To address this issue, this paper proposes a utility-oriented IQA in object recognition. In particular, we initialize our research in the scenario of underwater fish detection, which is a critical task that has not yet been perfectly addressed. Based on this task, we build an Underwater Image Utility Database (UIUD) and a learning-based Underwater Image Utility Measure (UIUM). Inspired by the top-down design of fidelity-based IQA, we exploit the deep models of object recognition and transfer their features to our UIUM. Experiments validate that the proposed transfer-learning-based UIUM achieves promising performance in the recognition task. We envision our research provides insights to bridge the researches of IQA and computer vision.
AQPDCITY Dataset: Picture-Based PM Monitoring in the Urban Area of Big Cities
Apr 06, 2020
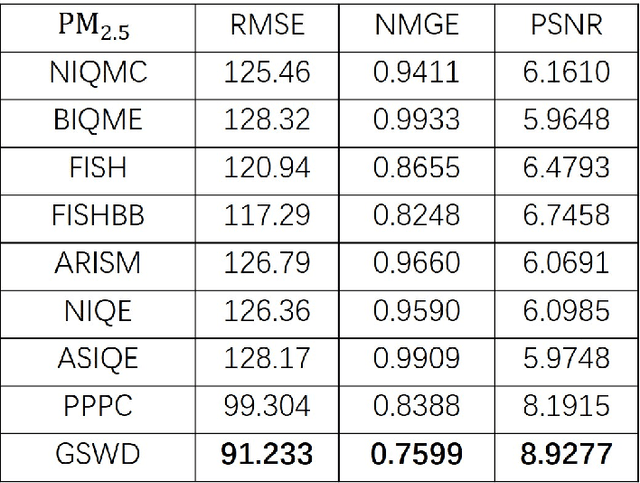
Since Particulate Matters (PMs) are closely related to people's living and health, it has become one of the most important indicator of air quality monitoring around the world. But the existing sensor-based methods for PM monitoring have remarkable disadvantages, such as low-density monitoring stations and high-requirement monitoring conditions. It is highly desired to devise a method that can obtain the PM concentration at any location for the following air quality control in time. The prior works indicate that the PM concentration can be monitored by using ubiquitous photos. To further investigate such issue, we gathered 1,500 photos in big cities to establish a new AQPDCITY dataset. Experiments conducted to check nine state-of-the-art methods on this dataset show that the performance of those above methods perform poorly in the AQPDCITY dataset.
AQPDBJUT Dataset: Picture-Based PM Monitoring in the Campus of BJUT
Mar 21, 2020

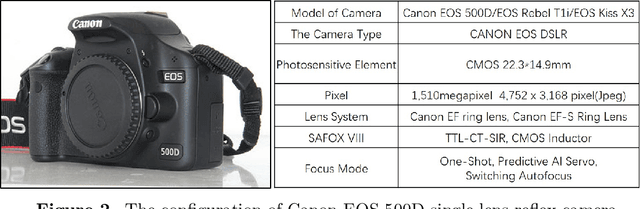
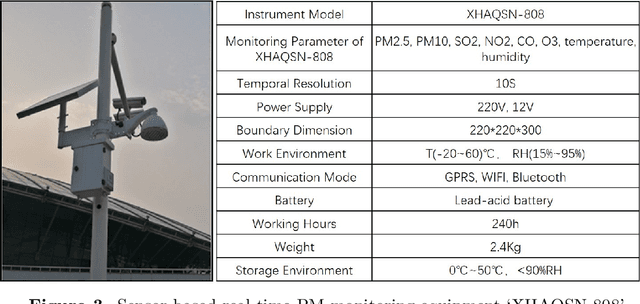
Ensuring the students in good physical levels is imperative for their future health. In recent years, the continually growing concentration of Particulate Matter (PM) has done increasingly serious harm to student health. Hence, it is highly required to prevent and control PM concentrations in the campus. As the source of PM prevention and control, developing a good model for PM monitoring is extremely urgent and has posed a big challenge. It has been found in prior works that photobased methods are available for PM monitoring. To verify the effectiveness of existing PM monitoring methods in the campus, we establish a new dataset which includes 1,500 photos collected in the Beijing University of Technology. Experiments show that stated-of-the-art methods are far from ideal for PM monitoring in the campus.
Learning a No-Reference Quality Assessment Model of Enhanced Images With Big Data
Apr 18, 2019
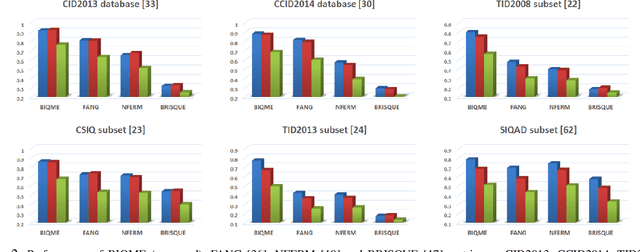
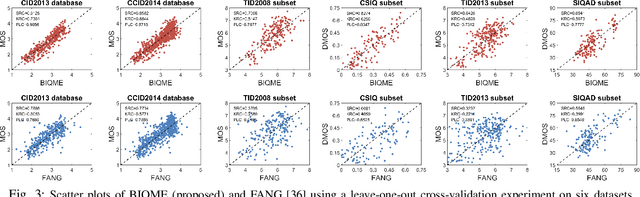

In this paper we investigate into the problem of image quality assessment (IQA) and enhancement via machine learning. This issue has long attracted a wide range of attention in computational intelligence and image processing communities, since, for many practical applications, e.g. object detection and recognition, raw images are usually needed to be appropriately enhanced to raise the visual quality (e.g. visibility and contrast). In fact, proper enhancement can noticeably improve the quality of input images, even better than originally captured images which are generally thought to be of the best quality. In this work, we present two most important contributions. The first contribution is to develop a new no-reference (NR) IQA model. Given an image, our quality measure first extracts 17 features through analysis of contrast, sharpness, brightness and more, and then yields a measre of visual quality using a regression module, which is learned with big-data training samples that are much bigger than the size of relevant image datasets. Results of experiments on nine datasets validate the superiority and efficiency of our blind metric compared with typical state-of-the-art full-, reduced- and no-reference IQA methods. The second contribution is that a robust image enhancement framework is established based on quality optimization. For an input image, by the guidance of the proposed NR-IQA measure, we conduct histogram modification to successively rectify image brightness and contrast to a proper level. Thorough tests demonstrate that our framework can well enhance natural images, low-contrast images, low-light images and dehazed images. The source code will be released at https://sites.google.com/site/guke198701/publications.