 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFolding-based compression of point cloud attributes
Paper and Code
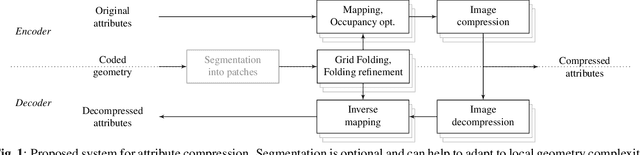

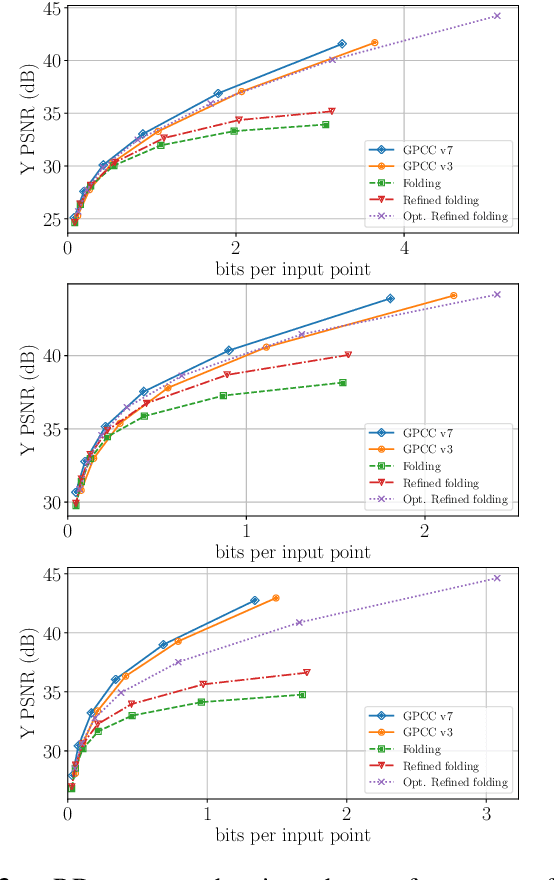
Existing techniques to compress point cloud attributes leverage either geometric or video-based compression tools. In this work, we explore a radically different approach inspired by recent advances in point cloud representation learning. A point cloud can be interpreted as a 2D manifold in a 3D space. As that, its attributes could be mapped onto a folded 2D grid; compressed through a conventional 2D image codec; and mapped back at the decoder side to recover attributes on 3D points. The folding operation is optimized by employing a deep neural network as a parametric folding function. As mapping is lossy in nature, we propose several strategies to refine it in such a way that attributes in 3D can be mapped to the 2D grid with minimal distortion. This approach can be flexibly applied to portions of point clouds in order to better adapt to local geometric complexity, and thus has a potential for being used as a tool in existing or future coding pipelines. Our preliminary results show that the proposed folding-based coding scheme can already reach performance similar to the latest MPEG GPCC codec.