 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Video Inpainting for Joint Headset Occlusion Removal and Face Reconstruction in Social XR
Aug 17, 2025Head-mounted displays (HMDs) are essential for experiencing extended reality (XR) environments and observing virtual content. However, they obscure the upper part of the user's face, complicating external video recording and significantly impacting social XR applications such as teleconferencing, where facial expressions and eye gaze details are crucial for creating an immersive experience. This study introduces a geometry-aware learning-based framework to jointly remove HMD occlusions and reconstruct complete 3D facial geometry from RGB frames captured from a single viewpoint. The method integrates a GAN-based video inpainting network, guided by dense facial landmarks and a single occlusion-free reference frame, to restore missing facial regions while preserving identity. Subsequently, a SynergyNet-based module regresses 3D Morphable Model (3DMM) parameters from the inpainted frames, enabling accurate 3D face reconstruction. Dense landmark optimization is incorporated throughout the pipeline to improve both the inpainting quality and the fidelity of the recovered geometry. Experimental results demonstrate that the proposed framework can successfully remove HMDs from RGB facial videos while maintaining facial identity and realism, producing photorealistic 3D face geometry outputs. Ablation studies further show that the framework remains robust across different landmark densities, with only minor quality degradation under sparse landmark configurations.
Real-Time Position-Aware View Synthesis from Single-View Input
Dec 18, 2024



Recent advancements in view synthesis have significantly enhanced immersive experiences across various computer graphics and multimedia applications, including telepresence, and entertainment. By enabling the generation of new perspectives from a single input view, view synthesis allows users to better perceive and interact with their environment. However, many state-of-the-art methods, while achieving high visual quality, face limitations in real-time performance, which makes them less suitable for live applications where low latency is critical. In this paper, we present a lightweight, position-aware network designed for real-time view synthesis from a single input image and a target camera pose. The proposed framework consists of a Position Aware Embedding, modeled with a multi-layer perceptron, which efficiently maps positional information from the target pose to generate high dimensional feature maps. These feature maps, along with the input image, are fed into a Rendering Network that merges features from dual encoder branches to resolve both high level semantics and low level details, producing a realistic new view of the scene. Experimental results demonstrate that our method achieves superior efficiency and visual quality compared to existing approaches, particularly in handling complex translational movements without explicit geometric operations like warping. This work marks a step toward enabling real-time view synthesis from a single image for live and interactive applications.
Adaptive Segmentation-Based Initialization for Steered Mixture of Experts Image Regression
Sep 16, 2024



Kernel image regression methods have shown to provide excellent efficiency in many image processing task, such as image and light-field compression, Gaussian Splatting, denoising and super-resolution. The estimation of parameters for these methods frequently employ gradient descent iterative optimization, which poses significant computational burden for many applications. In this paper, we introduce a novel adaptive segmentation-based initialization method targeted for optimizing Steered-Mixture-of Experts (SMoE) gating networks and Radial-Basis-Function (RBF) networks with steering kernels. The novel initialization method allocates kernels into pre-calculated image segments. The optimal number of kernels, kernel positions, and steering parameters are derived per segment in an iterative optimization and kernel sparsification procedure. The kernel information from "local" segments is then transferred into a "global" initialization, ready for use in iterative optimization of SMoE, RBF, and related kernel image regression methods. Results show that drastic objective and subjective quality improvements are achievable compared to widely used regular grid initialization, "state-of-the-art" K-Means initialization and previously introduced segmentation-based initialization methods, while also drastically improving the sparsity of the regression models. For same quality, the novel initialization results in models with around 50% reduction of kernels. In addition, a significant reduction of convergence time is achieved, with overall run-time savings of up to 50%. The segmentation-based initialization strategy itself admits heavy parallel computation; in theory, it may be divided into as many tasks as there are segments in the images. By accessing only four parallel GPUs, run-time savings of already 50% for initialization are achievable.
Towards Realistic Landmark-Guided Facial Video Inpainting Based on GANs
Feb 14, 2024



Facial video inpainting plays a crucial role in a wide range of applications, including but not limited to the removal of obstructions in video conferencing and telemedicine, enhancement of facial expression analysis, privacy protection, integration of graphical overlays, and virtual makeup. This domain presents serious challenges due to the intricate nature of facial features and the inherent human familiarity with faces, heightening the need for accurate and persuasive completions. In addressing challenges specifically related to occlusion removal in this context, our focus is on the progressive task of generating complete images from facial data covered by masks, ensuring both spatial and temporal coherence. Our study introduces a network designed for expression-based video inpainting, employing generative adversarial networks (GANs) to handle static and moving occlusions across all frames. By utilizing facial landmarks and an occlusion-free reference image, our model maintains the user's identity consistently across frames. We further enhance emotional preservation through a customized facial expression recognition (FER) loss function, ensuring detailed inpainted outputs. Our proposed framework exhibits proficiency in eliminating occlusions from facial videos in an adaptive form, whether appearing static or dynamic on the frames, while providing realistic and coherent results.
Headset: Human emotion awareness under partial occlusions multimodal dataset
Feb 14, 2024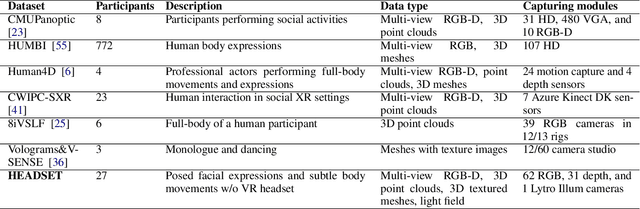

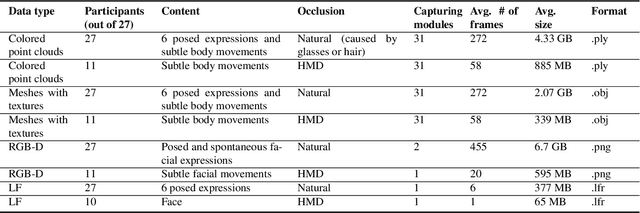

The volumetric representation of human interactions is one of the fundamental domains in the development of immersive media productions and telecommunication applications. Particularly in the context of the rapid advancement of Extended Reality (XR) applications, this volumetric data has proven to be an essential technology for future XR elaboration. In this work, we present a new multimodal database to help advance the development of immersive technologies. Our proposed database provides ethically compliant and diverse volumetric data, in particular 27 participants displaying posed facial expressions and subtle body movements while speaking, plus 11 participants wearing head-mounted displays (HMDs). The recording system consists of a volumetric capture (VoCap) studio, including 31 synchronized modules with 62 RGB cameras and 31 depth cameras. In addition to textured meshes, point clouds, and multi-view RGB-D data, we use one Lytro Illum camera for providing light field (LF) data simultaneously. Finally, we also provide an evaluation of our dataset employment with regard to the tasks of facial expression classification, HMDs removal, and point cloud reconstruction. The dataset can be helpful in the evaluation and performance testing of various XR algorithms, including but not limited to facial expression recognition and reconstruction, facial reenactment, and volumetric video. HEADSET and its all associated raw data and license agreement will be publicly available for research purposes.
Expression-aware video inpainting for HMD removal in XR applications
Jan 25, 2024
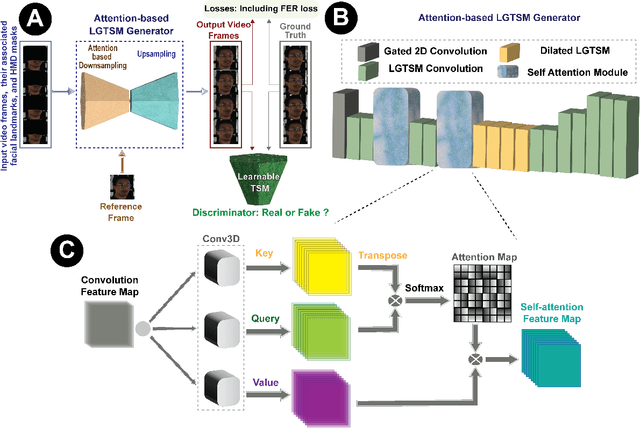
Head-mounted displays (HMDs) serve as indispensable devices for observing extended reality (XR) environments and virtual content. However, HMDs present an obstacle to external recording techniques as they block the upper face of the user. This limitation significantly affects social XR applications, specifically teleconferencing, where facial features and eye gaze information play a vital role in creating an immersive user experience. In this study, we propose a new network for expression-aware video inpainting for HMD removal (EVI-HRnet) based on generative adversarial networks (GANs). Our model effectively fills in missing information with regard to facial landmarks and a single occlusion-free reference image of the user. The framework and its components ensure the preservation of the user's identity across frames using the reference frame. To further improve the level of realism of the inpainted output, we introduce a novel facial expression recognition (FER) loss function for emotion preservation. Our results demonstrate the remarkable capability of the proposed framework to remove HMDs from facial videos while maintaining the subject's facial expression and identity. Moreover, the outputs exhibit temporal consistency along the inpainted frames. This lightweight framework presents a practical approach for HMD occlusion removal, with the potential to enhance various collaborative XR applications without the need for additional hardware.