 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Segmentation-Based Initialization for Steered Mixture of Experts Image Regression
Sep 16, 2024



Kernel image regression methods have shown to provide excellent efficiency in many image processing task, such as image and light-field compression, Gaussian Splatting, denoising and super-resolution. The estimation of parameters for these methods frequently employ gradient descent iterative optimization, which poses significant computational burden for many applications. In this paper, we introduce a novel adaptive segmentation-based initialization method targeted for optimizing Steered-Mixture-of Experts (SMoE) gating networks and Radial-Basis-Function (RBF) networks with steering kernels. The novel initialization method allocates kernels into pre-calculated image segments. The optimal number of kernels, kernel positions, and steering parameters are derived per segment in an iterative optimization and kernel sparsification procedure. The kernel information from "local" segments is then transferred into a "global" initialization, ready for use in iterative optimization of SMoE, RBF, and related kernel image regression methods. Results show that drastic objective and subjective quality improvements are achievable compared to widely used regular grid initialization, "state-of-the-art" K-Means initialization and previously introduced segmentation-based initialization methods, while also drastically improving the sparsity of the regression models. For same quality, the novel initialization results in models with around 50% reduction of kernels. In addition, a significant reduction of convergence time is achieved, with overall run-time savings of up to 50%. The segmentation-based initialization strategy itself admits heavy parallel computation; in theory, it may be divided into as many tasks as there are segments in the images. By accessing only four parallel GPUs, run-time savings of already 50% for initialization are achievable.
Denoising OCT Images Using Steered Mixture of Experts with Multi-Model Inference
Feb 24, 2024In Optical Coherence Tomography (OCT), speckle noise significantly hampers image quality, affecting diagnostic accuracy. Current methods, including traditional filtering and deep learning techniques, have limitations in noise reduction and detail preservation. Addressing these challenges, this study introduces a novel denoising algorithm, Block-Matching Steered-Mixture of Experts with Multi-Model Inference and Autoencoder (BM-SMoE-AE). This method combines block-matched implementation of the SMoE algorithm with an enhanced autoencoder architecture, offering efficient speckle noise reduction while retaining critical image details. Our method stands out by providing improved edge definition and reduced processing time. Comparative analysis with existing denoising techniques demonstrates the superior performance of BM-SMoE-AE in maintaining image integrity and enhancing OCT image usability for medical diagnostics.
Steered Mixture-of-Experts Autoencoder Design for Real-Time Image Modelling and Denoising
May 05, 2023Research in the past years introduced Steered Mixture-of-Experts (SMoE) as a framework to form sparse, edge-aware models for 2D- and higher dimensional pixel data, applicable to compression, denoising, and beyond, and capable to compete with state-of-the-art compression methods. To circumvent the computationally demanding, iterative optimization method used in prior works an autoencoder design is introduced that reduces the run-time drastically while simultaneously improving reconstruction quality for block-based SMoE approaches. Coupling a deep encoder network with a shallow, parameter-free SMoE decoder enforces an efficent and explainable latent representation. Our initial work on the autoencoder design presented a simple model, with limited applicability to compression and beyond. In this paper, we build on the foundation of the first autoencoder design and improve the reconstruction quality by expanding it to models of higher complexity and different block sizes. Furthermore, we improve the noise robustness of the autoencoder for SMoE denoising applications. Our results reveal that the newly adapted autoencoders allow ultra-fast estimation of parameters for complex SMoE models with excellent reconstruction quality, both for noise free input and under severe noise. This enables the SMoE image model framework for a wide range of image processing applications, including compression, noise reduction, and super-resolution.
Steered Mixture of Experts Regression for Image Denoising with Multi-Model-Inference
Mar 30, 2023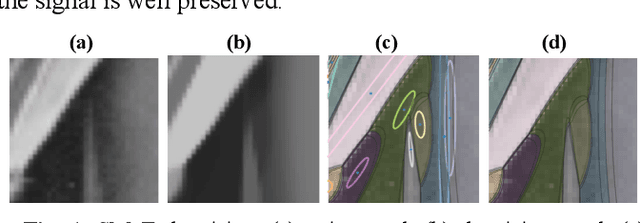
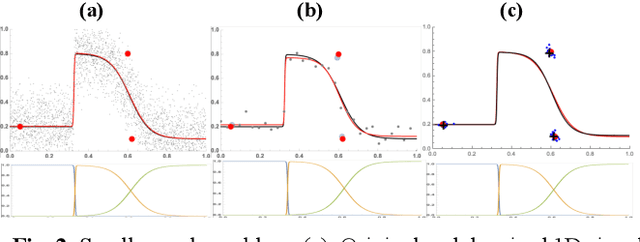
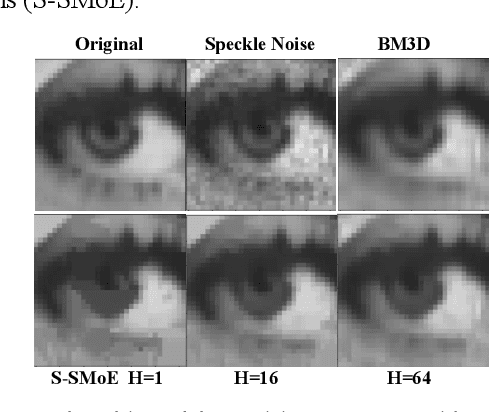
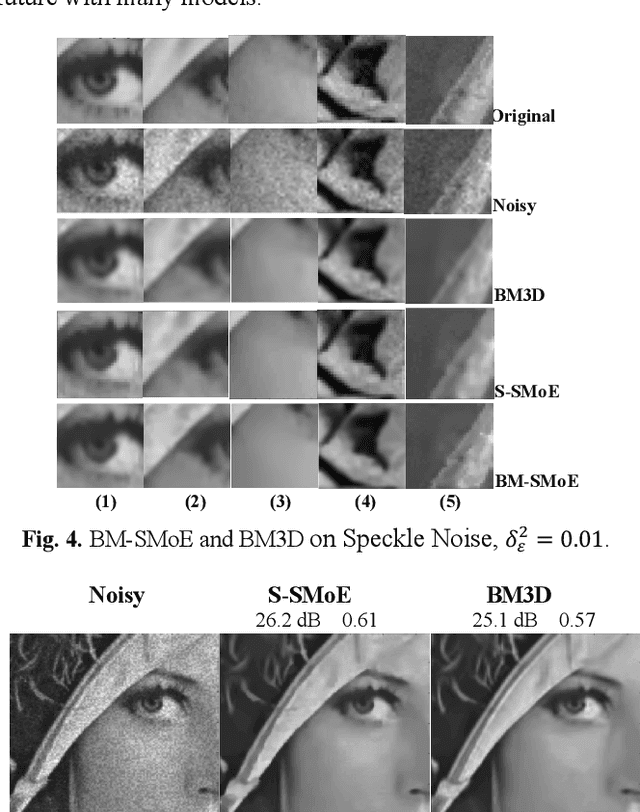
In this paper we introduce a novel block-based regression strategy for image denoising based on edge-aware Steered-Mixture-of-Experts (SMoE) models. SMoEs provide very sparse image representations, able to model sharp edges as well as smooth transitions in images efficiently with few parameters. A multi-model inference strategy is developed that improves significantly the denoising capacity of single SMoE models. We show that the important edge reconstruction properties of SMoEs are well preserved, even when many models are fused under severe noise. We investigate model-inference from local neighborhood blocks as well as from distant blocks using block-matching as in BM3D. Our initial results indicate that SMoE multi-model regression can provide promising results compared to state-of-the-art BM3D with excellent edge quality.
Sparse Video Representation Using Steered Mixture-of-Experts With Global Motion Compensation
Sep 13, 2022


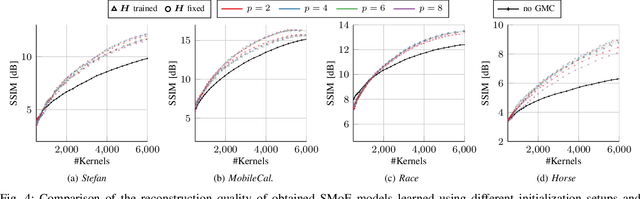
Steered-Mixtures-of Experts (SMoE) present a unified framework for sparse representation and compression of image data with arbitrary dimensionality. Recent work has shown great improvements in the performance of such models for image and light-field representation. However, for the case of videos the straight-forward application yields limited success as the SMoE framework leads to a piece-wise linear representation of the underlying imagery which is disrupted by nonlinear motion. We incorporate a global motion model into the SMoE framework which allows for higher temporal steering of the kernels. This drastically increases its capabilities to exploit correlations between adjacent frames by only adding 2 to 8 motion parameters per frame to the model but decreasing the required amount of kernels on average by 54.25%, respectively, while maintaining the same reconstruction quality yielding higher compression gains.
Edge-Aware Autoencoder Design for Real-Time Mixture-of-Experts Image Compression
Jul 25, 2022
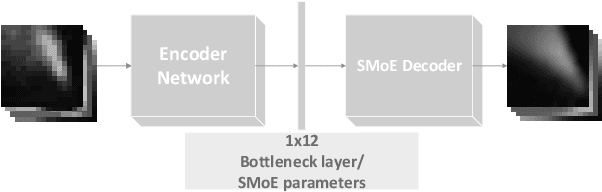


Steered-Mixtures-of-Experts (SMoE) models provide sparse, edge-aware representations, applicable to many use-cases in image processing. This includes denoising, super-resolution and compression of 2D- and higher dimensional pixel data. Recent works for image compression indicate that compression of images based on SMoE models can provide competitive performance to the state-of-the-art. Unfortunately, the iterative model-building process at the encoder comes with excessive computational demands. In this paper we introduce a novel edge-aware Autoencoder (AE) strategy designed to avoid the time-consuming iterative optimization of SMoE models. This is done by directly mapping pixel blocks to model parameters for compression, in spirit similar to recent works on "unfolding" of algorithms, while maintaining full compatibility to the established SMoE framework. With our plug-in AE encoder, we achieve a quantum-leap in performance with encoder run-time savings by a factor of 500 to 1000 with even improved image reconstruction quality. For image compression the plug-in AE encoder has real-time properties and improves RD-performance compared to our previous works.
Accelerated Deep Lossless Image Coding with Unified Paralleleized GPU Coding Architecture
Jul 11, 2022
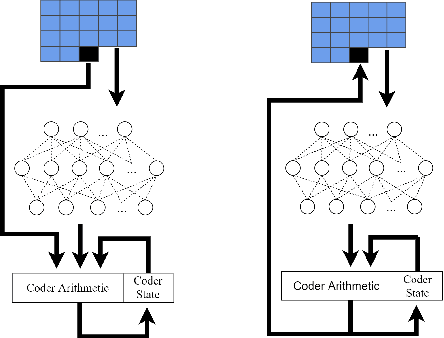
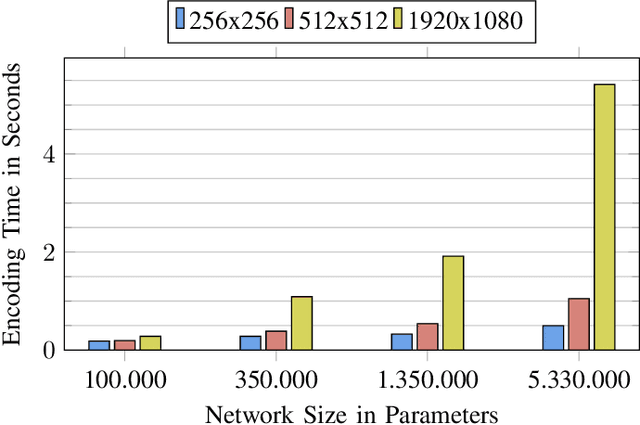
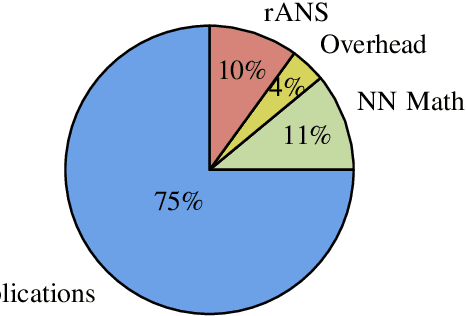
We propose Deep Lossless Image Coding (DLIC), a full resolution learned lossless image compression algorithm. Our algorithm is based on a neural network combined with an entropy encoder. The neural network performs a density estimation on each pixel of the source image. The density estimation is then used to code the target pixel, beating FLIF in terms of compression rate. Similar approaches have been attempted. However, long run times make them unfeasible for real world applications. We introduce a parallelized GPU based implementation, allowing for encoding and decoding of grayscale, 8-bit images in less than one second. Because DLIC uses a neural network to estimate the probabilities used for the entropy coder, DLIC can be trained on domain specific image data. We demonstrate this capability by adapting and training DLIC with Magnet Resonance Imaging (MRI) images.
Video-based Bottleneck Detection utilizing Lagrangian Dynamics in Crowded Scenes
Aug 21, 2019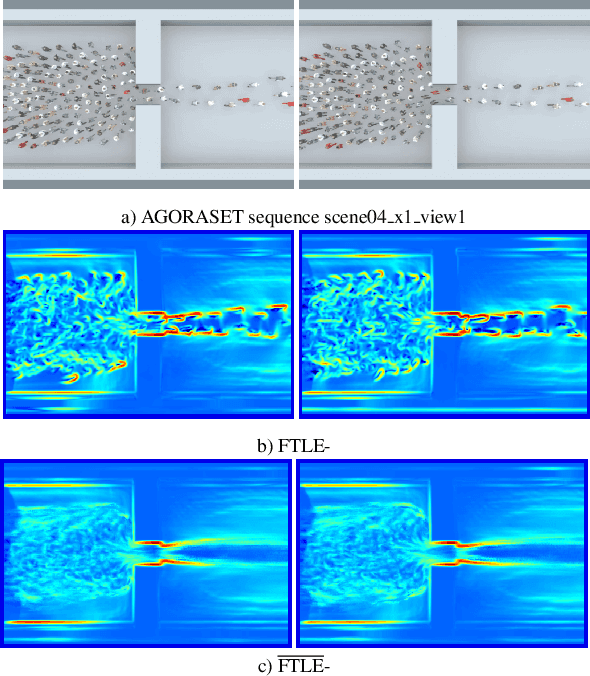


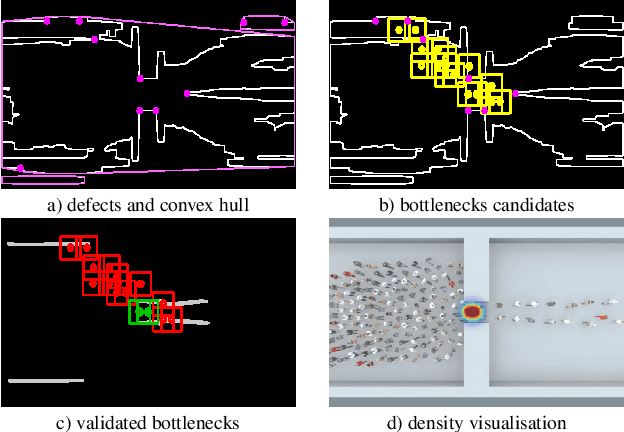
Avoiding bottleneck situations in crowds is critical for the safety and comfort of people at large events or in public transportation. Based on the work of Lagrangian motion analysis we propose a novel video-based bottleneckdetector by identifying characteristic stowage patterns in crowd-movements captured by optical flow fields. The Lagrangian framework allows to assess complex timedependent crowd-motion dynamics at large temporal scales near the bottleneck by two dimensional Lagrangian fields. In particular we propose long-term temporal filtered Finite Time Lyapunov Exponents (FTLE) fields that provide towards a more global segmentation of the crowd movements and allows to capture its deformations when a crowd is passing a bottleneck. Finally, these deformations are used for an automatic spatio-temporal detection of such situations. The performance of the proposed approach is shown in extensive evaluations on the existing J\"ulich and AGORASET datasets, that we have updated with ground truth data for spatio-temporal bottleneck analysis.
Optical Flow Dataset and Benchmark for Visual Crowd Analysis
Nov 17, 2018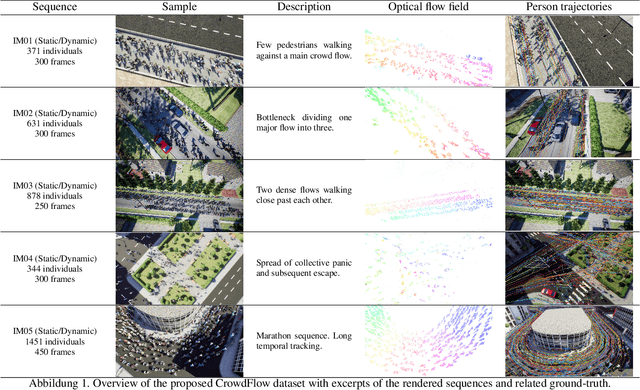
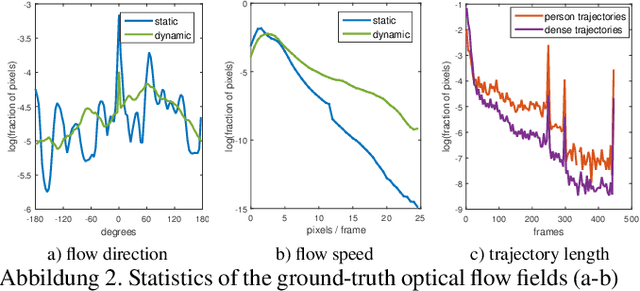
The performance of optical flow algorithms greatly depends on the specifics of the content and the application for which it is used. Existing and well established optical flow datasets are limited to rather particular contents from which none is close to crowd behavior analysis; whereas such applications heavily utilize optical flow. We introduce a new optical flow dataset exploiting the possibilities of a recent video engine to generate sequences with ground-truth optical flow for large crowds in different scenarios. We break with the development of the last decade of introducing ever increasing displacements to pose new difficulties. Instead we focus on real-world surveillance scenarios where numerous small, partly independent, non rigidly moving objects observed over a long temporal range pose a challenge. By evaluating different optical flow algorithms, we find that results of established datasets can not be transferred to these new challenges. In exhaustive experiments we are able to provide new insight into optical flow for crowd analysis. Finally, the results have been validated on the real-world UCF crowd tracking benchmark while achieving competitive results compared to more sophisticated state-of-the-art crowd tracking approaches.