 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Video Representation Using Steered Mixture-of-Experts With Global Motion Compensation
Paper and Code
Sep 13, 2022


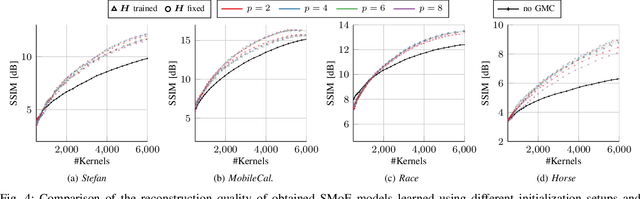
Steered-Mixtures-of Experts (SMoE) present a unified framework for sparse representation and compression of image data with arbitrary dimensionality. Recent work has shown great improvements in the performance of such models for image and light-field representation. However, for the case of videos the straight-forward application yields limited success as the SMoE framework leads to a piece-wise linear representation of the underlying imagery which is disrupted by nonlinear motion. We incorporate a global motion model into the SMoE framework which allows for higher temporal steering of the kernels. This drastically increases its capabilities to exploit correlations between adjacent frames by only adding 2 to 8 motion parameters per frame to the model but decreasing the required amount of kernels on average by 54.25%, respectively, while maintaining the same reconstruction quality yielding higher compression gains.