 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiGS: Bidirectional Gaussian Primitives for Relightable 3D Gaussian Splatting
Aug 23, 2024



We present Bidirectional Gaussian Primitives, an image-based novel view synthesis technique designed to represent and render 3D objects with surface and volumetric materials under dynamic illumination. Our approach integrates light intrinsic decomposition into the Gaussian splatting framework, enabling real-time relighting of 3D objects. To unify surface and volumetric material within a cohesive appearance model, we adopt a light- and view-dependent scattering representation via bidirectional spherical harmonics. Our model does not use a specific surface normal-related reflectance function, making it more compatible with volumetric representations like Gaussian splatting, where the normals are undefined. We demonstrate our method by reconstructing and rendering objects with complex materials. Using One-Light-At-a-Time (OLAT) data as input, we can reproduce photorealistic appearances under novel lighting conditions in real time.
Hierarchical-level rain image generative model based on GAN
Sep 06, 2023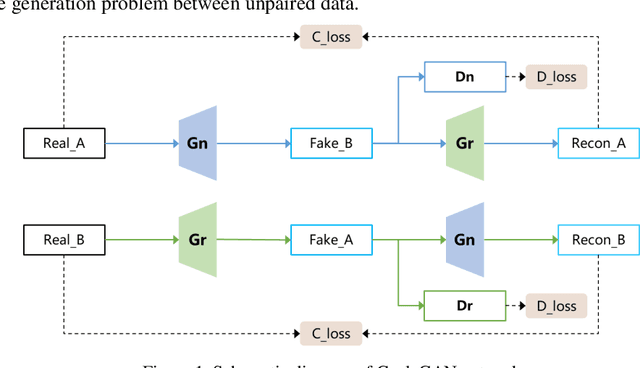

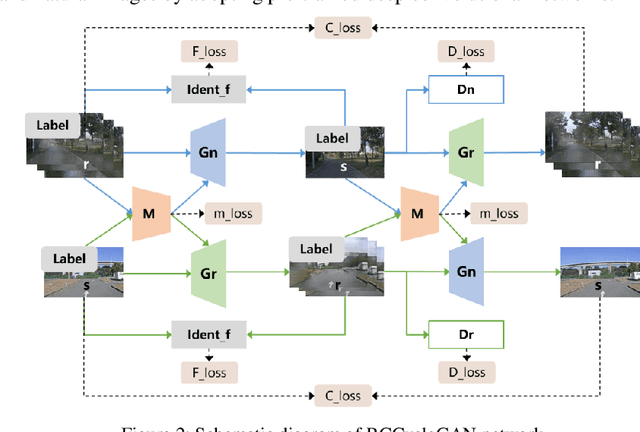
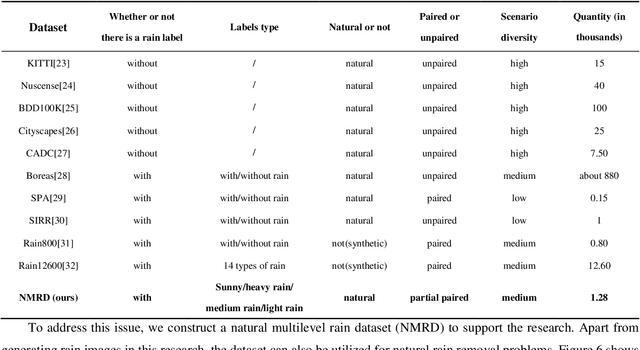
Autonomous vehicles are exposed to various weather during operation, which is likely to trigger the performance limitations of the perception system, leading to the safety of the intended functionality (SOTIF) problems. To efficiently generate data for testing the performance of visual perception algorithms under various weather conditions, a hierarchical-level rain image generative model, rain conditional CycleGAN (RCCycleGAN), is constructed. RCCycleGAN is based on the generative adversarial network (GAN) and can generate images of light, medium, and heavy rain. Different rain intensities are introduced as labels in conditional GAN (CGAN). Meanwhile, the model structure is optimized and the training strategy is adjusted to alleviate the problem of mode collapse. In addition, natural rain images of different intensities are collected and processed for model training and validation. Compared with the two baseline models, CycleGAN and DerainCycleGAN, the peak signal-to-noise ratio (PSNR) of RCCycleGAN on the test dataset is improved by 2.58 dB and 0.74 dB, and the structural similarity (SSIM) is improved by 18% and 8%, respectively. The ablation experiments are also carried out to validate the effectiveness of the model tuning.
Smoothed $f$-Divergence Distributionally Robust Optimization: Exponential Rate Efficiency and Complexity-Free Calibration
Jun 24, 2023

In data-driven optimization, sample average approximation is known to suffer from the so-called optimizer's curse that causes optimistic bias in evaluating the solution performance. This can be tackled by adding a "margin" to the estimated objective value, or via distributionally robust optimization (DRO), a fast-growing approach based on worst-case analysis, which gives a protective bound on the attained objective value. However, in all these existing approaches, a statistically guaranteed bound on the true solution performance either requires restrictive conditions and knowledge on the objective function complexity, or otherwise exhibits an over-conservative rate that depends on the distribution dimension. We argue that a special type of DRO offers strong theoretical advantages in regard to these challenges: It attains a statistical bound on the true solution performance that is the tightest possible in terms of exponential decay rate, for a wide class of objective functions that notably does not hinge on function complexity. Correspondingly, its calibration also does not require any complexity information. This DRO uses an ambiguity set based on a KL-divergence smoothed by the Wasserstein or Levy-Prokhorov distance via a suitable distance optimization. Computationally, we also show that such a DRO, and its generalized version using smoothed $f$-divergence, is not much harder than standard DRO problems using the $f$-divergence or Wasserstein distance, thus supporting the strengths of such DRO as both statistically optimal and computationally viable.
Test Against High-Dimensional Uncertainties: Accelerated Evaluation of Autonomous Vehicles with Deep Importance Sampling
Apr 06, 2022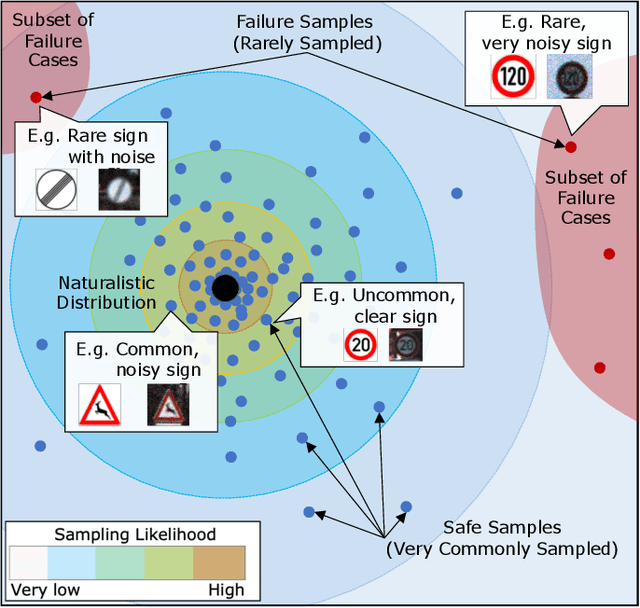


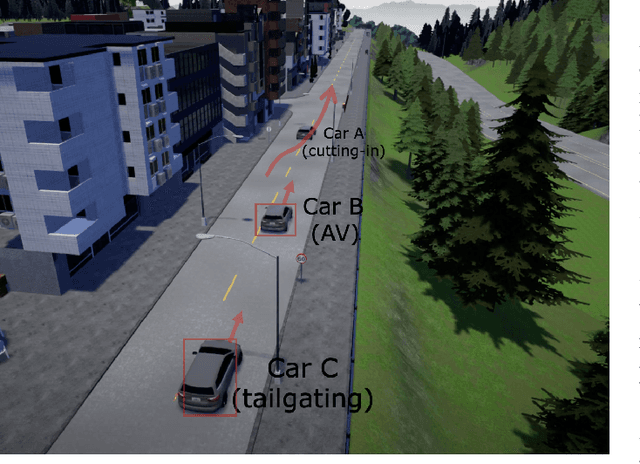
Evaluating the performance of autonomous vehicles (AV) and their complex subsystems to high precision under naturalistic circumstances remains a challenge, especially when failure or dangerous cases are rare. Rarity does not only require an enormous sample size for a naive method to achieve high confidence estimation, but it also causes dangerous underestimation of the true failure rate and it is extremely hard to detect. Meanwhile, the state-of-the-art approach that comes with a correctness guarantee can only compute an upper bound for the failure rate under certain conditions, which could limit its practical uses. In this work, we present Deep Importance Sampling (Deep IS) framework that utilizes a deep neural network to obtain an efficient IS that is on par with the state-of-the-art, capable of reducing the required sample size 43 times smaller than the naive sampling method to achieve 10% relative error and while producing an estimate that is much less conservative. Our high-dimensional experiment estimating the misclassification rate of one of the state-of-the-art traffic sign classifiers further reveals that this efficiency still holds true even when the target is very small, achieving over 600 times efficiency boost. This highlights the potential of Deep IS in providing a precise estimate even against high-dimensional uncertainties.