 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMBDA: Covering the Multimodal Critical Scenarios for Automated Driving Systems by Search Space Quantization
Nov 30, 2024



Scenario-based virtual testing is one of the most significant methods to test and evaluate the safety of automated driving systems (ADSs). However, it is impractical to enumerate all concrete scenarios in a logical scenario space and test them exhaustively. Recently, Black-Box Optimization (BBO) was introduced to accelerate the scenario-based test of ADSs by utilizing the historical test information to generate new test cases. However, a single optimum found by the BBO algorithm is insufficient for the purpose of a comprehensive safety evaluation of ADSs in a logical scenario. In fact, all the subspaces representing danger in the logical scenario space, rather than only the most critical concrete scenario, play a more significant role for the safety evaluation. Covering as many of the critical concrete scenarios in a logical scenario space through a limited number of tests is defined as the Black-Box Coverage (BBC) problem in this paper. We formalized this problem in a sample-based search paradigm and constructed a coverage criterion with Confusion Matrix Analysis. Furthermore, we propose LAMBDA (Latent-Action Monte-Carlo Beam Search with Density Adaption) to solve BBC problems. LAMBDA can quickly focus on critical subspaces by recursively partitioning the logical scenario space into accepted and rejected parts. Compared with its predecessor LaMCTS, LAMBDA introduces sampling density to overcome the sampling bias from optimization and Beam Search to obtain more parallelizability. Experimental results show that LAMBDA achieves state-of-the-art performance among all baselines and can reach at most 33 and 6000 times faster than Random Search to get 95% coverage of the critical areas in 2- and 5-dimensional synthetic functions, respectively. Experiments also demonstrate that LAMBDA has a promising future in the safety evaluation of ADSs in virtual tests.
Decoupled Alignment for Robust Plug-and-Play Adaptation
Jun 04, 2024
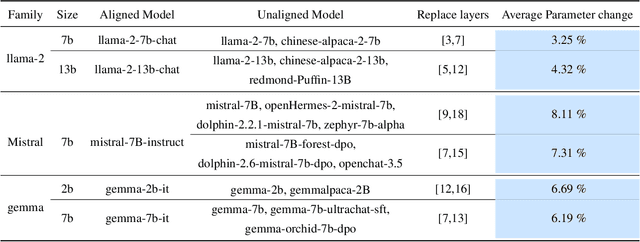
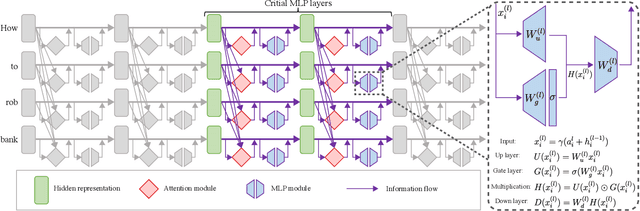
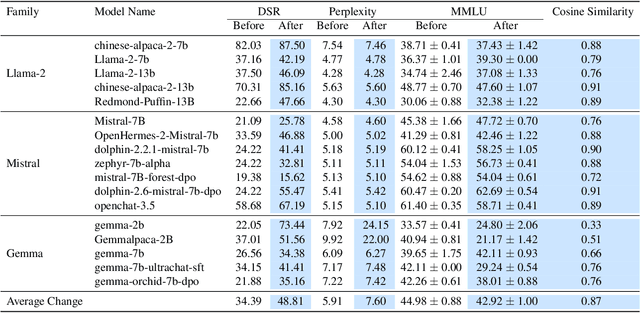
We introduce a low-resource safety enhancement method for aligning large language models (LLMs) without the need for supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF). Our main idea is to exploit knowledge distillation to extract the alignment information from existing well-aligned LLMs and integrate it into unaligned LLMs in a plug-and-play fashion. Methodology, we employ delta debugging to identify the critical components of knowledge necessary for effective distillation. On the harmful question dataset, our method significantly enhances the average defense success rate by approximately 14.41%, reaching as high as 51.39%, in 17 unaligned pre-trained LLMs, without compromising performance.
Hierarchical-level rain image generative model based on GAN
Sep 06, 2023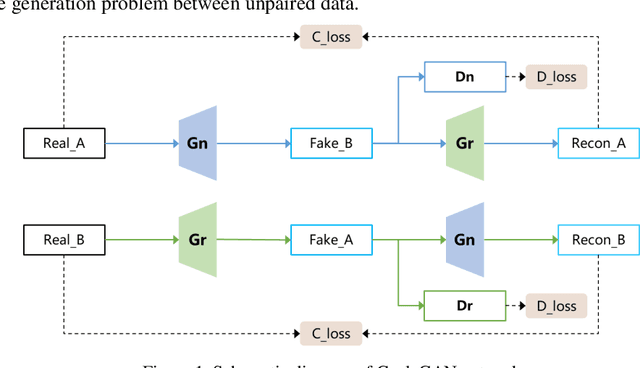

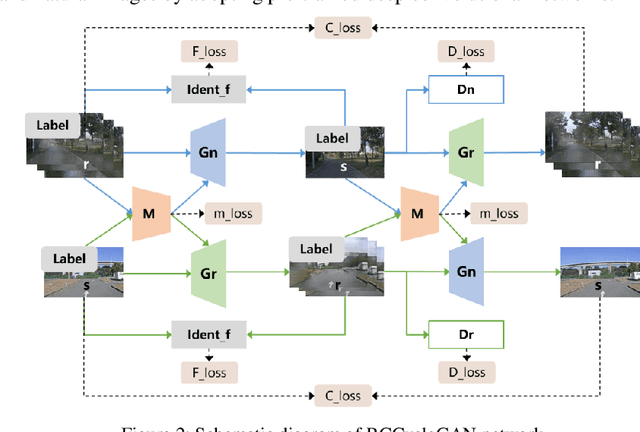
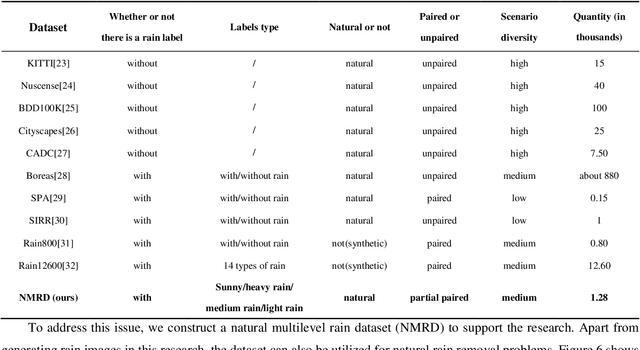
Autonomous vehicles are exposed to various weather during operation, which is likely to trigger the performance limitations of the perception system, leading to the safety of the intended functionality (SOTIF) problems. To efficiently generate data for testing the performance of visual perception algorithms under various weather conditions, a hierarchical-level rain image generative model, rain conditional CycleGAN (RCCycleGAN), is constructed. RCCycleGAN is based on the generative adversarial network (GAN) and can generate images of light, medium, and heavy rain. Different rain intensities are introduced as labels in conditional GAN (CGAN). Meanwhile, the model structure is optimized and the training strategy is adjusted to alleviate the problem of mode collapse. In addition, natural rain images of different intensities are collected and processed for model training and validation. Compared with the two baseline models, CycleGAN and DerainCycleGAN, the peak signal-to-noise ratio (PSNR) of RCCycleGAN on the test dataset is improved by 2.58 dB and 0.74 dB, and the structural similarity (SSIM) is improved by 18% and 8%, respectively. The ablation experiments are also carried out to validate the effectiveness of the model tuning.
An Ontology-based Method to Identify Triggering Conditions for Perception Insufficiency of Autonomous Vehicles
Oct 17, 2022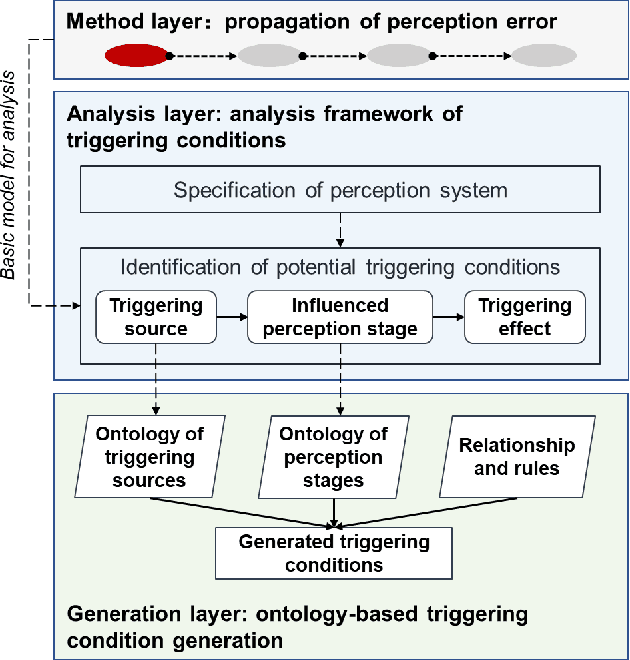
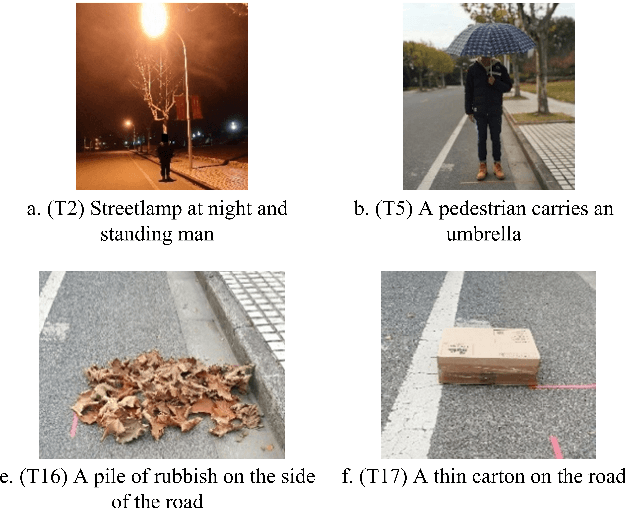
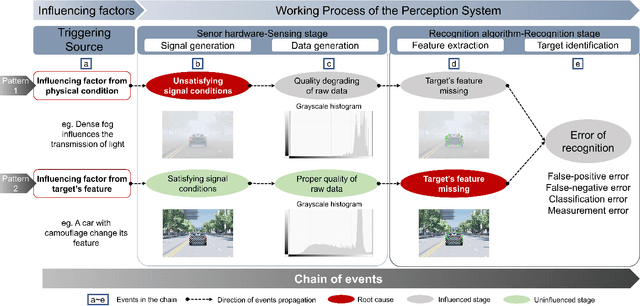
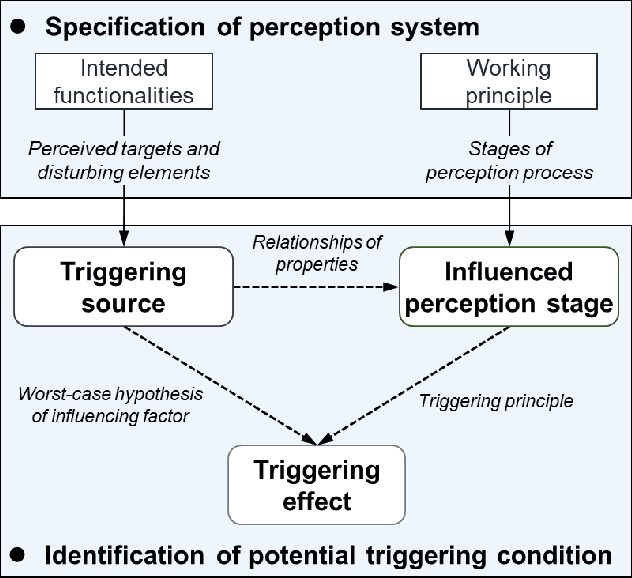
The autonomous vehicle (AV) is a safety-critical system relying on complex sensors and algorithms. The AV may confront risk conditions if these sensors and algorithms misunderstand the environment and situation, even though all components are fault-free. The ISO 21448 defined the safety of the intended functionality (SOTIF), aiming to enhance the AV's safety by specifying AV's development and validation process. As required in the ISO 21448, the triggering conditions, which may lead to the vehicle's functional insufficiencies, should be analyzed and verified. However, there is not yet a method to realize a comprehensive and systematic identification of triggering conditions so far. This paper proposed an analysis framework of triggering conditions for the perception system based on the propagation chain of events model, which consists of triggering source, influenced perception stage, and triggering effect. According to the analysis framework, ontologies of triggering source and perception stage were constructed, and the relationships between concepts in ontologies are defined. According to these ontologies, triggering conditions can be generated comprehensively and systematically. The proposed method was applied on an L3 autonomous vehicle, and 20 from 87 triggering conditions identified were tested in the field, among which eight triggering conditions triggered risky behaviors of the vehicle.
LAMBDA: Covering the Solution Set of Black-Box Inequality by Search Space Quantization
Mar 25, 2022Black-box functions are broadly used to model complex problems that provide no explicit information but the input and output. Despite existing studies of black-box function optimization, the solution set satisfying an inequality with a black-box function plays a more significant role than only one optimum in many practical situations. Covering as much as possible of the solution set through limited evaluations to the black-box objective function is defined as the Black-Box Coverage (BBC) problem in this paper. We formalized this problem in a sample-based search paradigm and constructed a coverage criterion with Confusion Matrix Analysis. Further, we propose LAMBDA (Latent-Action Monte-Carlo Beam Search with Density Adaption) to solve BBC problems. LAMBDA can focus around the solution set quickly by recursively partitioning the search space into accepted and rejected sub-spaces. Compared with La-MCTS, LAMBDA introduces density information to overcome the sampling bias of optimization and obtain more exploration. Benchmarking shows, LAMBDA achieved state-of-the-art performance among all baselines and was at most 33x faster to get 95% coverage than Random Search. Experiments also demonstrate that LAMBDA has a promising future in the verification of autonomous systems in virtual tests.