 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning in an expectation-maximisation framework for nowcasting
Dec 08, 2025


Decision making often occurs in the presence of incomplete information, leading to the under- or overestimation of risk. Leveraging the observable information to learn the complete information is called nowcasting. In practice, incomplete information is often a consequence of reporting or observation delays. In this paper, we propose an expectation-maximisation (EM) framework for nowcasting that uses machine learning techniques to model both the occurrence as well as the reporting process of events. We allow for the inclusion of covariate information specific to the occurrence and reporting periods as well as characteristics related to the entity for which events occurred. We demonstrate how the maximisation step and the information flow between EM iterations can be tailored to leverage the predictive power of neural networks and (extreme) gradient boosting machines (XGBoost). With simulation experiments, we show that we can effectively model both the occurrence and reporting of events when dealing with high-dimensional covariate information. In the presence of non-linear effects, we show that our methodology outperforms existing EM-based nowcasting frameworks that use generalised linear models in the maximisation step. Finally, we apply the framework to the reporting of Argentinian Covid-19 cases, where the XGBoost-based approach again is most performant.
Reducing the dimensionality and granularity in hierarchical categorical variables
Mar 06, 2024



Hierarchical categorical variables often exhibit many levels (high granularity) and many classes within each level (high dimensionality). This may cause overfitting and estimation issues when including such covariates in a predictive model. In current literature, a hierarchical covariate is often incorporated via nested random effects. However, this does not facilitate the assumption of classes having the same effect on the response variable. In this paper, we propose a methodology to obtain a reduced representation of a hierarchical categorical variable. We show how entity embedding can be applied in a hierarchical setting. Subsequently, we propose a top-down clustering algorithm which leverages the information encoded in the embeddings to reduce both the within-level dimensionality as well as the overall granularity of the hierarchical categorical variable. In simulation experiments, we show that our methodology can effectively approximate the true underlying structure of a hierarchical covariate in terms of the effect on a response variable, and find that incorporating the reduced hierarchy improves model fit. We apply our methodology on a real dataset and find that the reduced hierarchy is an improvement over the original hierarchical structure and reduced structures proposed in the literature.
Selective inference using randomized group lasso estimators for general models
Jun 24, 2023Selective inference methods are developed for group lasso estimators for use with a wide class of distributions and loss functions. The method includes the use of exponential family distributions, as well as quasi-likelihood modeling for overdispersed count data, for example, and allows for categorical or grouped covariates as well as continuous covariates. A randomized group-regularized optimization problem is studied. The added randomization allows us to construct a post-selection likelihood which we show to be adequate for selective inference when conditioning on the event of the selection of the grouped covariates. This likelihood also provides a selective point estimator, accounting for the selection by the group lasso. Confidence regions for the regression parameters in the selected model take the form of Wald-type regions and are shown to have bounded volume. The selective inference method for grouped lasso is illustrated on data from the national health and nutrition examination survey while simulations showcase its behaviour and favorable comparison with other methods.
Detangling robustness in high dimensions: composite versus model-averaged estimation
Jun 12, 2020


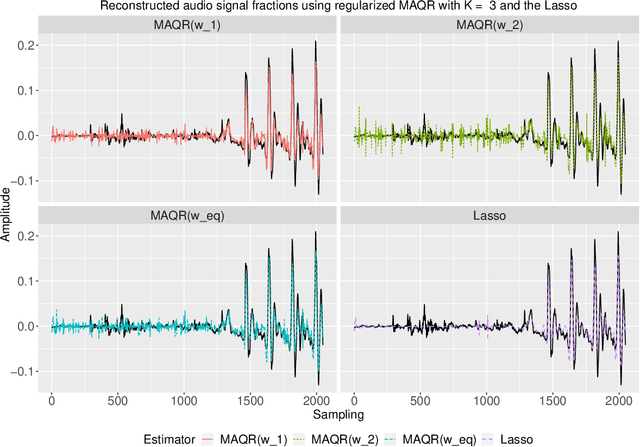
Robust methods, though ubiquitous in practice, are yet to be fully understood in the context of regularized estimation and high dimensions. Even simple questions become challenging very quickly. For example, classical statistical theory identifies equivalence between model-averaged and composite quantile estimation. However, little to nothing is known about such equivalence between methods that encourage sparsity. This paper provides a toolbox to further study robustness in these settings and focuses on prediction. In particular, we study optimally weighted model-averaged as well as composite $l_1$-regularized estimation. Optimal weights are determined by minimizing the asymptotic mean squared error. This approach incorporates the effects of regularization, without the assumption of perfect selection, as is often used in practice. Such weights are then optimal for prediction quality. Through an extensive simulation study, we show that no single method systematically outperforms others. We find, however, that model-averaged and composite quantile estimators often outperform least-squares methods, even in the case of Gaussian model noise. Real data application witnesses the method's practical use through the reconstruction of compressed audio signals.
Fixed effects testing in high-dimensional linear mixed models
Aug 14, 2017


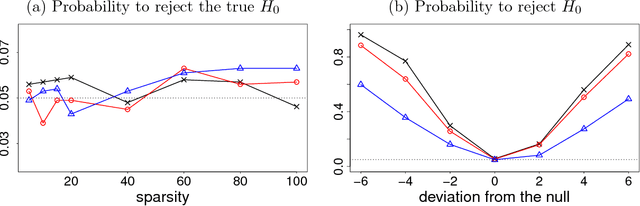
Many scientific and engineering challenges -- ranging from pharmacokinetic drug dosage allocation and personalized medicine to marketing mix (4Ps) recommendations -- require an understanding of the unobserved heterogeneity in order to develop the best decision making-processes. In this paper, we develop a hypothesis test and the corresponding p-value for testing for the significance of the homogeneous structure in linear mixed models. A robust matching moment construction is used for creating a test that adapts to the size of the model sparsity. When unobserved heterogeneity at a cluster level is constant, we show that our test is both consistent and unbiased even when the dimension of the model is extremely high. Our theoretical results rely on a new family of adaptive sparse estimators of the fixed effects that do not require consistent estimation of the random effects. Moreover, our inference results do not require consistent model selection. We showcase that moment matching can be extended to nonlinear mixed effects models and to generalized linear mixed effects models. In numerical and real data experiments, we find that the developed method is extremely accurate, that it adapts to the size of the underlying model and is decidedly powerful in the presence of irrelevant covariates.