 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning in an expectation-maximisation framework for nowcasting
Dec 08, 2025

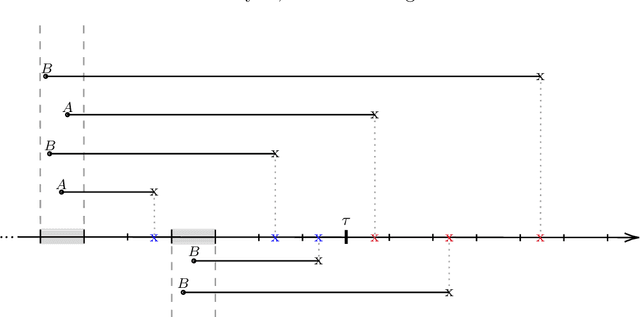

Decision making often occurs in the presence of incomplete information, leading to the under- or overestimation of risk. Leveraging the observable information to learn the complete information is called nowcasting. In practice, incomplete information is often a consequence of reporting or observation delays. In this paper, we propose an expectation-maximisation (EM) framework for nowcasting that uses machine learning techniques to model both the occurrence as well as the reporting process of events. We allow for the inclusion of covariate information specific to the occurrence and reporting periods as well as characteristics related to the entity for which events occurred. We demonstrate how the maximisation step and the information flow between EM iterations can be tailored to leverage the predictive power of neural networks and (extreme) gradient boosting machines (XGBoost). With simulation experiments, we show that we can effectively model both the occurrence and reporting of events when dealing with high-dimensional covariate information. In the presence of non-linear effects, we show that our methodology outperforms existing EM-based nowcasting frameworks that use generalised linear models in the maximisation step. Finally, we apply the framework to the reporting of Argentinian Covid-19 cases, where the XGBoost-based approach again is most performant.
Reducing the dimensionality and granularity in hierarchical categorical variables
Mar 06, 2024



Hierarchical categorical variables often exhibit many levels (high granularity) and many classes within each level (high dimensionality). This may cause overfitting and estimation issues when including such covariates in a predictive model. In current literature, a hierarchical covariate is often incorporated via nested random effects. However, this does not facilitate the assumption of classes having the same effect on the response variable. In this paper, we propose a methodology to obtain a reduced representation of a hierarchical categorical variable. We show how entity embedding can be applied in a hierarchical setting. Subsequently, we propose a top-down clustering algorithm which leverages the information encoded in the embeddings to reduce both the within-level dimensionality as well as the overall granularity of the hierarchical categorical variable. In simulation experiments, we show that our methodology can effectively approximate the true underlying structure of a hierarchical covariate in terms of the effect on a response variable, and find that incorporating the reduced hierarchy improves model fit. We apply our methodology on a real dataset and find that the reduced hierarchy is an improvement over the original hierarchical structure and reduced structures proposed in the literature.