 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning in an expectation-maximisation framework for nowcasting
Dec 08, 2025

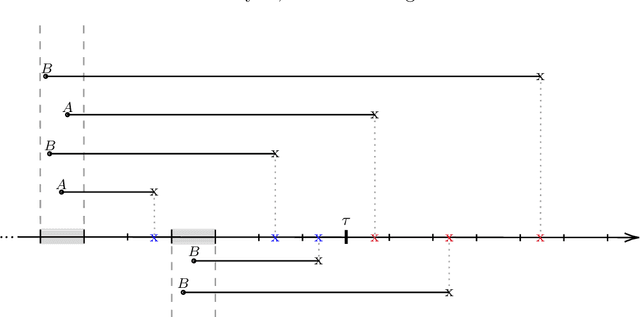

Decision making often occurs in the presence of incomplete information, leading to the under- or overestimation of risk. Leveraging the observable information to learn the complete information is called nowcasting. In practice, incomplete information is often a consequence of reporting or observation delays. In this paper, we propose an expectation-maximisation (EM) framework for nowcasting that uses machine learning techniques to model both the occurrence as well as the reporting process of events. We allow for the inclusion of covariate information specific to the occurrence and reporting periods as well as characteristics related to the entity for which events occurred. We demonstrate how the maximisation step and the information flow between EM iterations can be tailored to leverage the predictive power of neural networks and (extreme) gradient boosting machines (XGBoost). With simulation experiments, we show that we can effectively model both the occurrence and reporting of events when dealing with high-dimensional covariate information. In the presence of non-linear effects, we show that our methodology outperforms existing EM-based nowcasting frameworks that use generalised linear models in the maximisation step. Finally, we apply the framework to the reporting of Argentinian Covid-19 cases, where the XGBoost-based approach again is most performant.
Machine Learning with Multitype Protected Attributes: Intersectional Fairness through Regularisation
Sep 09, 2025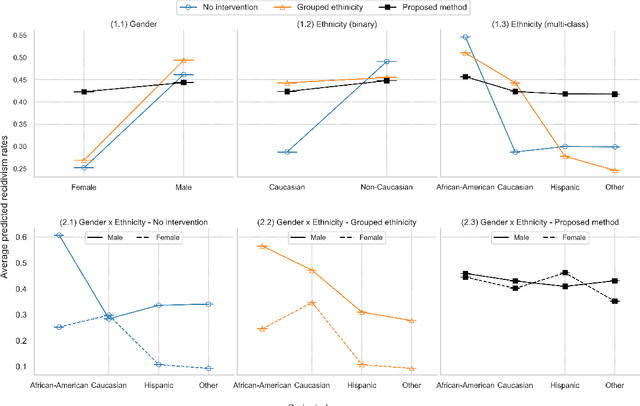
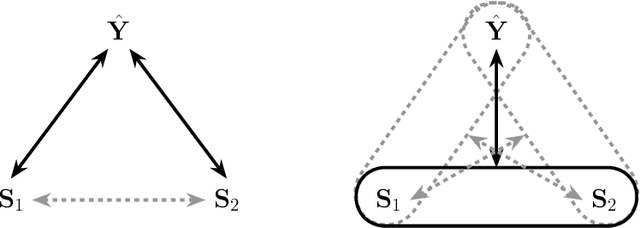
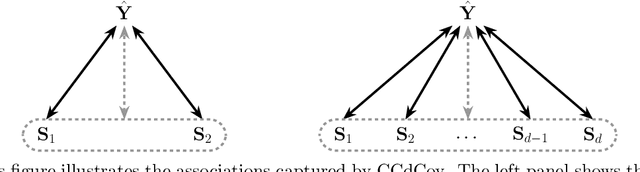
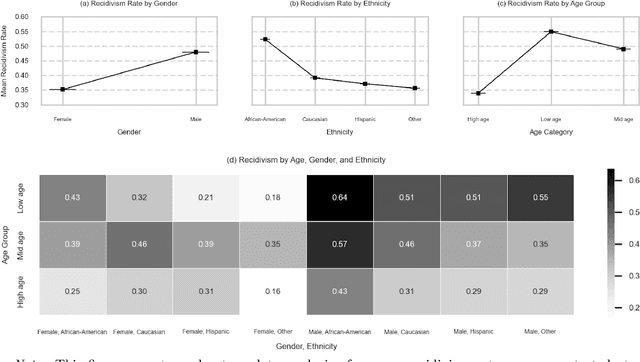
Ensuring equitable treatment (fairness) across protected attributes (such as gender or ethnicity) is a critical issue in machine learning. Most existing literature focuses on binary classification, but achieving fairness in regression tasks-such as insurance pricing or hiring score assessments-is equally important. Moreover, anti-discrimination laws also apply to continuous attributes, such as age, for which many existing methods are not applicable. In practice, multiple protected attributes can exist simultaneously; however, methods targeting fairness across several attributes often overlook so-called "fairness gerrymandering", thereby ignoring disparities among intersectional subgroups (e.g., African-American women or Hispanic men). In this paper, we propose a distance covariance regularisation framework that mitigates the association between model predictions and protected attributes, in line with the fairness definition of demographic parity, and that captures both linear and nonlinear dependencies. To enhance applicability in the presence of multiple protected attributes, we extend our framework by incorporating two multivariate dependence measures based on distance covariance: the previously proposed joint distance covariance (JdCov) and our novel concatenated distance covariance (CCdCov), which effectively address fairness gerrymandering in both regression and classification tasks involving protected attributes of various types. We discuss and illustrate how to calibrate regularisation strength, including a method based on Jensen-Shannon divergence, which quantifies dissimilarities in prediction distributions across groups. We apply our framework to the COMPAS recidivism dataset and a large motor insurance claims dataset.
Reducing the dimensionality and granularity in hierarchical categorical variables
Mar 06, 2024



Hierarchical categorical variables often exhibit many levels (high granularity) and many classes within each level (high dimensionality). This may cause overfitting and estimation issues when including such covariates in a predictive model. In current literature, a hierarchical covariate is often incorporated via nested random effects. However, this does not facilitate the assumption of classes having the same effect on the response variable. In this paper, we propose a methodology to obtain a reduced representation of a hierarchical categorical variable. We show how entity embedding can be applied in a hierarchical setting. Subsequently, we propose a top-down clustering algorithm which leverages the information encoded in the embeddings to reduce both the within-level dimensionality as well as the overall granularity of the hierarchical categorical variable. In simulation experiments, we show that our methodology can effectively approximate the true underlying structure of a hierarchical covariate in terms of the effect on a response variable, and find that incorporating the reduced hierarchy improves model fit. We apply our methodology on a real dataset and find that the reduced hierarchy is an improvement over the original hierarchical structure and reduced structures proposed in the literature.
Neural networks for insurance pricing with frequency and severity data: a benchmark study from data preprocessing to technical tariff
Oct 30, 2023



Insurers usually turn to generalized linear models for modelling claim frequency and severity data. Due to their success in other fields, machine learning techniques are gaining popularity within the actuarial toolbox. Our paper contributes to the literature on frequency-severity insurance pricing with machine learning via deep learning structures. We present a benchmark study on four insurance data sets with frequency and severity targets in the presence of multiple types of input features. We compare in detail the performance of: a generalized linear model on binned input data, a gradient-boosted tree model, a feed-forward neural network (FFNN), and the combined actuarial neural network (CANN). Our CANNs combine a baseline prediction established with a GLM and GBM, respectively, with a neural network correction. We explain the data preprocessing steps with specific focus on the multiple types of input features typically present in tabular insurance data sets, such as postal codes, numeric and categorical covariates. Autoencoders are used to embed the categorical variables into the neural network and we explore their potential advantages in a frequency-severity setting. Finally, we construct global surrogate models for the neural nets' frequency and severity models. These surrogates enable the translation of the essential insights captured by the FFNNs or CANNs to GLMs. As such, a technical tariff table results that can easily be deployed in practice.
An engine to simulate insurance fraud network data
Aug 21, 2023



Traditionally, the detection of fraudulent insurance claims relies on business rules and expert judgement which makes it a time-consuming and expensive process (\'Oskarsd\'ottir et al., 2022). Consequently, researchers have been examining ways to develop efficient and accurate analytic strategies to flag suspicious claims. Feeding learning methods with features engineered from the social network of parties involved in a claim is a particularly promising strategy (see for example Van Vlasselaer et al. (2016); Tumminello et al. (2023)). When developing a fraud detection model, however, we are confronted with several challenges. The uncommon nature of fraud, for example, creates a high class imbalance which complicates the development of well performing analytic classification models. In addition, only a small number of claims are investigated and get a label, which results in a large corpus of unlabeled data. Yet another challenge is the lack of publicly available data. This hinders not only the development of new methods, but also the validation of existing techniques. We therefore design a simulation machine that is engineered to create synthetic data with a network structure and available covariates similar to the real life insurance fraud data set analyzed in \'Oskarsd\'ottir et al. (2022). Further, the user has control over several data-generating mechanisms. We can specify the total number of policyholders and parties, the desired level of imbalance and the (effect size of the) features in the fraud generating model. As such, the simulation engine enables researchers and practitioners to examine several methodological challenges as well as to test their (development strategy of) insurance fraud detection models in a range of different settings. Moreover, large synthetic data sets can be generated to evaluate the predictive performance of (advanced) machine learning techniques.
Social network analytics for supervised fraud detection in insurance
Sep 15, 2020



Insurance fraud occurs when policyholders file claims that are exaggerated or based on intentional damages. This contribution develops a fraud detection strategy by extracting insightful information from the social network of a claim. First, we construct a network by linking claims with all their involved parties, including the policyholders, brokers, experts, and garages. Next, we establish fraud as a social phenomenon in the network and use the BiRank algorithm with a fraud specific query vector to compute a fraud score for each claim. From the network, we extract features related to the fraud scores as well as the claims' neighborhood structure. Finally, we combine these network features with the claim-specific features and build a supervised model with fraud in motor insurance as the target variable. Although we build a model for only motor insurance, the network includes claims from all available lines of business. Our results show that models with features derived from the network perform well when detecting fraud and even outperform the models using only the classical claim-specific features. Combining network and claim-specific features further improves the performance of supervised learning models to detect fraud. The resulting model flags highly suspicions claims that need to be further investigated. Our approach provides a guided and intelligent selection of claims and contributes to a more effective fraud investigation process.
Model-Agnostic Interpretable and Data-driven suRRogates suited for highly regulated industries
Jul 14, 2020



Highly regulated industries, like banking and insurance, ask for transparent decision-making algorithms. At the same time, competitive markets push for sophisticated black box models. We therefore present a procedure to develop a Model-Agnostic Interpretable Data-driven suRRogate, suited for structured tabular data. Insights are extracted from a black box via partial dependence effects. These are used to group feature values, resulting in a segmentation of the feature space with automatic feature selection. A transparent generalized linear model (GLM) is fit to the features in categorical format and their relevant interactions. We demonstrate our R package maidrr with a case study on general insurance claim frequency modeling for six public datasets. Our maidrr GLM closely approximates a gradient boosting machine (GBM) and outperforms both a linear and tree surrogate as benchmarks.
Boosting insights in insurance tariff plans with tree-based machine learning
Apr 12, 2019



Pricing actuaries typically stay within the framework of generalized linear models (GLMs). With the upswing of data analytics, our study puts focus on machine learning to develop full tariff plans built from both the frequency and severity of claims. We adapt the loss functions used in the algorithms such that the specific characteristics of insurance data are carefully incorporated: highly unbalanced count data with excess zeros and varying exposure on the frequency side combined with scarce, but potentially long-tailed data on the severity side. A key requirement is the need for transparent and interpretable pricing models which are easily explainable to all stakeholders. We therefore focus on machine learning with decision trees: starting from simple regression trees, we work towards more advanced ensembles such as random forests and boosted trees. We show how to choose the optimal tuning parameters for these models in an elaborate cross-validation scheme, we present visualization tools to obtain insights from the resulting models and the economic value of these new modeling approaches is evaluated. Boosted trees outperform the classical GLMs, allowing the insurer to form profitable portfolios and to guard against potential adverse selection risks.