 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Point to probabilistic gradient boosting for claim frequency and severity prediction
Dec 19, 2024



Gradient boosting for decision tree algorithms are increasingly used in actuarial applications as they show superior predictive performance over traditional generalized linear models. Many improvements and sophistications to the first gradient boosting machine algorithm exist. We present in a unified notation, and contrast, all the existing point and probabilistic gradient boosting for decision tree algorithms: GBM, XGBoost, DART, LightGBM, CatBoost, EGBM, PGBM, XGBoostLSS, cyclic GBM, and NGBoost. In this comprehensive numerical study, we compare their performance on five publicly available datasets for claim frequency and severity, of various size and comprising different number of (high cardinality) categorical variables. We explain how varying exposure-to-risk can be handled with boosting in frequency models. We compare the algorithms on the basis of computational efficiency, predictive performance, and model adequacy. LightGBM and XGBoostLSS win in terms of computational efficiency. The fully interpretable EGBM achieves competitive predictive performance compared to the black box algorithms considered. We find that there is no trade-off between model adequacy and predictive accuracy: both are achievable simultaneously.
Micro-level Reserving for General Insurance Claims using a Long Short-Term Memory Network
Jan 27, 2022

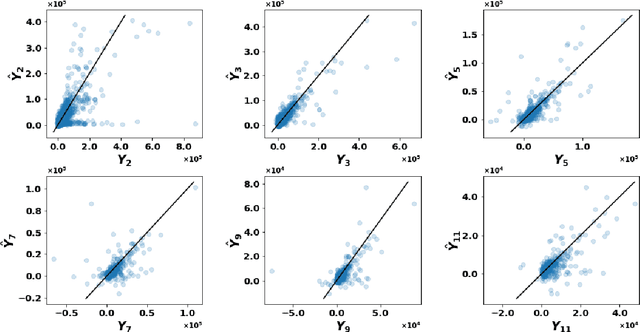
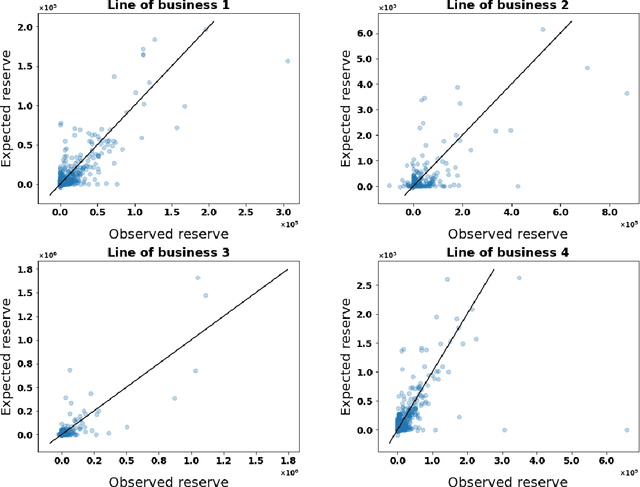
Detailed information about individual claims are completely ignored when insurance claims data are aggregated and structured in development triangles for loss reserving. In the hope of extracting predictive power from the individual claims characteristics, researchers have recently proposed to move away from these macro-level methods in favor of micro-level loss reserving approaches. We introduce a discrete-time individual reserving framework incorporating granular information in a deep learning approach named Long Short-Term Memory (LSTM) neural network. At each time period, the network has two tasks: first, classifying whether there is a payment or a recovery, and second, predicting the corresponding non-zero amount, if any. We illustrate the estimation procedure on a simulated and a real general insurance dataset. We compare our approach with the chain-ladder aggregate method using the predictive outstanding loss estimates and their actual values. Based on a generalized Pareto model for excess payments over a threshold, we adjust the LSTM reserve prediction to account for extreme payments.
Model-Agnostic Interpretable and Data-driven suRRogates suited for highly regulated industries
Jul 14, 2020



Highly regulated industries, like banking and insurance, ask for transparent decision-making algorithms. At the same time, competitive markets push for sophisticated black box models. We therefore present a procedure to develop a Model-Agnostic Interpretable Data-driven suRRogate, suited for structured tabular data. Insights are extracted from a black box via partial dependence effects. These are used to group feature values, resulting in a segmentation of the feature space with automatic feature selection. A transparent generalized linear model (GLM) is fit to the features in categorical format and their relevant interactions. We demonstrate our R package maidrr with a case study on general insurance claim frequency modeling for six public datasets. Our maidrr GLM closely approximates a gradient boosting machine (GBM) and outperforms both a linear and tree surrogate as benchmarks.
Boosting insights in insurance tariff plans with tree-based machine learning
Apr 12, 2019



Pricing actuaries typically stay within the framework of generalized linear models (GLMs). With the upswing of data analytics, our study puts focus on machine learning to develop full tariff plans built from both the frequency and severity of claims. We adapt the loss functions used in the algorithms such that the specific characteristics of insurance data are carefully incorporated: highly unbalanced count data with excess zeros and varying exposure on the frequency side combined with scarce, but potentially long-tailed data on the severity side. A key requirement is the need for transparent and interpretable pricing models which are easily explainable to all stakeholders. We therefore focus on machine learning with decision trees: starting from simple regression trees, we work towards more advanced ensembles such as random forests and boosted trees. We show how to choose the optimal tuning parameters for these models in an elaborate cross-validation scheme, we present visualization tools to obtain insights from the resulting models and the economic value of these new modeling approaches is evaluated. Boosted trees outperform the classical GLMs, allowing the insurer to form profitable portfolios and to guard against potential adverse selection risks.