 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal inference through multi-stage learning and doubly robust deep neural networks
Jul 11, 2024
Deep neural networks (DNNs) have demonstrated remarkable empirical performance in large-scale supervised learning problems, particularly in scenarios where both the sample size $n$ and the dimension of covariates $p$ are large. This study delves into the application of DNNs across a wide spectrum of intricate causal inference tasks, where direct estimation falls short and necessitates multi-stage learning. Examples include estimating the conditional average treatment effect and dynamic treatment effect. In this framework, DNNs are constructed sequentially, with subsequent stages building upon preceding ones. To mitigate the impact of estimation errors from early stages on subsequent ones, we integrate DNNs in a doubly robust manner. In contrast to previous research, our study offers theoretical assurances regarding the effectiveness of DNNs in settings where the dimensionality $p$ expands with the sample size. These findings are significant independently and extend to degenerate single-stage learning problems.
Adaptive Split Balancing for Optimal Random Forest
Feb 17, 2024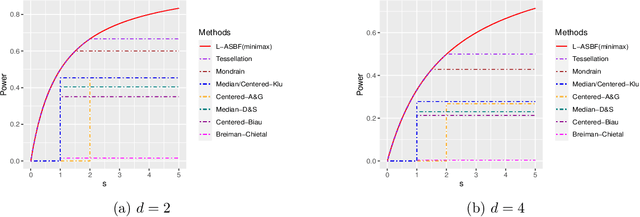
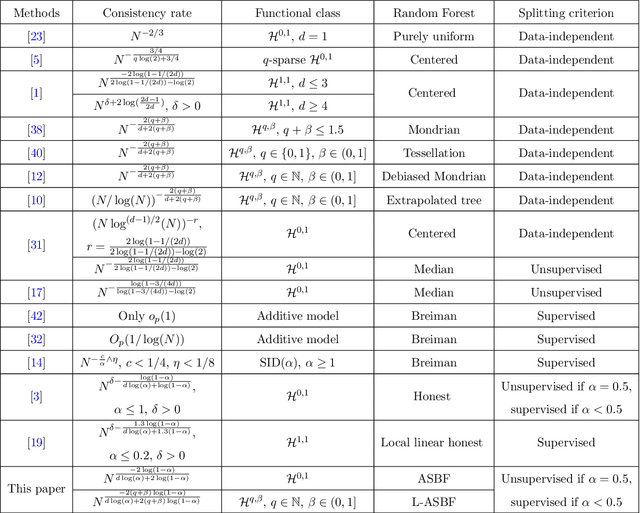
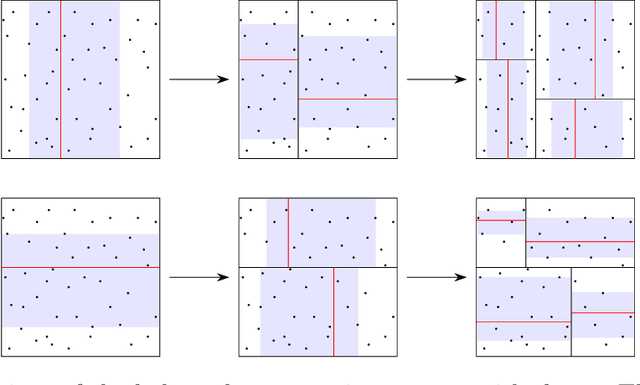
While random forests are commonly used for regression problems, existing methods often lack adaptability in complex situations or lose optimality under simple, smooth scenarios. In this study, we introduce the adaptive split balancing forest (ASBF), capable of learning tree representations from data while simultaneously achieving minimax optimality under the Lipschitz class. To exploit higher-order smoothness levels, we further propose a localized version that attains the minimax rate under the H\"older class $\mathcal{H}^{q,\beta}$ for any $q\in\mathbb{N}$ and $\beta\in(0,1]$. Rather than relying on the widely-used random feature selection, we consider a balanced modification to existing approaches. Our results indicate that an over-reliance on auxiliary randomness may compromise the approximation power of tree models, leading to suboptimal results. Conversely, a less random, more balanced approach demonstrates optimality. Additionally, we establish uniform upper bounds and explore the application of random forests in average treatment effect estimation problems. Through simulation studies and real-data applications, we demonstrate the superior empirical performance of the proposed methods over existing random forests.
Semi-Supervised Causal Inference: Generalizable and Double Robust Inference for Average Treatment Effects under Selection Bias with Decaying Overlap
May 22, 2023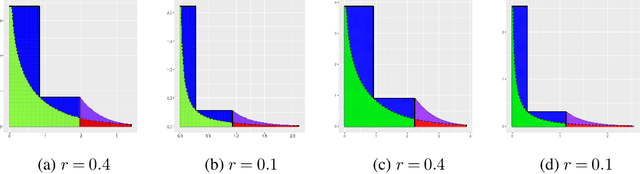
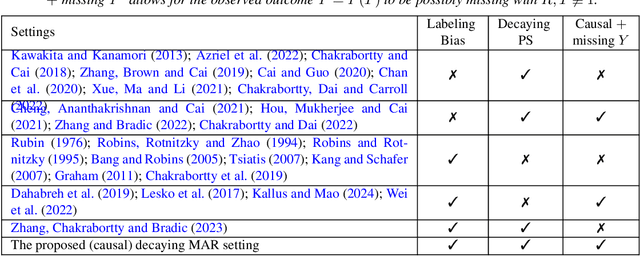
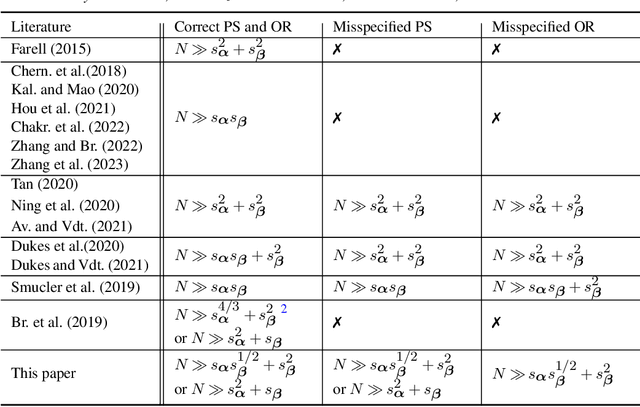
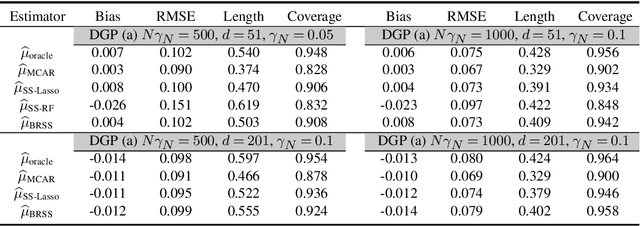
Average treatment effect (ATE) estimation is an essential problem in the causal inference literature, which has received significant recent attention, especially with the presence of high-dimensional confounders. We consider the ATE estimation problem in high dimensions when the observed outcome (or label) itself is possibly missing. The labeling indicator's conditional propensity score is allowed to depend on the covariates, and also decay uniformly with sample size - thus allowing for the unlabeled data size to grow faster than the labeled data size. Such a setting fills in an important gap in both the semi-supervised (SS) and missing data literatures. We consider a missing at random (MAR) mechanism that allows selection bias - this is typically forbidden in the standard SS literature, and without a positivity condition - this is typically required in the missing data literature. We first propose a general doubly robust 'decaying' MAR (DR-DMAR) SS estimator for the ATE, which is constructed based on flexible (possibly non-parametric) nuisance estimators. The general DR-DMAR SS estimator is shown to be doubly robust, as well as asymptotically normal (and efficient) when all the nuisance models are correctly specified. Additionally, we propose a bias-reduced DR-DMAR SS estimator based on (parametric) targeted bias-reducing nuisance estimators along with a special asymmetric cross-fitting strategy. We demonstrate that the bias-reduced ATE estimator is asymptotically normal as long as either the outcome regression or the propensity score model is correctly specified. Moreover, the required sparsity conditions are weaker than all the existing doubly robust causal inference literature even under the regular supervised setting - this is a special degenerate case of our setting. Lastly, this work also contributes to the growing literature on generalizability in causal inference.
Dynamic treatment effects: high-dimensional inference under model misspecification
Nov 12, 2021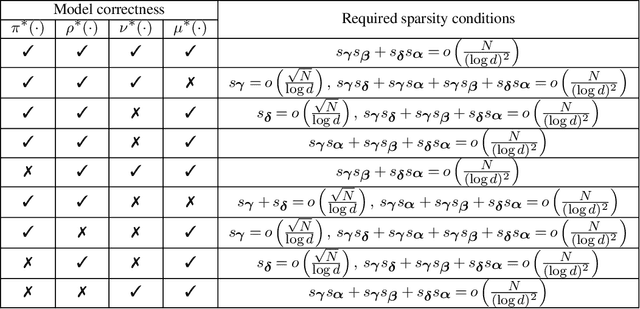
This paper considers the inference for heterogeneous treatment effects in dynamic settings that covariates and treatments are longitudinal. We focus on high-dimensional cases that the sample size, $N$, is potentially much larger than the covariate vector's dimension, $d$. The marginal structural mean models are considered. We propose a "sequential model doubly robust" estimator constructed based on "moment targeted" nuisance estimators. Such nuisance estimators are carefully designed through non-standard loss functions, reducing the bias resulting from potential model misspecifications. We achieve $\sqrt N$-inference even when model misspecification occurs. We only require one nuisance model to be correctly specified at each time spot. Such model correctness conditions are weaker than all the existing work, even containing the literature on low dimensions.
High-dimensional Inference for Dynamic Treatment Effects
Oct 10, 2021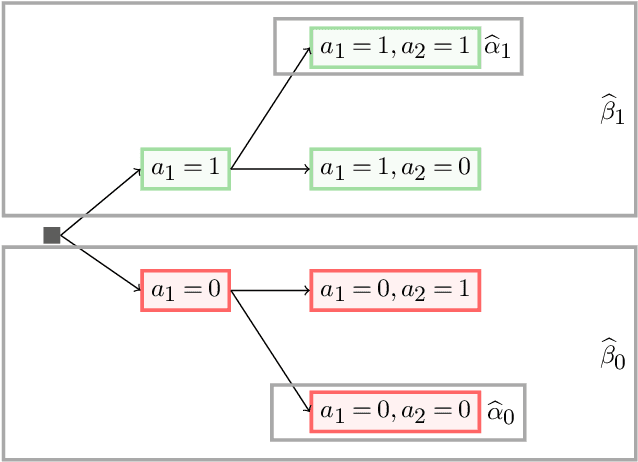
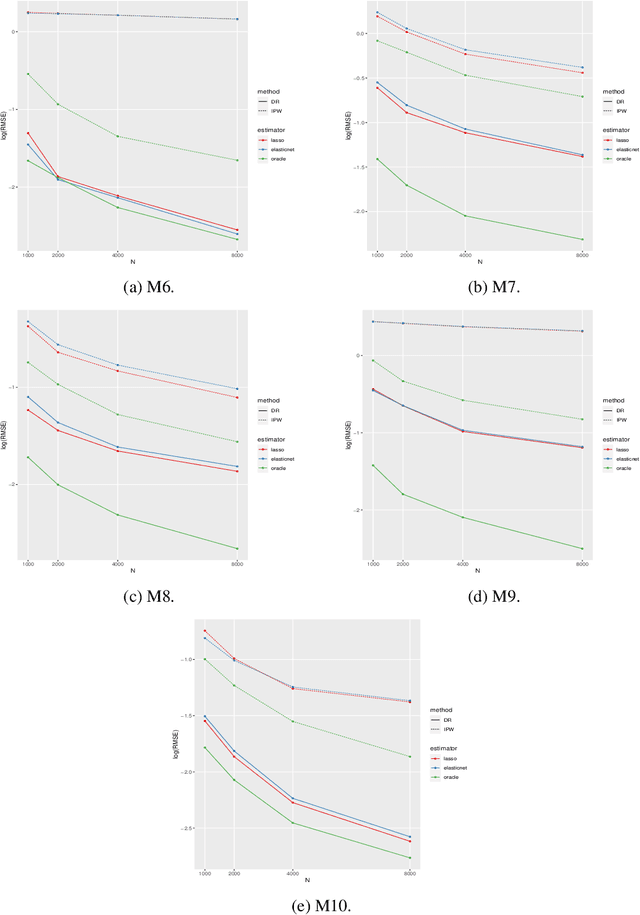
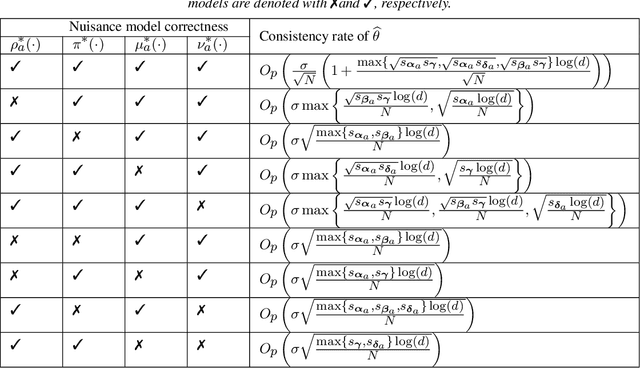
This paper proposes a confidence interval construction for heterogeneous treatment effects in the context of multi-stage experiments with $N$ samples and high-dimensional, $d$, confounders. Our focus is on the case of $d\gg N$, but the results obtained also apply to low-dimensional cases. We showcase that the bias of regularized estimation, unavoidable in high-dimensional covariate spaces, is mitigated with a simple double-robust score. In this way, no additional bias removal is necessary, and we obtain root-$N$ inference results while allowing multi-stage interdependency of the treatments and covariates. Memoryless property is also not assumed; treatment can possibly depend on all previous treatment assignments and all previous multi-stage confounders. Our results rely on certain sparsity assumptions of the underlying dependencies. We discover new product rate conditions necessary for robust inference with dynamic treatments.
Double Robust Semi-Supervised Inference for the Mean: Selection Bias under MAR Labeling with Decaying Overlap
Apr 14, 2021
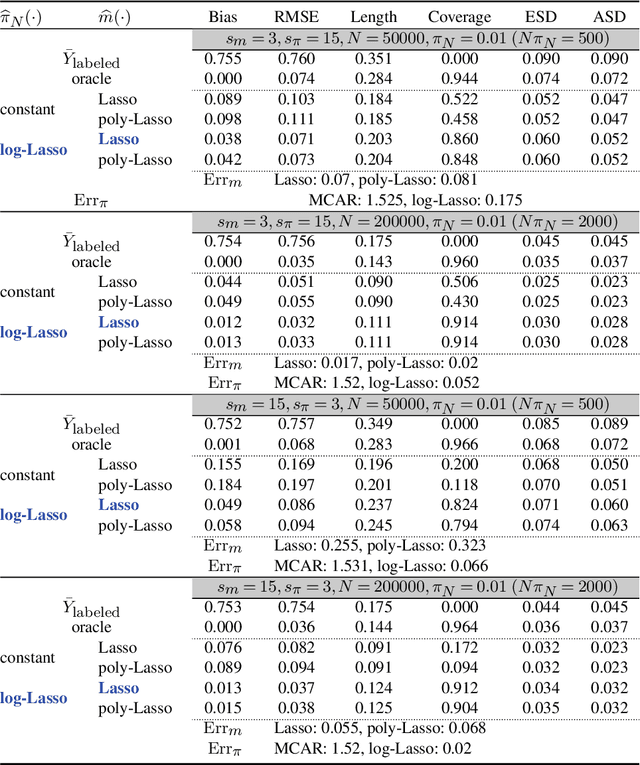
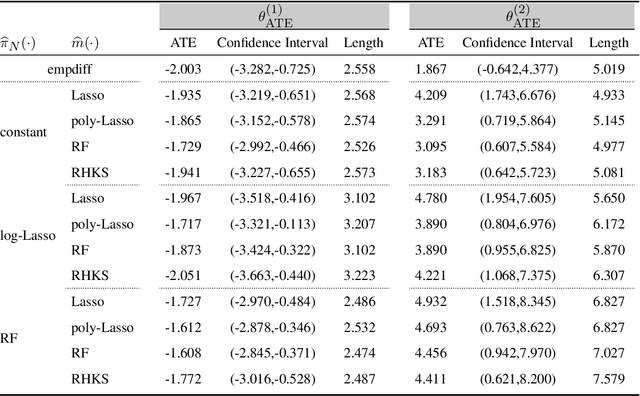
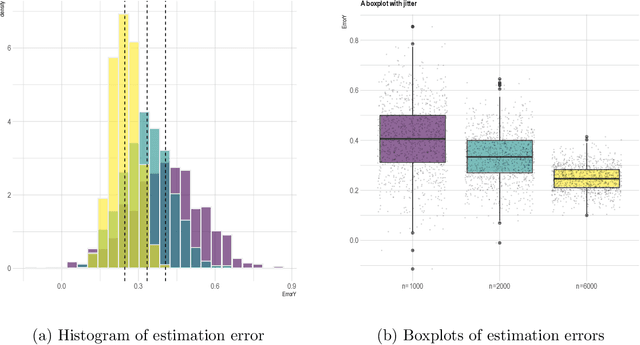
Semi-supervised (SS) inference has received much attention in recent years. Apart from a moderate-sized labeled data, L, the SS setting is characterized by an additional, much larger sized, unlabeled data, U. The setting of |U| >> |L|, makes SS inference unique and different from the standard missing data problems, owing to natural violation of the so-called 'positivity' or 'overlap' assumption. However, most of the SS literature implicitly assumes L and U to be equally distributed, i.e., no selection bias in the labeling. Inferential challenges in missing at random (MAR) type labeling allowing for selection bias, are inevitably exacerbated by the decaying nature of the propensity score (PS). We address this gap for a prototype problem, the estimation of the response's mean. We propose a double robust SS (DRSS) mean estimator and give a complete characterization of its asymptotic properties. The proposed estimator is consistent as long as either the outcome or the PS model is correctly specified. When both models are correctly specified, we provide inference results with a non-standard consistency rate that depends on the smaller size |L|. The results are also extended to causal inference with imbalanced treatment groups. Further, we provide several novel choices of models and estimators of the decaying PS, including a novel offset logistic model and a stratified labeling model. We present their properties under both high and low dimensional settings. These may be of independent interest. Lastly, we present extensive simulations and also a real data application.
Comments on Leo Breiman's paper 'Statistical Modeling: The Two Cultures' , 199-231)
Mar 21, 2021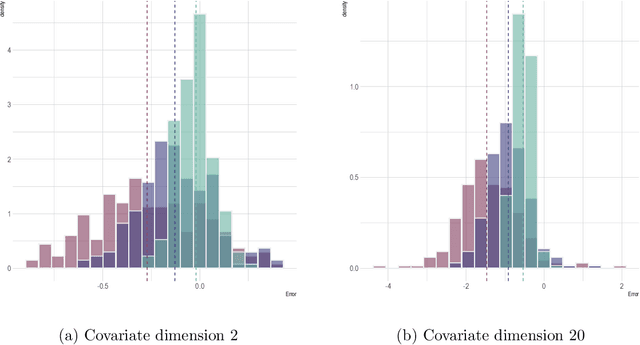

Breiman challenged statisticians to think more broadly, to step into the unknown, model-free learning world, with him paving the way forward. Statistics community responded with slight optimism, some skepticism, and plenty of disbelief. Today, we are at the same crossroad anew. Faced with the enormous practical success of model-free, deep, and machine learning, we are naturally inclined to think that everything is resolved. A new frontier has emerged; the one where the role, impact, or stability of the {\it learning} algorithms is no longer measured by prediction quality, but an inferential one -- asking the questions of {\it why} and {\it if} can no longer be safely ignored.
Dynamic covariate balancing: estimating treatment effects over time
Mar 01, 2021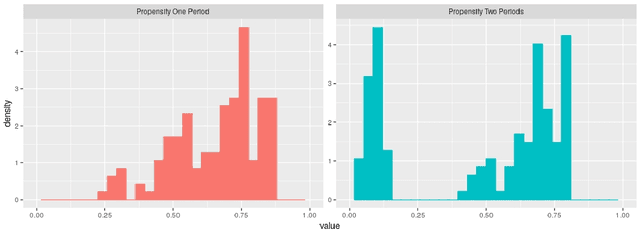
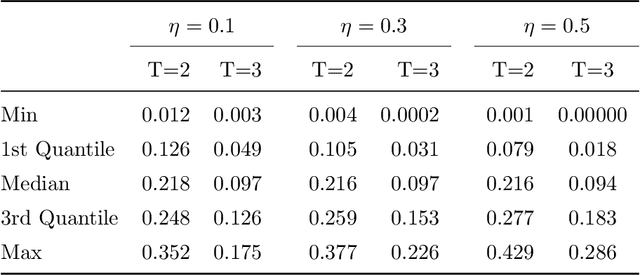
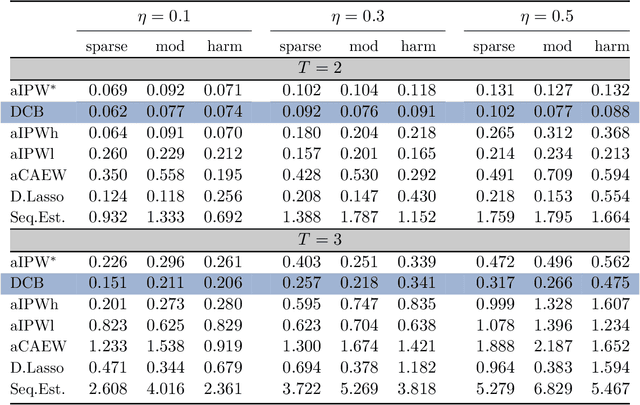
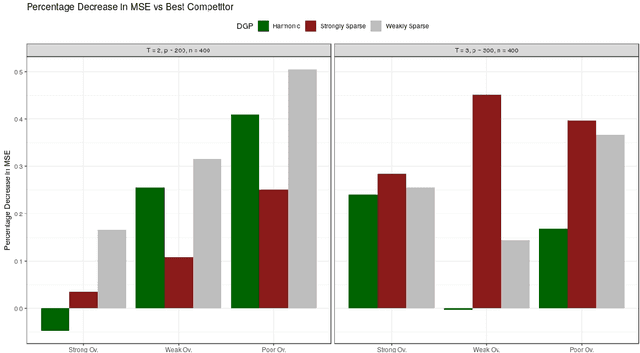
This paper discusses the problem of estimation and inference on time-varying treatments. We propose a method for inference on treatment histories, by introducing a \textit{dynamic} covariate balancing method. Our approach allows for (i) treatments to propagate arbitrarily over time; (ii) non-stationarity and heterogeneity of treatment effects; (iii) high-dimensional covariates, and (iv) unknown propensity score functions. We study the asymptotic properties of the estimator, and we showcase the parametric convergence rate of the proposed procedure. We illustrate in simulations and an empirical application the advantage of the method over state-of-the-art competitors.
Learning to Combat Noisy Labels via Classification Margins
Feb 01, 2021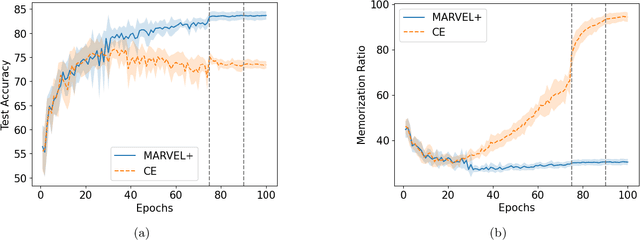
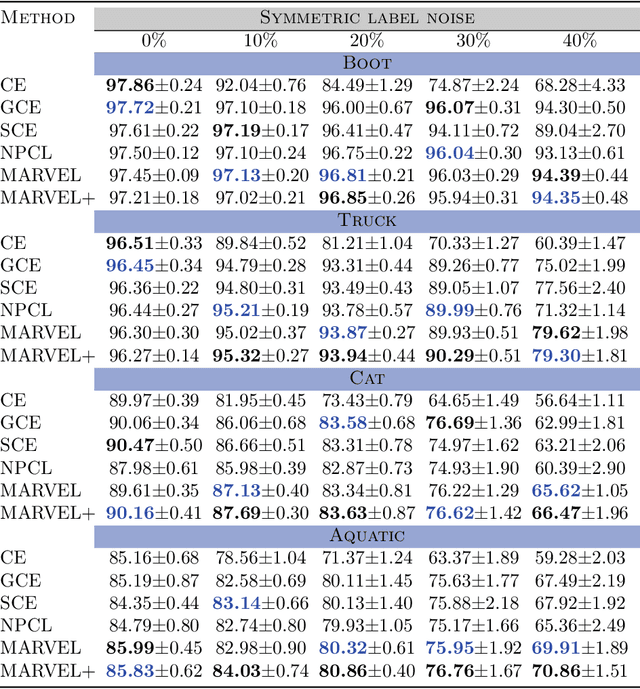
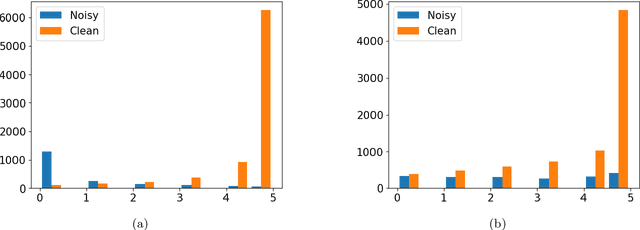
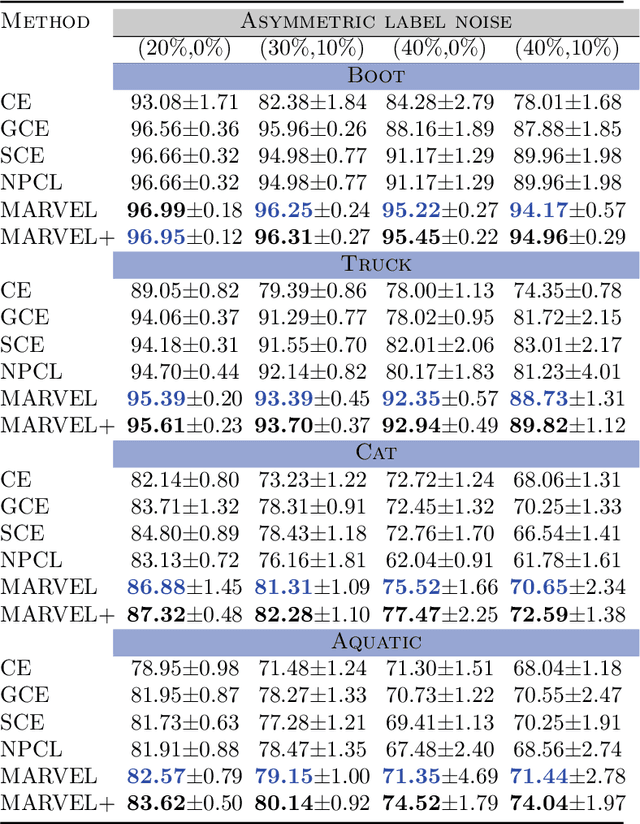
A deep neural network trained on noisy labels is known to quickly lose its power to discriminate clean instances from noisy ones. After the early learning phase has ended, the network memorizes the noisy instances, which leads to a degradation in generalization performance. To resolve this issue, we propose MARVEL (MARgins Via Early Learning), where we track the goodness of "fit" for every instance by maintaining an epoch-history of its classification margins. Based on consecutive negative margins, we discard suspected noisy instances by zeroing out their weights. In addition, MARVEL+ upweights arduous instances enabling the network to learn a more nuanced representation of the classification boundary. Experimental results on benchmark datasets with synthetic label noise show that MARVEL outperforms other baselines consistently across different noise levels, with a significantly larger margin under asymmetric noise.
DeepHazard: neural network for time-varying risks
Jul 26, 2020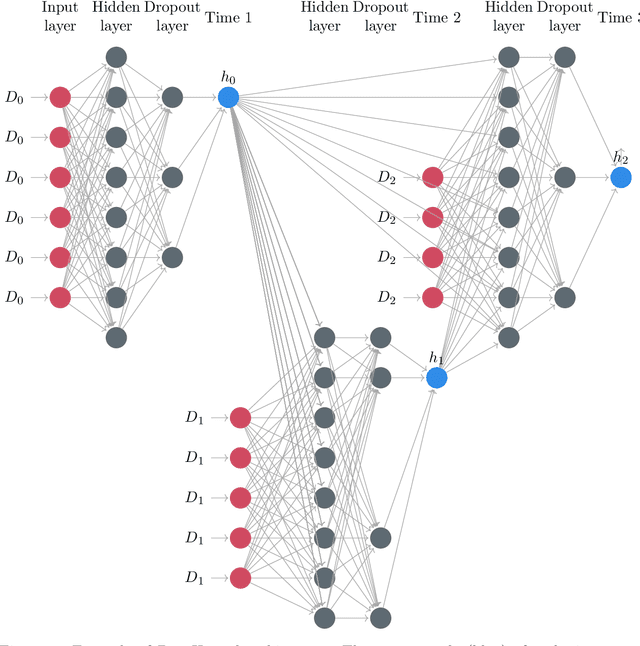
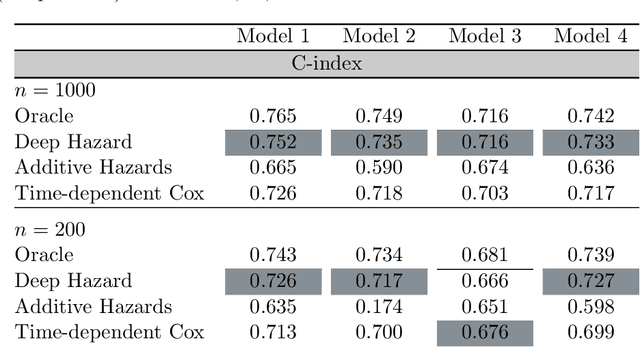
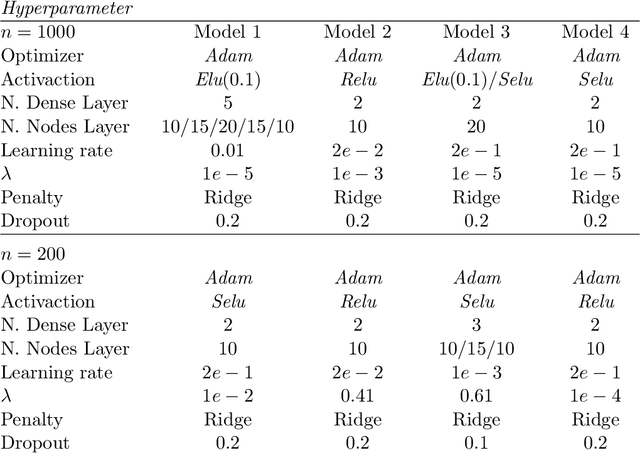
Prognostic models in survival analysis are aimed at understanding the relationship between patients' covariates and the distribution of survival time. Traditionally, semi-parametric models, such as the Cox model, have been assumed. These often rely on strong proportionality assumptions of the hazard that might be violated in practice. Moreover, they do not often include covariate information updated over time. We propose a new flexible method for survival prediction: DeepHazard, a neural network for time-varying risks. Our approach is tailored for a wide range of continuous hazards forms, with the only restriction of being additive in time. A flexible implementation, allowing different optimization methods, along with any norm penalty, is developed. Numerical examples illustrate that our approach outperforms existing state-of-the-art methodology in terms of predictive capability evaluated through the C-index metric. The same is revealed on the popular real datasets as METABRIC, GBSG, and ACTG.