 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Robust Semi-Supervised Inference for the Mean: Selection Bias under MAR Labeling with Decaying Overlap
Paper and Code
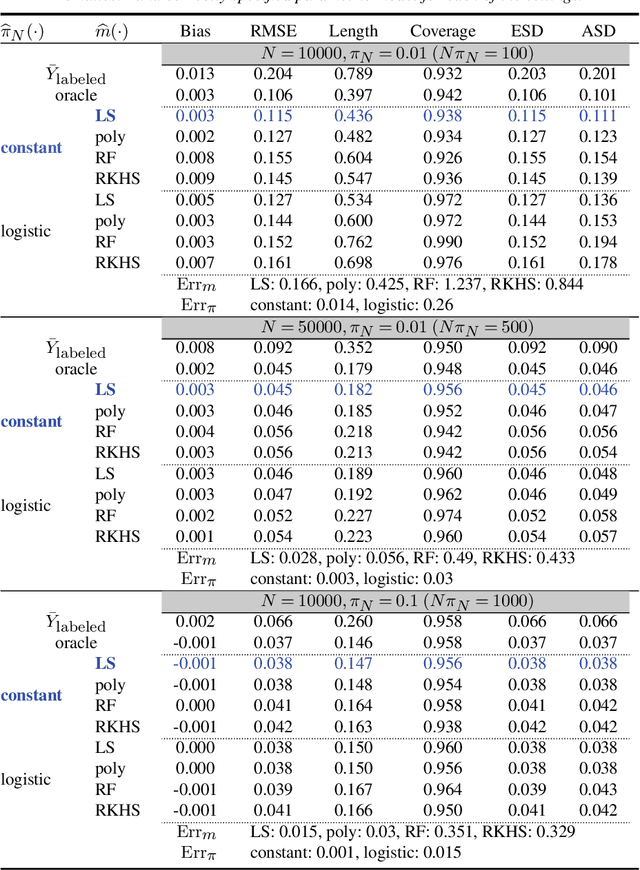
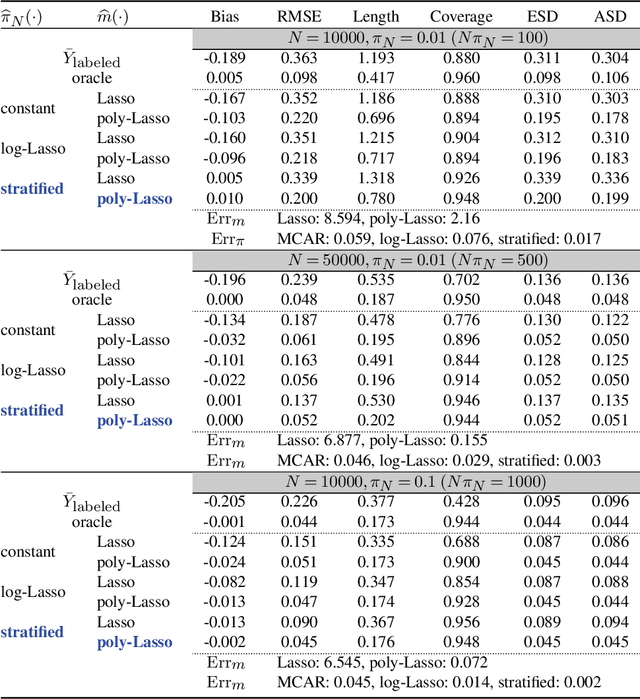
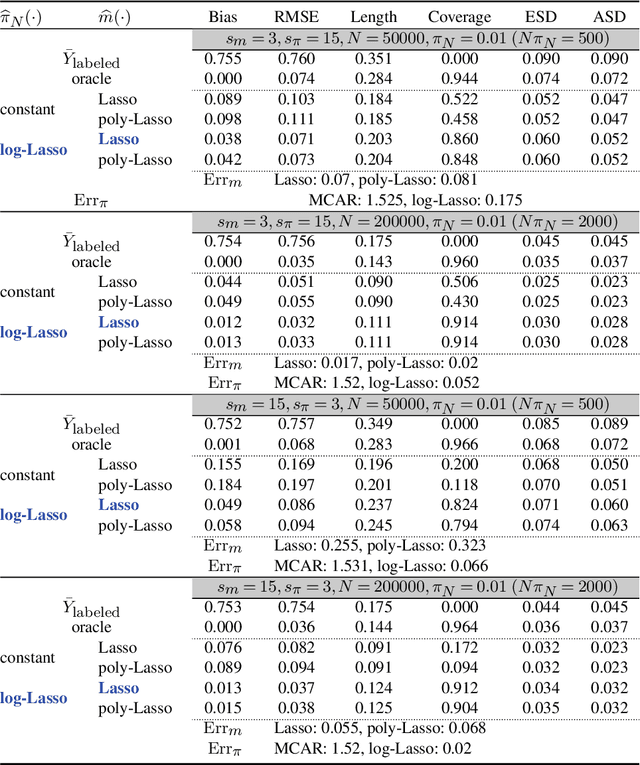
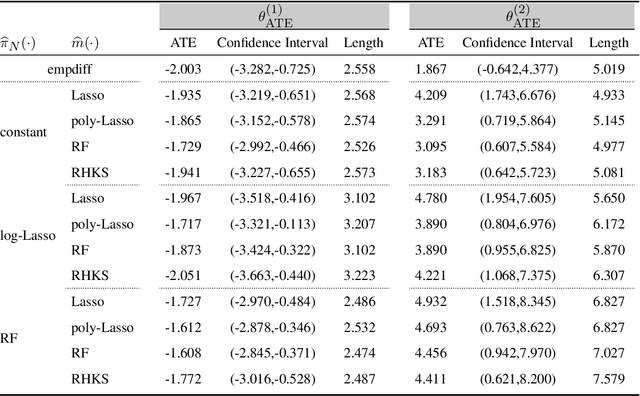
Semi-supervised (SS) inference has received much attention in recent years. Apart from a moderate-sized labeled data, L, the SS setting is characterized by an additional, much larger sized, unlabeled data, U. The setting of |U| >> |L|, makes SS inference unique and different from the standard missing data problems, owing to natural violation of the so-called 'positivity' or 'overlap' assumption. However, most of the SS literature implicitly assumes L and U to be equally distributed, i.e., no selection bias in the labeling. Inferential challenges in missing at random (MAR) type labeling allowing for selection bias, are inevitably exacerbated by the decaying nature of the propensity score (PS). We address this gap for a prototype problem, the estimation of the response's mean. We propose a double robust SS (DRSS) mean estimator and give a complete characterization of its asymptotic properties. The proposed estimator is consistent as long as either the outcome or the PS model is correctly specified. When both models are correctly specified, we provide inference results with a non-standard consistency rate that depends on the smaller size |L|. The results are also extended to causal inference with imbalanced treatment groups. Further, we provide several novel choices of models and estimators of the decaying PS, including a novel offset logistic model and a stratified labeling model. We present their properties under both high and low dimensional settings. These may be of independent interest. Lastly, we present extensive simulations and also a real data application.