 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Colors to Classes: Emergence of Concepts in Vision Transformers
Paper and Code
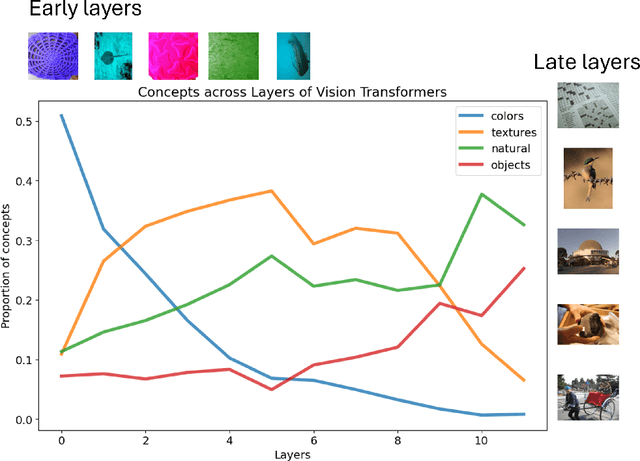
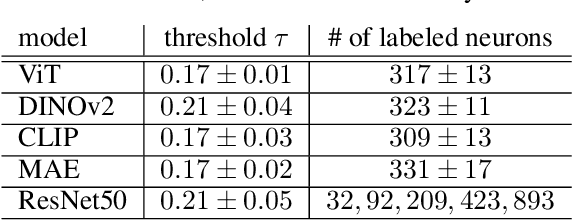
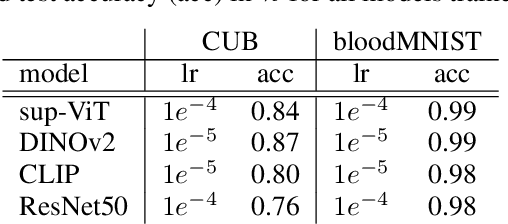
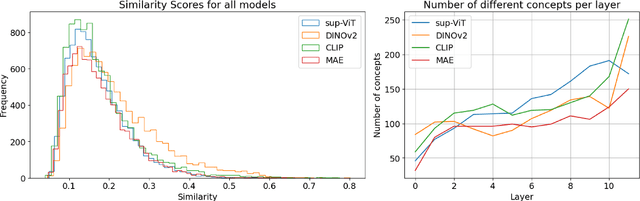
Vision Transformers (ViTs) are increasingly utilized in various computer vision tasks due to their powerful representation capabilities. However, it remains understudied how ViTs process information layer by layer. Numerous studies have shown that convolutional neural networks (CNNs) extract features of increasing complexity throughout their layers, which is crucial for tasks like domain adaptation and transfer learning. ViTs, lacking the same inductive biases as CNNs, can potentially learn global dependencies from the first layers due to their attention mechanisms. Given the increasing importance of ViTs in computer vision, there is a need to improve the layer-wise understanding of ViTs. In this work, we present a novel, layer-wise analysis of concepts encoded in state-of-the-art ViTs using neuron labeling. Our findings reveal that ViTs encode concepts with increasing complexity throughout the network. Early layers primarily encode basic features such as colors and textures, while later layers represent more specific classes, including objects and animals. As the complexity of encoded concepts increases, the number of concepts represented in each layer also rises, reflecting a more diverse and specific set of features. Additionally, different pretraining strategies influence the quantity and category of encoded concepts, with finetuning to specific downstream tasks generally reducing the number of encoded concepts and shifting the concepts to more relevant categories.