 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHubness Reduction Improves Sentence-BERT Semantic Spaces
Paper and Code


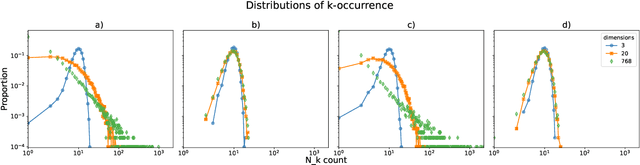

Semantic representations of text, i.e. representations of natural language which capture meaning by geometry, are essential for areas such as information retrieval and document grouping. High-dimensional trained dense vectors have received much attention in recent years as such representations. We investigate the structure of semantic spaces that arise from embeddings made with Sentence-BERT and find that the representations suffer from a well-known problem in high dimensions called hubness. Hubness results in asymmetric neighborhood relations, such that some texts (the hubs) are neighbours of many other texts while most texts (so-called anti-hubs), are neighbours of few or no other texts. We quantify the semantic quality of the embeddings using hubness scores and error rate of a neighbourhood based classifier. We find that when hubness is high, we can reduce error rate and hubness using hubness reduction methods. We identify a combination of two methods as resulting in the best reduction. For example, on one of the tested pretrained models, this combined method can reduce hubness by about 75% and error rate by about 9%. Thus, we argue that mitigating hubness in the embedding space provides better semantic representations of text.