 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanoliteracy of Generative, Large Language Models
Oct 30, 2024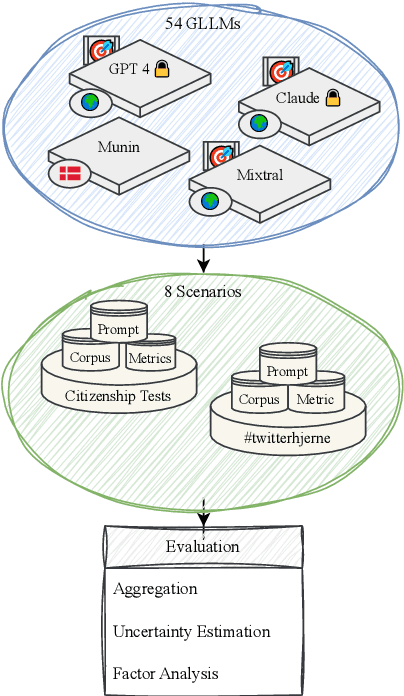
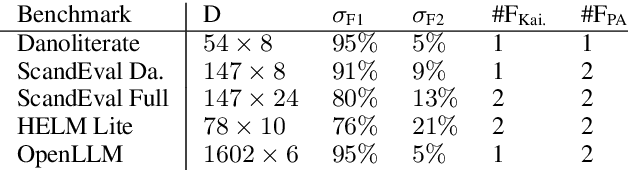
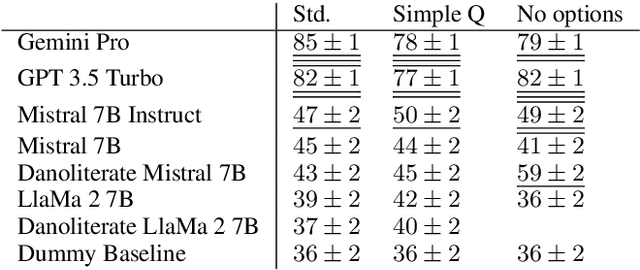
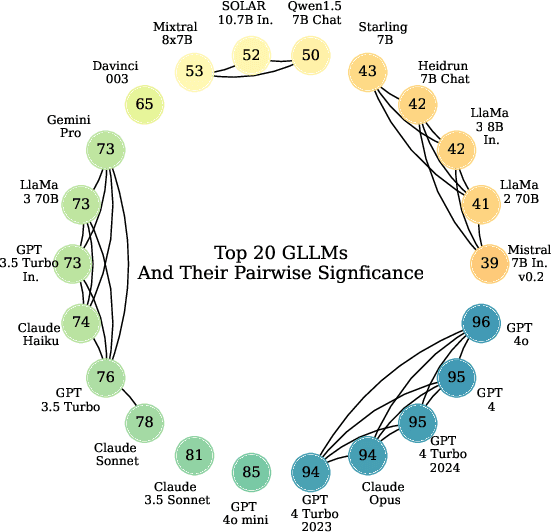
The language technology moonshot moment of Generative, Large Language Models (GLLMs) was not limited to English: These models brought a surge of technological applications, investments and hype to low-resource languages as well. However, the capabilities of these models in languages such as Danish were until recently difficult to verify beyond qualitative demonstrations due to a lack of applicable evaluation corpora. We present a GLLM benchmark to evaluate Danoliteracy, a measure of Danish language and cultural competency, across eight diverse scenarios such Danish citizenship tests and abstractive social media question answering. This limited-size benchmark is found to produce a robust ranking that correlates to human feedback at $\rho \sim 0.8$ with GPT-4 and Claude Opus models achieving the highest rankings. Analyzing these model results across scenarios, we find one strong underlying factor explaining $95\%$ of scenario performance variance for GLLMs in Danish, suggesting a $g$ factor of model consistency in language adaption.
Topic Model Robustness to Automatic Speech Recognition Errors in Podcast Transcripts
Sep 25, 2021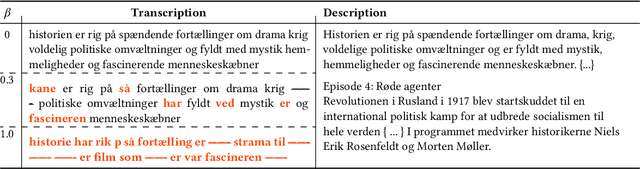
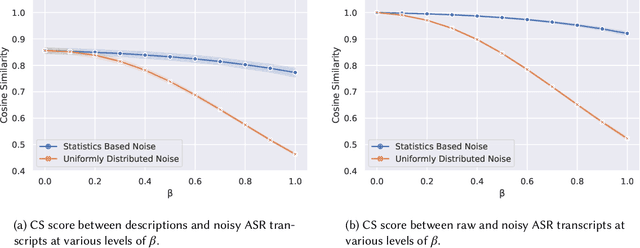

For a multilingual podcast streaming service, it is critical to be able to deliver relevant content to all users independent of language. Podcast content relevance is conventionally determined using various metadata sources. However, with the increasing quality of speech recognition in many languages, utilizing automatic transcriptions to provide better content recommendations becomes possible. In this work, we explore the robustness of a Latent Dirichlet Allocation topic model when applied to transcripts created by an automatic speech recognition engine. Specifically, we explore how increasing transcription noise influences topics obtained from transcriptions in Danish; a low resource language. First, we observe a baseline of cosine similarity scores between topic embeddings from automatic transcriptions and the descriptions of the podcasts written by the podcast creators. We then observe how the cosine similarities decrease as transcription noise increases and conclude that even when automatic speech recognition transcripts are erroneous, it is still possible to obtain high-quality topic embeddings from the transcriptions.