 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanoliteracy of Generative, Large Language Models
Paper and Code
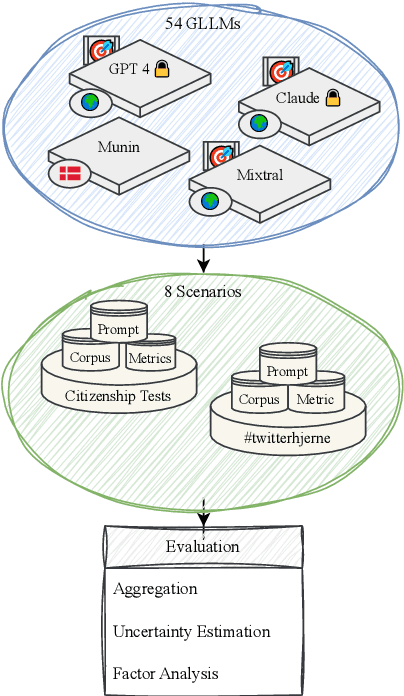
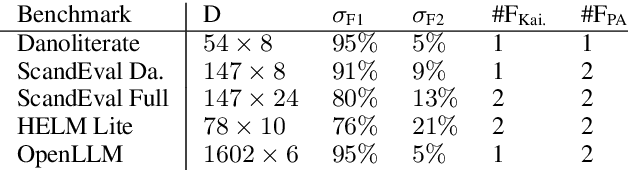
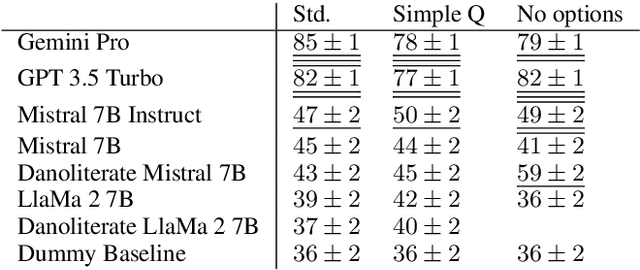
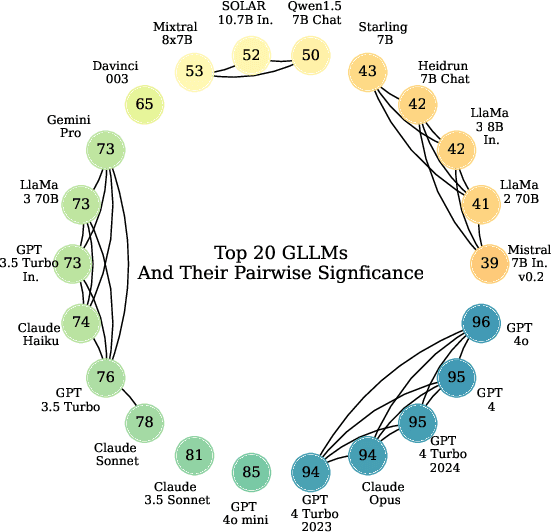
The language technology moonshot moment of Generative, Large Language Models (GLLMs) was not limited to English: These models brought a surge of technological applications, investments and hype to low-resource languages as well. However, the capabilities of these models in languages such as Danish were until recently difficult to verify beyond qualitative demonstrations due to a lack of applicable evaluation corpora. We present a GLLM benchmark to evaluate Danoliteracy, a measure of Danish language and cultural competency, across eight diverse scenarios such Danish citizenship tests and abstractive social media question answering. This limited-size benchmark is found to produce a robust ranking that correlates to human feedback at $\rho \sim 0.8$ with GPT-4 and Claude Opus models achieving the highest rankings. Analyzing these model results across scenarios, we find one strong underlying factor explaining $95\%$ of scenario performance variance for GLLMs in Danish, suggesting a $g$ factor of model consistency in language adaption.