 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholarly Wikidata: Population and Exploration of Conference Data in Wikidata using LLMs
Nov 13, 2024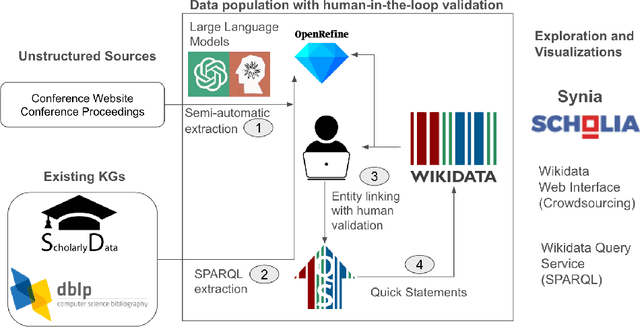
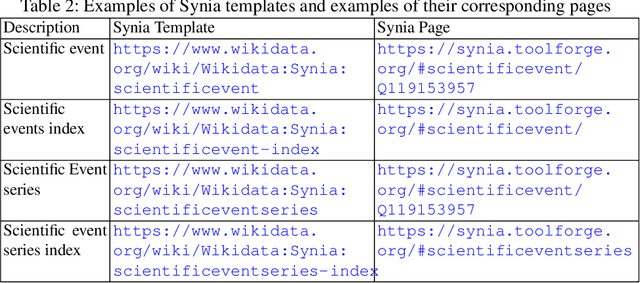
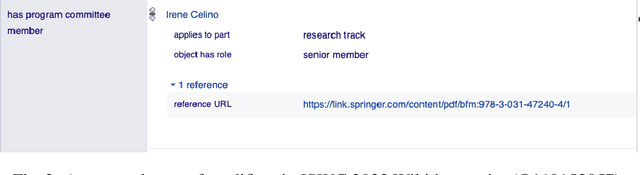

Several initiatives have been undertaken to conceptually model the domain of scholarly data using ontologies and to create respective Knowledge Graphs. Yet, the full potential seems unleashed, as automated means for automatic population of said ontologies are lacking, and respective initiatives from the Semantic Web community are not necessarily connected: we propose to make scholarly data more sustainably accessible by leveraging Wikidata's infrastructure and automating its population in a sustainable manner through LLMs by tapping into unstructured sources like conference Web sites and proceedings texts as well as already existing structured conference datasets. While an initial analysis shows that Semantic Web conferences are only minimally represented in Wikidata, we argue that our methodology can help to populate, evolve and maintain scholarly data as a community within Wikidata. Our main contributions include (a) an analysis of ontologies for representing scholarly data to identify gaps and relevant entities/properties in Wikidata, (b) semi-automated extraction -- requiring (minimal) manual validation -- of conference metadata (e.g., acceptance rates, organizer roles, programme committee members, best paper awards, keynotes, and sponsors) from websites and proceedings texts using LLMs. Finally, we discuss (c) extensions to visualization tools in the Wikidata context for data exploration of the generated scholarly data. Our study focuses on data from 105 Semantic Web-related conferences and extends/adds more than 6000 entities in Wikidata. It is important to note that the method can be more generally applicable beyond Semantic Web-related conferences for enhancing Wikidata's utility as a comprehensive scholarly resource. Source Repository: https://github.com/scholarly-wikidata/ DOI: https://doi.org/10.5281/zenodo.10989709 License: Creative Commons CC0 (Data), MIT (Code)
Knowledge graphs for empirical concept retrieval
Apr 10, 2024Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz.\ as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user's intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models' representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
The Danish Gigaword Project
May 08, 2020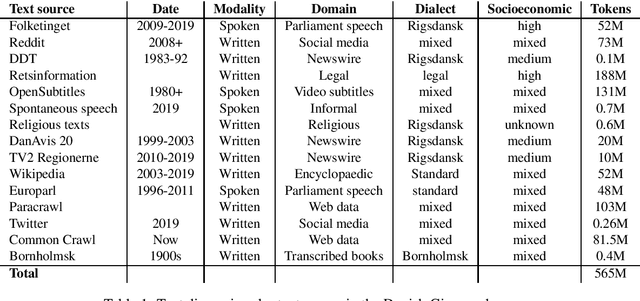
Danish is a North Germanic/Scandinavian language spoken primarily in Denmark, a country with a tradition of technological and scientific innovation. However, from a technological perspective, the Danish language has received relatively little attention and, as a result, Danish language technology is hard to develop, in part due to a lack of large or broad-coverage Danish corpora. This paper describes the Danish Gigaword project, which aims to construct a freely-available one billion word corpus of Danish text that represents the breadth of the written language.
Linking ImageNet WordNet Synsets with Wikidata
Mar 05, 2018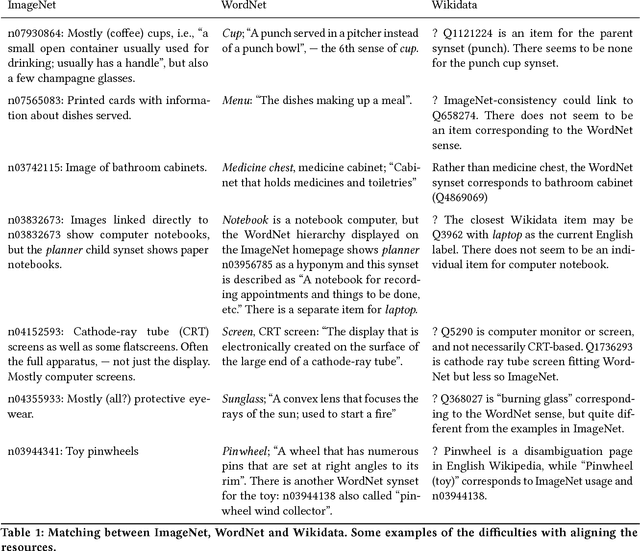

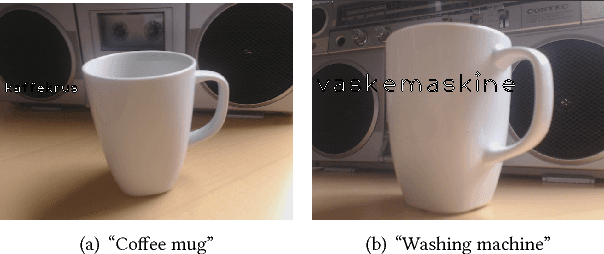
The linkage of ImageNet WordNet synsets to Wikidata items will leverage deep learning algorithm with access to a rich multilingual knowledge graph. Here I will describe our on-going efforts in linking the two resources and issues faced in matching the Wikidata and WordNet knowledge graphs. I show an example on how the linkage can be used in a deep learning setting with real-time image classification and labeling in a non-English language and discuss what opportunities lies ahead.
Wembedder: Wikidata entity embedding web service
Oct 11, 2017

I present a web service for querying an embedding of entities in the Wikidata knowledge graph. The embedding is trained on the Wikidata dump using Gensim's Word2Vec implementation and a simple graph walk. A REST API is implemented. Together with the Wikidata API the web service exposes a multilingual resource for over 600'000 Wikidata items and properties.
Online open neuroimaging mass meta-analysis
Jun 13, 2012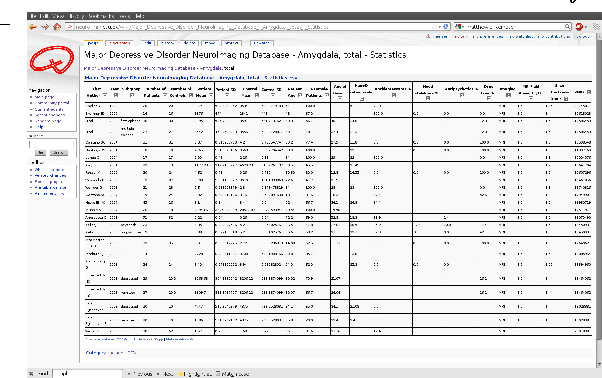
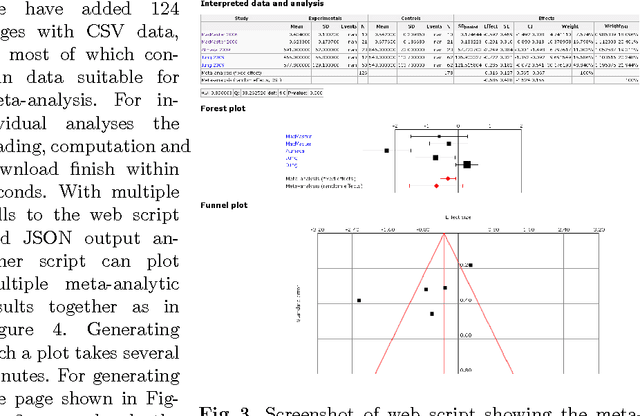
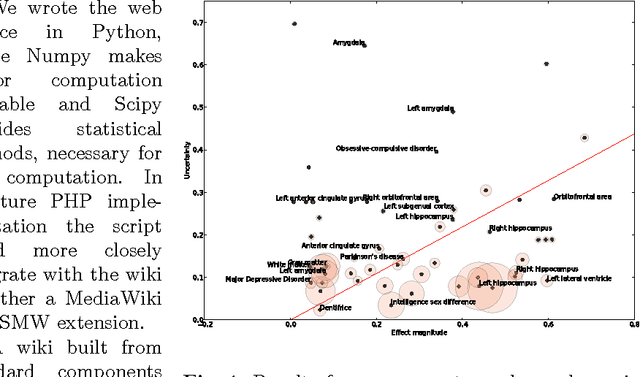
We describe a system for meta-analysis where a wiki stores numerical data in a simple format and a web service performs the numerical computation. We initially apply the system on multiple meta-analyses of structural neuroimaging data results. The described system allows for mass meta-analysis, e.g., meta-analysis across multiple brain regions and multiple mental disorders.
A new ANEW: Evaluation of a word list for sentiment analysis in microblogs
Mar 15, 2011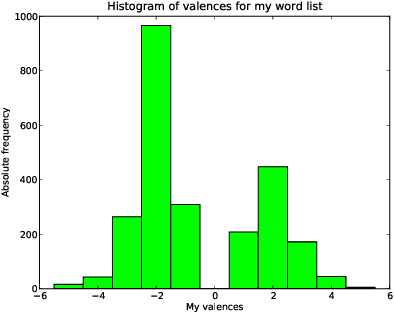

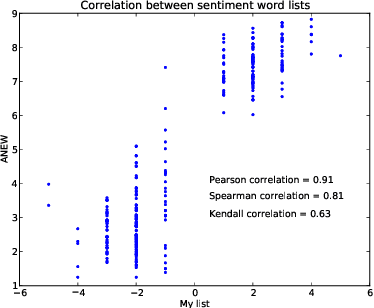
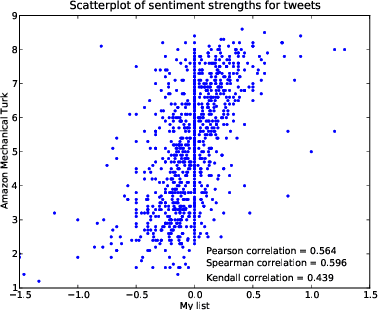
Sentiment analysis of microblogs such as Twitter has recently gained a fair amount of attention. One of the simplest sentiment analysis approaches compares the words of a posting against a labeled word list, where each word has been scored for valence, -- a 'sentiment lexicon' or 'affective word lists'. There exist several affective word lists, e.g., ANEW (Affective Norms for English Words) developed before the advent of microblogging and sentiment analysis. I wanted to examine how well ANEW and other word lists performs for the detection of sentiment strength in microblog posts in comparison with a new word list specifically constructed for microblogs. I used manually labeled postings from Twitter scored for sentiment. Using a simple word matching I show that the new word list may perform better than ANEW, though not as good as the more elaborate approach found in SentiStrength.
* 6 pages, 4 figures, 1 table, Submitted to "Making Sense of Microposts (#MSM2011)"
Good Friends, Bad News - Affect and Virality in Twitter
Jan 03, 2011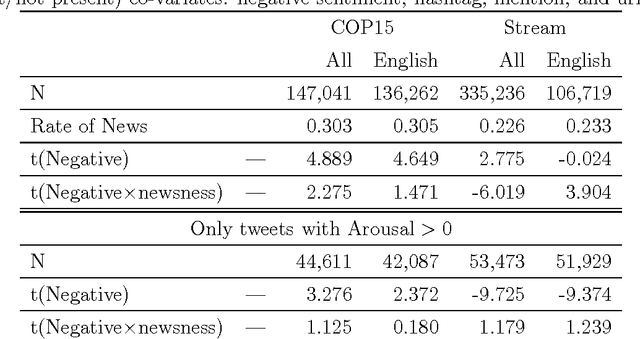
The link between affect, defined as the capacity for sentimental arousal on the part of a message, and virality, defined as the probability that it be sent along, is of significant theoretical and practical importance, e.g. for viral marketing. A quantitative study of emailing of articles from the NY Times finds a strong link between positive affect and virality, and, based on psychological theories it is concluded that this relation is universally valid. The conclusion appears to be in contrast with classic theory of diffusion in news media emphasizing negative affect as promoting propagation. In this paper we explore the apparent paradox in a quantitative analysis of information diffusion on Twitter. Twitter is interesting in this context as it has been shown to present both the characteristics social and news media. The basic measure of virality in Twitter is the probability of retweet. Twitter is different from email in that retweeting does not depend on pre-existing social relations, but often occur among strangers, thus in this respect Twitter may be more similar to traditional news media. We therefore hypothesize that negative news content is more likely to be retweeted, while for non-news tweets positive sentiments support virality. To test the hypothesis we analyze three corpora: A complete sample of tweets about the COP15 climate summit, a random sample of tweets, and a general text corpus including news. The latter allows us to train a classifier that can distinguish tweets that carry news and non-news information. We present evidence that negative sentiment enhances virality in the news segment, but not in the non-news segment. We conclude that the relation between affect and virality is more complex than expected based on the findings of Berger and Milkman (2010), in short 'if you want to be cited: Sweet talk your friends or serve bad news to the public'.