 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Said What? An Automated Approach to Analyzing Speech in Preschool Classrooms
Jan 14, 2024



Young children spend substantial portions of their waking hours in noisy preschool classrooms. In these environments, children's vocal interactions with teachers are critical contributors to their language outcomes, but manually transcribing these interactions is prohibitive. Using audio from child- and teacher-worn recorders, we propose an automated framework that uses open source software both to classify speakers (ALICE) and to transcribe their utterances (Whisper). We compare results from our framework to those from a human expert for 110 minutes of classroom recordings, including 85 minutes from child-word microphones (n=4 children) and 25 minutes from teacher-worn microphones (n=2 teachers). The overall proportion of agreement, that is, the proportion of correctly classified teacher and child utterances, was .76, with an error-corrected kappa of .50 and a weighted F1 of .76. The word error rate for both teacher and child transcriptions was .15, meaning that 15% of words would need to be deleted, added, or changed to equate the Whisper and expert transcriptions. Moreover, speech features such as the mean length of utterances in words, the proportion of teacher and child utterances that were questions, and the proportion of utterances that were responded to within 2.5 seconds were similar when calculated separately from expert and automated transcriptions. The results suggest substantial progress in analyzing classroom speech that may support children's language development. Future research using natural language processing is underway to improve speaker classification and to analyze results from the application of the automated it framework to a larger dataset containing classroom recordings from 13 children and 4 teachers observed on 17 occasions over one year.
Automated speech- and text-based classification of neuropsychiatric conditions in a multidiagnostic setting
Jan 13, 2023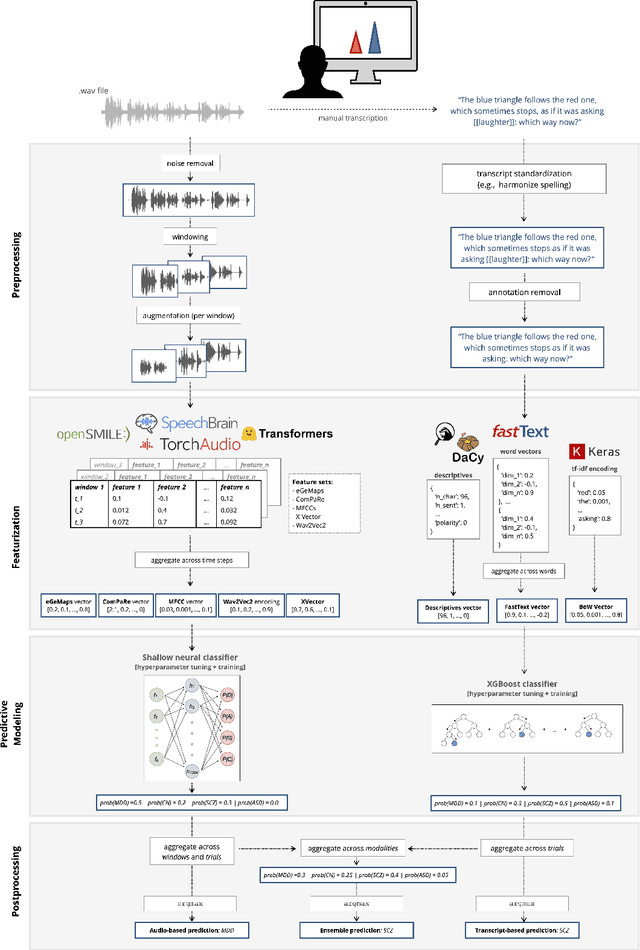
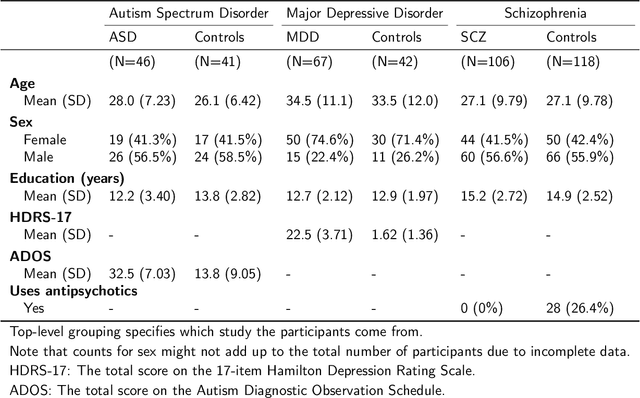
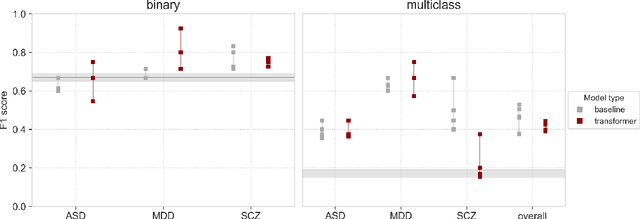
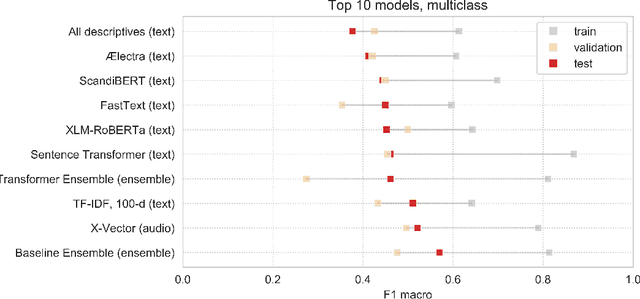
Speech patterns have been identified as potential diagnostic markers for neuropsychiatric conditions. However, most studies only compare a single clinical group to healthy controls, whereas clinical practice often requires differentiating between multiple potential diagnoses (multiclass settings). To address this, we assembled a dataset of repeated recordings from 420 participants (67 with major depressive disorder, 106 with schizophrenia and 46 with autism, as well as matched controls), and tested the performance of a range of conventional machine learning models and advanced Transformer models on both binary and multiclass classification, based on voice and text features. While binary models performed comparably to previous research (F1 scores between 0.54-0.75 for autism spectrum disorder, ASD; 0.67-0.92 for major depressive disorder, MDD; and 0.71-0.83 for schizophrenia); when differentiating between multiple diagnostic groups performance decreased markedly (F1 scores between 0.35-0.44 for ASD, 0.57-0.75 for MDD, 0.15-0.66 for schizophrenia, and 0.38-0.52 macro F1). Combining voice and text-based models yielded increased performance, suggesting that they capture complementary diagnostic information. Our results indicate that models trained on binary classification may learn to rely on markers of generic differences between clinical and non-clinical populations, or markers of clinical features that overlap across conditions, rather than identifying markers specific to individual conditions. We provide recommendations for future research in the field, suggesting increased focus on developing larger transdiagnostic datasets that include more fine-grained clinical features, and that can support the development of models that better capture the complexity of neuropsychiatric conditions and naturalistic diagnostic assessment.
The Danish Gigaword Project
May 08, 2020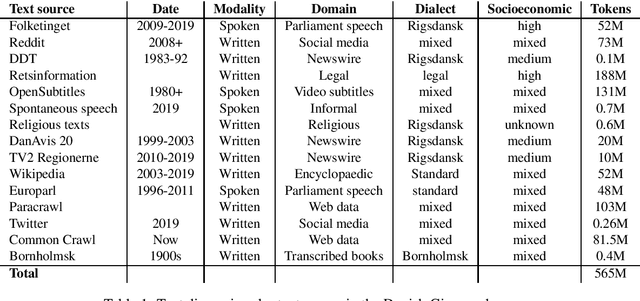
Danish is a North Germanic/Scandinavian language spoken primarily in Denmark, a country with a tradition of technological and scientific innovation. However, from a technological perspective, the Danish language has received relatively little attention and, as a result, Danish language technology is hard to develop, in part due to a lack of large or broad-coverage Danish corpora. This paper describes the Danish Gigaword project, which aims to construct a freely-available one billion word corpus of Danish text that represents the breadth of the written language.