 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymLoc: Symbolic Localization of Hallucination across HaluEval and TruthfulQA
Nov 18, 2025



LLMs still struggle with hallucination, especially when confronted with symbolic triggers like modifiers, negation, numbers, exceptions, and named entities. Yet, we lack a clear understanding of where these symbolic hallucinations originate, making it crucial to systematically handle such triggers and localize the emergence of hallucination inside the model. While prior work explored localization using statistical techniques like LSC and activation variance analysis, these methods treat all tokens equally and overlook the role symbolic linguistic knowledge plays in triggering hallucinations. So far, no approach has investigated how symbolic elements specifically drive hallucination failures across model layers, nor has symbolic linguistic knowledge been used as the foundation for a localization framework. We propose the first symbolic localization framework that leverages symbolic linguistic and semantic knowledge to meaningfully trace the development of hallucinations across all model layers. By focusing on how models process symbolic triggers, we analyze five models using HaluEval and TruthfulQA. Our symbolic knowledge approach reveals that attention variance for these linguistic elements explodes to critical instability in early layers (2-4), with negation triggering catastrophic variance levels, demonstrating that symbolic semantic processing breaks down from the very beginning. Through the lens of symbolic linguistic knowledge, despite larger model sizes, hallucination rates remain consistently high (78.3%-83.7% across Gemma variants), with steep attention drops for symbolic semantic triggers throughout deeper layers. Our findings demonstrate that hallucination is fundamentally a symbolic linguistic processing failure, not a general generation problem, revealing that symbolic semantic knowledge provides the key to understanding and localizing hallucination mechanisms in LLMs.
Scholarly Wikidata: Population and Exploration of Conference Data in Wikidata using LLMs
Nov 13, 2024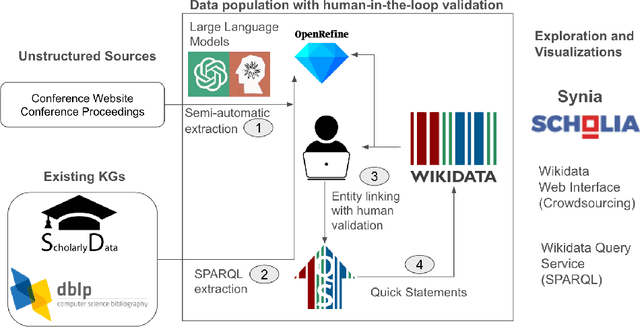
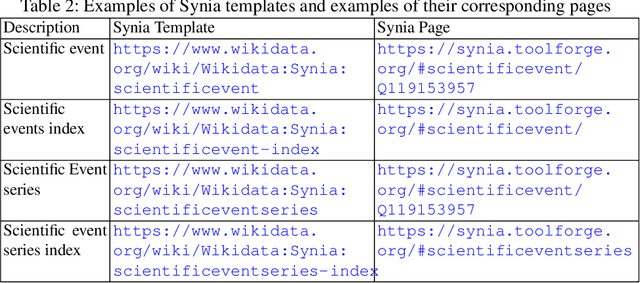

Several initiatives have been undertaken to conceptually model the domain of scholarly data using ontologies and to create respective Knowledge Graphs. Yet, the full potential seems unleashed, as automated means for automatic population of said ontologies are lacking, and respective initiatives from the Semantic Web community are not necessarily connected: we propose to make scholarly data more sustainably accessible by leveraging Wikidata's infrastructure and automating its population in a sustainable manner through LLMs by tapping into unstructured sources like conference Web sites and proceedings texts as well as already existing structured conference datasets. While an initial analysis shows that Semantic Web conferences are only minimally represented in Wikidata, we argue that our methodology can help to populate, evolve and maintain scholarly data as a community within Wikidata. Our main contributions include (a) an analysis of ontologies for representing scholarly data to identify gaps and relevant entities/properties in Wikidata, (b) semi-automated extraction -- requiring (minimal) manual validation -- of conference metadata (e.g., acceptance rates, organizer roles, programme committee members, best paper awards, keynotes, and sponsors) from websites and proceedings texts using LLMs. Finally, we discuss (c) extensions to visualization tools in the Wikidata context for data exploration of the generated scholarly data. Our study focuses on data from 105 Semantic Web-related conferences and extends/adds more than 6000 entities in Wikidata. It is important to note that the method can be more generally applicable beyond Semantic Web-related conferences for enhancing Wikidata's utility as a comprehensive scholarly resource. Source Repository: https://github.com/scholarly-wikidata/ DOI: https://doi.org/10.5281/zenodo.10989709 License: Creative Commons CC0 (Data), MIT (Code)
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Jun 12, 2024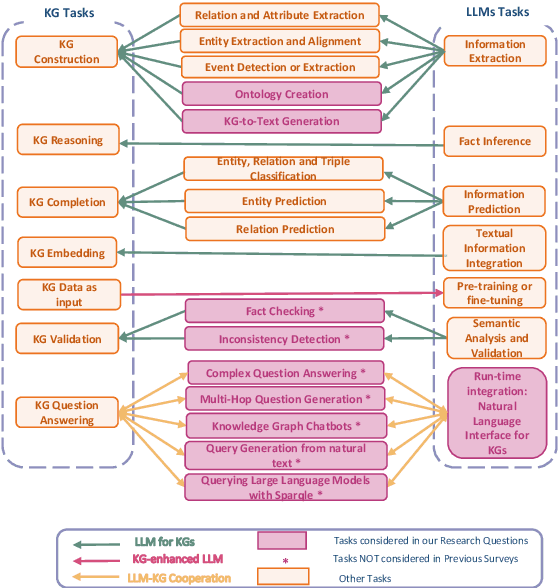
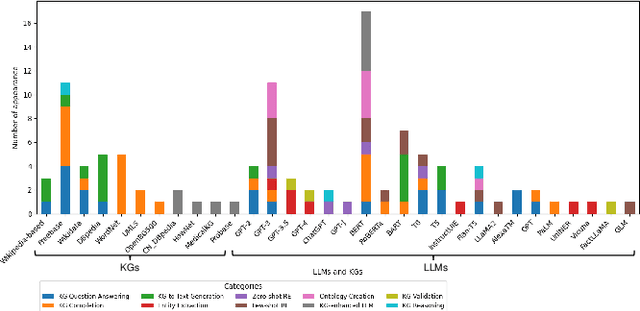
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
An approach based on Open Research Knowledge Graph for Knowledge Acquisition from scientific papers
Aug 23, 2023A scientific paper can be divided into two major constructs which are Metadata and Full-body text. Metadata provides a brief overview of the paper while the Full-body text contains key-insights that can be valuable to fellow researchers. To retrieve metadata and key-insights from scientific papers, knowledge acquisition is a central activity. It consists of gathering, analyzing and organizing knowledge embedded in scientific papers in such a way that it can be used and reused whenever needed. Given the wealth of scientific literature, manual knowledge acquisition is a cumbersome task. Thus, computer-assisted and (semi-)automatic strategies are generally adopted. Our purpose in this research was two fold: curate Open Research Knowledge Graph (ORKG) with papers related to ontology learning and define an approach using ORKG as a computer-assisted tool to organize key-insights extracted from research papers. This approach was used to document the "epidemiological surveillance systems design and implementation" research problem and to prepare the related work of this paper. It is currently used to document "food information engineering", "Tabular data to Knowledge Graph Matching" and "Question Answering" research problems and "Neuro-symbolic AI" domain.
Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text
Aug 04, 2023
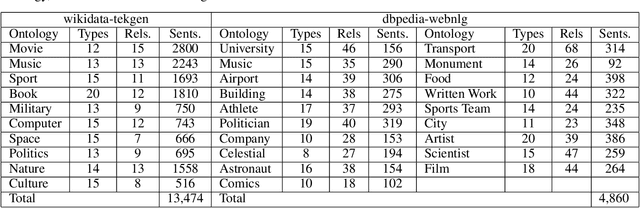


The recent advances in large language models (LLM) and foundation models with emergent capabilities have been shown to improve the performance of many NLP tasks. LLMs and Knowledge Graphs (KG) can complement each other such that LLMs can be used for KG construction or completion while existing KGs can be used for different tasks such as making LLM outputs explainable or fact-checking in Neuro-Symbolic manner. In this paper, we present Text2KGBench, a benchmark to evaluate the capabilities of language models to generate KGs from natural language text guided by an ontology. Given an input ontology and a set of sentences, the task is to extract facts from the text while complying with the given ontology (concepts, relations, domain/range constraints) and being faithful to the input sentences. We provide two datasets (i) Wikidata-TekGen with 10 ontologies and 13,474 sentences and (ii) DBpedia-WebNLG with 19 ontologies and 4,860 sentences. We define seven evaluation metrics to measure fact extraction performance, ontology conformance, and hallucinations by LLMs. Furthermore, we provide results for two baseline models, Vicuna-13B and Alpaca-LoRA-13B using automatic prompt generation from test cases. The baseline results show that there is room for improvement using both Semantic Web and Natural Language Processing techniques.
Exploring In-Context Learning Capabilities of Foundation Models for Generating Knowledge Graphs from Text
May 15, 2023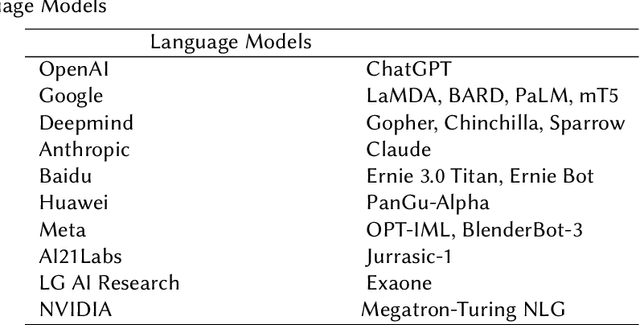
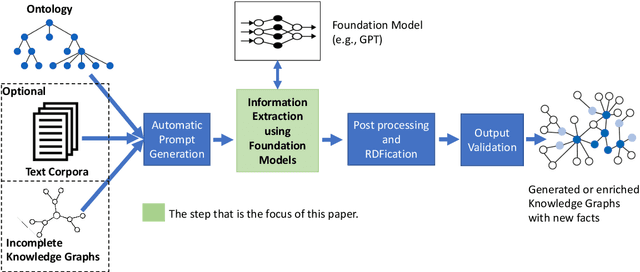

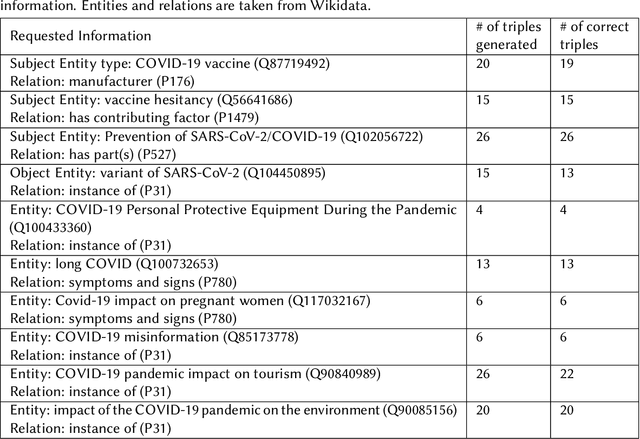
Knowledge graphs can represent information about the real-world using entities and their relations in a structured and semantically rich manner and they enable a variety of downstream applications such as question-answering, recommendation systems, semantic search, and advanced analytics. However, at the moment, building a knowledge graph involves a lot of manual effort and thus hinders their application in some situations and the automation of this process might benefit especially for small organizations. Automatically generating structured knowledge graphs from a large volume of natural language is still a challenging task and the research on sub-tasks such as named entity extraction, relation extraction, entity and relation linking, and knowledge graph construction aims to improve the state of the art of automatic construction and completion of knowledge graphs from text. The recent advancement of foundation models with billions of parameters trained in a self-supervised manner with large volumes of training data that can be adapted to a variety of downstream tasks has helped to demonstrate high performance on a large range of Natural Language Processing (NLP) tasks. In this context, one emerging paradigm is in-context learning where a language model is used as it is with a prompt that provides instructions and some examples to perform a task without changing the parameters of the model using traditional approaches such as fine-tuning. This way, no computing resources are needed for re-training/fine-tuning the models and the engineering effort is minimal. Thus, it would be beneficial to utilize such capabilities for generating knowledge graphs from text.