 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCardEst/QCardCorr: Quantum Cardinality Estimation and Correction
Sep 10, 2025Cardinality estimation is an important part of query optimization in DBMS. We develop a Quantum Cardinality Estimation (QCardEst) approach using Quantum Machine Learning with a Hybrid Quantum-Classical Network. We define a compact encoding for turning SQL queries into a quantum state, which requires only qubits equal to the number of tables in the query. This allows the processing of a complete query with a single variational quantum circuit (VQC) on current hardware. In addition, we compare multiple classical post-processing layers to turn the probability vector output of VQC into a cardinality value. We introduce Quantum Cardinality Correction QCardCorr, which improves classical cardinality estimators by multiplying the output with a factor generated by a VQC to improve the cardinality estimation. With QCardCorr, we have an improvement over the standard PostgreSQL optimizer of 6.37 times for JOB-light and 8.66 times for STATS. For JOB-light we even outperform MSCN by a factor of 3.47.
Automated Archival Descriptions with Federated Intelligence of LLMs
Apr 08, 2025



Enforcing archival standards requires specialized expertise, and manually creating metadata descriptions for archival materials is a tedious and error-prone task. This work aims at exploring the potential of agentic AI and large language models (LLMs) in addressing the challenges of implementing a standardized archival description process. To this end, we introduce an agentic AI-driven system for automated generation of high-quality metadata descriptions of archival materials. We develop a federated optimization approach that unites the intelligence of multiple LLMs to construct optimal archival metadata. We also suggest methods to overcome the challenges associated with using LLMs for consistent metadata generation. To evaluate the feasibility and effectiveness of our techniques, we conducted extensive experiments using a real-world dataset of archival materials, which covers a variety of document types and data formats. The evaluation results demonstrate the feasibility of our techniques and highlight the superior performance of the federated optimization approach compared to single-model solutions in metadata quality and reliability.
Variables are a Curse in Software Vulnerability Prediction
Jun 18, 2024Deep learning-based approaches for software vulnerability prediction currently mainly rely on the original text of software code as the feature of nodes in the graph of code and thus could learn a representation that is only specific to the code text, rather than the representation that depicts the 'intrinsic' functionality of a program hidden in the text representation. One curse that causes this problem is an infinite number of possibilities to name a variable. In order to lift the curse, in this work we introduce a new type of edge called name dependence, a type of abstract syntax graph based on the name dependence, and an efficient node representation method named 3-property encoding scheme. These techniques will allow us to remove the concrete variable names from code, and facilitate deep learning models to learn the functionality of software hidden in diverse code expressions. The experimental results show that the deep learning models built on these techniques outperform the ones based on existing approaches not only in the prediction of vulnerabilities but also in the memory need. The factor of memory usage reductions of our techniques can be up to the order of 30,000 in comparison to existing approaches.
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Jun 12, 2024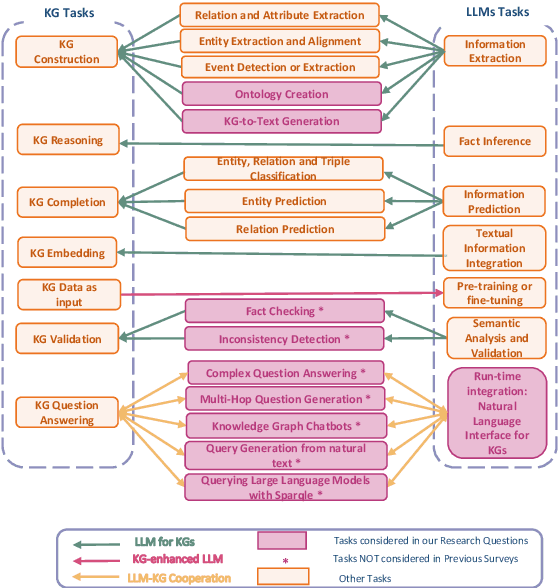
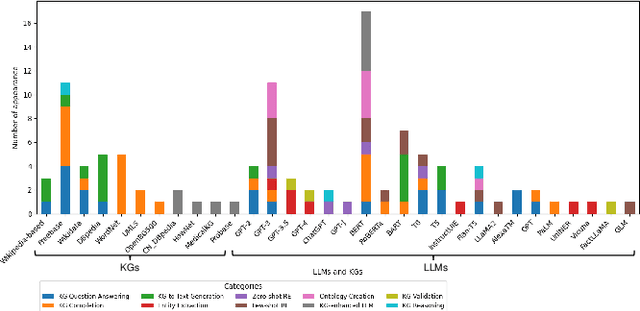
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
Exploring In-Context Learning Capabilities of Foundation Models for Generating Knowledge Graphs from Text
May 15, 2023
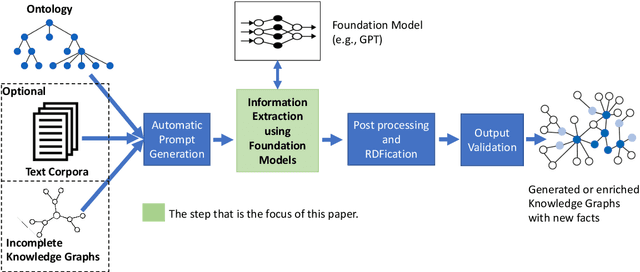

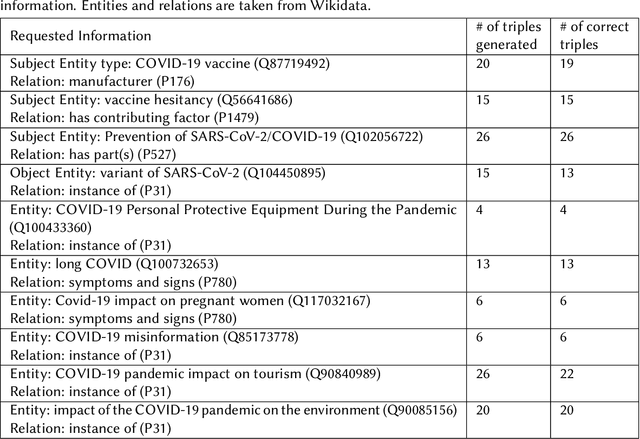
Knowledge graphs can represent information about the real-world using entities and their relations in a structured and semantically rich manner and they enable a variety of downstream applications such as question-answering, recommendation systems, semantic search, and advanced analytics. However, at the moment, building a knowledge graph involves a lot of manual effort and thus hinders their application in some situations and the automation of this process might benefit especially for small organizations. Automatically generating structured knowledge graphs from a large volume of natural language is still a challenging task and the research on sub-tasks such as named entity extraction, relation extraction, entity and relation linking, and knowledge graph construction aims to improve the state of the art of automatic construction and completion of knowledge graphs from text. The recent advancement of foundation models with billions of parameters trained in a self-supervised manner with large volumes of training data that can be adapted to a variety of downstream tasks has helped to demonstrate high performance on a large range of Natural Language Processing (NLP) tasks. In this context, one emerging paradigm is in-context learning where a language model is used as it is with a prompt that provides instructions and some examples to perform a task without changing the parameters of the model using traditional approaches such as fine-tuning. This way, no computing resources are needed for re-training/fine-tuning the models and the engineering effort is minimal. Thus, it would be beneficial to utilize such capabilities for generating knowledge graphs from text.