 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring In-Context Learning Capabilities of Foundation Models for Generating Knowledge Graphs from Text
Paper and Code
May 15, 2023
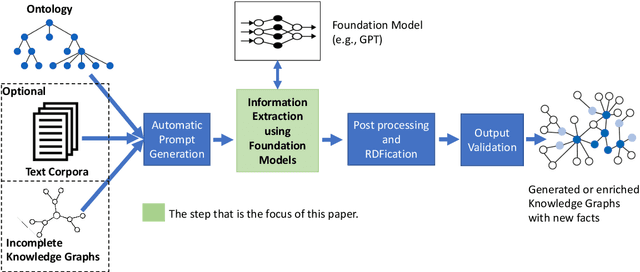

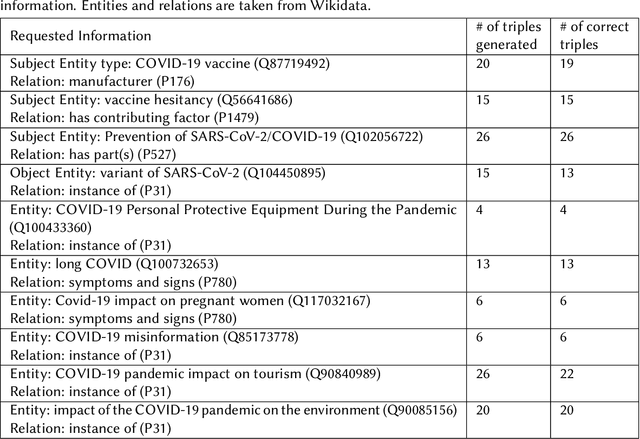
Knowledge graphs can represent information about the real-world using entities and their relations in a structured and semantically rich manner and they enable a variety of downstream applications such as question-answering, recommendation systems, semantic search, and advanced analytics. However, at the moment, building a knowledge graph involves a lot of manual effort and thus hinders their application in some situations and the automation of this process might benefit especially for small organizations. Automatically generating structured knowledge graphs from a large volume of natural language is still a challenging task and the research on sub-tasks such as named entity extraction, relation extraction, entity and relation linking, and knowledge graph construction aims to improve the state of the art of automatic construction and completion of knowledge graphs from text. The recent advancement of foundation models with billions of parameters trained in a self-supervised manner with large volumes of training data that can be adapted to a variety of downstream tasks has helped to demonstrate high performance on a large range of Natural Language Processing (NLP) tasks. In this context, one emerging paradigm is in-context learning where a language model is used as it is with a prompt that provides instructions and some examples to perform a task without changing the parameters of the model using traditional approaches such as fine-tuning. This way, no computing resources are needed for re-training/fine-tuning the models and the engineering effort is minimal. Thus, it would be beneficial to utilize such capabilities for generating knowledge graphs from text.