 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA First Step Towards Even More Sparse Encodings of Probability Distributions
Mar 31, 2026Real world scenarios can be captured with lifted probability distributions. However, distributions are usually encoded in a table or list, requiring an exponential number of values. Hence, we propose a method for extracting first-order formulas from probability distributions that require significantly less values by reducing the number of values in a distribution and then extracting, for each value, a logical formula to be further minimized. This reduction and minimization allows for increasing the sparsity in the encoding while also generalizing a given distribution. Our evaluation shows that sparsity can increase immensely by extracting a small set of short formulas while preserving core information.
* Published in ILP2021. The final authenticated publication is available online at https://doi.org/10.1007/978-3-030-97454-1_13
Denoising the Future: Top-p Distributions for Moving Through Time
Jun 09, 2025Inference in dynamic probabilistic models is a complex task involving expensive operations. In particular, for Hidden Markov Models, the whole state space has to be enumerated for advancing in time. Even states with negligible probabilities are considered, resulting in computational inefficiency and increased noise due to the propagation of unlikely probability mass. We propose to denoise the future and speed up inference by using only the top-p states, i.e., the most probable states with accumulated probability p. We show that the error introduced by using only the top-p states is bound by p and the so-called minimal mixing rate of the underlying model. Moreover, in our empirical evaluation, we show that we can expect speedups of at least an order of magnitude, while the error in terms of total variation distance is below 0.09.
Lifted Forward Planning in Relational Factored Markov Decision Processes with Concurrent Actions
May 28, 2025Decision making is a central problem in AI that can be formalized using a Markov Decision Process. A problem is that, with increasing numbers of (indistinguishable) objects, the state space grows exponentially. To compute policies, the state space has to be enumerated. Even more possibilities have to be enumerated if the size of the action space depends on the size of the state space, especially if we allow concurrent actions. To tackle the exponential blow-up in the action and state space, we present a first-order representation to store the spaces in polynomial instead of exponential size in the number of objects and introduce Foreplan, a relational forward planner, which uses this representation to efficiently compute policies for numerous indistinguishable objects and actions. Additionally, we introduce an even faster approximate version of Foreplan. Moreover, Foreplan identifies how many objects an agent should act on to achieve a certain task given restrictions. Further, we provide a theoretical analysis and an empirical evaluation of Foreplan, demonstrating a speedup of at least four orders of magnitude.
Approximate Lifted Model Construction
Apr 29, 2025



Probabilistic relational models such as parametric factor graphs enable efficient (lifted) inference by exploiting the indistinguishability of objects. In lifted inference, a representative of indistinguishable objects is used for computations. To obtain a relational (i.e., lifted) representation, the Advanced Colour Passing (ACP) algorithm is the state of the art. The ACP algorithm, however, requires underlying distributions, encoded as potential-based factorisations, to exactly match to identify and exploit indistinguishabilities. Hence, ACP is unsuitable for practical applications where potentials learned from data inevitably deviate even if associated objects are indistinguishable. To mitigate this problem, we introduce the $\varepsilon$-Advanced Colour Passing ($\varepsilon$-ACP) algorithm, which allows for a deviation of potentials depending on a hyperparameter $\varepsilon$. $\varepsilon$-ACP efficiently uncovers and exploits indistinguishabilities that are not exact. We prove that the approximation error induced by $\varepsilon$-ACP is strictly bounded and our experiments show that the approximation error is close to zero in practice.
Trace Gadgets: Minimizing Code Context for Machine Learning-Based Vulnerability Prediction
Apr 18, 2025



As the number of web applications and API endpoints exposed to the Internet continues to grow, so does the number of exploitable vulnerabilities. Manually identifying such vulnerabilities is tedious. Meanwhile, static security scanners tend to produce many false positives. While machine learning-based approaches are promising, they typically perform well only in scenarios where training and test data are closely related. A key challenge for ML-based vulnerability detection is providing suitable and concise code context, as excessively long contexts negatively affect the code comprehension capabilities of machine learning models, particularly smaller ones. This work introduces Trace Gadgets, a novel code representation that minimizes code context by removing non-related code. Trace Gadgets precisely capture the statements that cover the path to the vulnerability. As input for ML models, Trace Gadgets provide a minimal but complete context, thereby improving the detection performance. Moreover, we collect a large-scale dataset generated from real-world applications with manually curated labels to further improve the performance of ML-based vulnerability detectors. Our results show that state-of-the-art machine learning models perform best when using Trace Gadgets compared to previous code representations, surpassing the detection capabilities of industry-standard static scanners such as GitHub's CodeQL by at least 4% on a fully unseen dataset. By applying our framework to real-world applications, we identify and report previously unknown vulnerabilities in widely deployed software.
Lifted Model Construction without Normalisation: A Vectorised Approach to Exploit Symmetries in Factor Graphs
Nov 20, 2024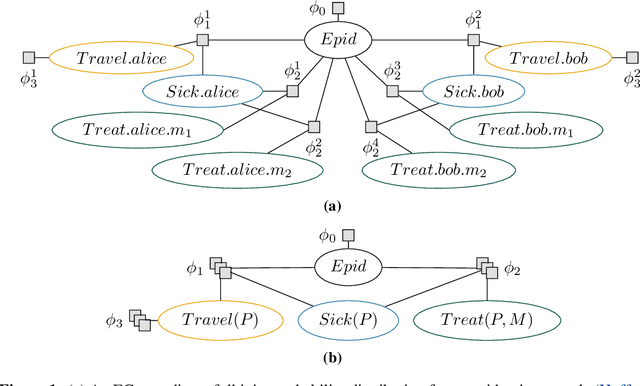
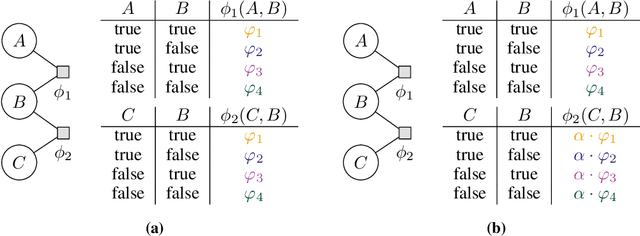
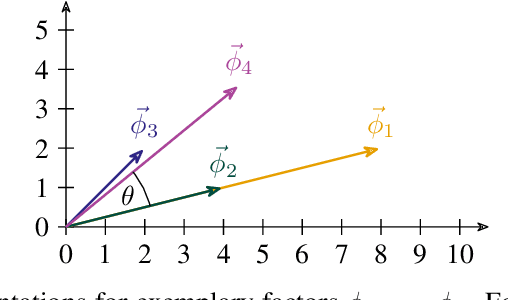

Lifted probabilistic inference exploits symmetries in a probabilistic model to allow for tractable probabilistic inference with respect to domain sizes of logical variables. We found that the current state-of-the-art algorithm to construct a lifted representation in form of a parametric factor graph misses symmetries between factors that are exchangeable but scaled differently, thereby leading to a less compact representation. In this paper, we propose a generalisation of the advanced colour passing (ACP) algorithm, which is the state of the art to construct a parametric factor graph. Our proposed algorithm allows for potentials of factors to be scaled arbitrarily and efficiently detects more symmetries than the original ACP algorithm. By detecting strictly more symmetries than ACP, our algorithm significantly reduces online query times for probabilistic inference when the resulting model is applied, which we also confirm in our experiments.
Estimating Causal Effects in Partially Directed Parametric Causal Factor Graphs
Nov 11, 2024Lifting uses a representative of indistinguishable individuals to exploit symmetries in probabilistic relational models, denoted as parametric factor graphs, to speed up inference while maintaining exact answers. In this paper, we show how lifting can be applied to causal inference in partially directed graphs, i.e., graphs that contain both directed and undirected edges to represent causal relationships between random variables. We present partially directed parametric causal factor graphs (PPCFGs) as a generalisation of previously introduced parametric causal factor graphs, which require a fully directed graph. We further show how causal inference can be performed on a lifted level in PPCFGs, thereby extending the applicability of lifted causal inference to a broader range of models requiring less prior knowledge about causal relationships.
Towards Privacy-Preserving Relational Data Synthesis via Probabilistic Relational Models
Sep 06, 2024Probabilistic relational models provide a well-established formalism to combine first-order logic and probabilistic models, thereby allowing to represent relationships between objects in a relational domain. At the same time, the field of artificial intelligence requires increasingly large amounts of relational training data for various machine learning tasks. Collecting real-world data, however, is often challenging due to privacy concerns, data protection regulations, high costs, and so on. To mitigate these challenges, the generation of synthetic data is a promising approach. In this paper, we solve the problem of generating synthetic relational data via probabilistic relational models. In particular, we propose a fully-fledged pipeline to go from relational database to probabilistic relational model, which can then be used to sample new synthetic relational data points from its underlying probability distribution. As part of our proposed pipeline, we introduce a learning algorithm to construct a probabilistic relational model from a given relational database.
Variables are a Curse in Software Vulnerability Prediction
Jun 18, 2024Deep learning-based approaches for software vulnerability prediction currently mainly rely on the original text of software code as the feature of nodes in the graph of code and thus could learn a representation that is only specific to the code text, rather than the representation that depicts the 'intrinsic' functionality of a program hidden in the text representation. One curse that causes this problem is an infinite number of possibilities to name a variable. In order to lift the curse, in this work we introduce a new type of edge called name dependence, a type of abstract syntax graph based on the name dependence, and an efficient node representation method named 3-property encoding scheme. These techniques will allow us to remove the concrete variable names from code, and facilitate deep learning models to learn the functionality of software hidden in diverse code expressions. The experimental results show that the deep learning models built on these techniques outperform the ones based on existing approaches not only in the prediction of vulnerabilities but also in the memory need. The factor of memory usage reductions of our techniques can be up to the order of 30,000 in comparison to existing approaches.
Lifting Factor Graphs with Some Unknown Factors
Jun 03, 2024Lifting exploits symmetries in probabilistic graphical models by using a representative for indistinguishable objects, allowing to carry out query answering more efficiently while maintaining exact answers. In this paper, we investigate how lifting enables us to perform probabilistic inference for factor graphs containing factors whose potentials are unknown. We introduce the Lifting Factor Graphs with Some Unknown Factors (LIFAGU) algorithm to identify symmetric subgraphs in a factor graph containing unknown factors, thereby enabling the transfer of known potentials to unknown potentials to ensure a well-defined semantics and allow for (lifted) probabilistic inference.