 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding pre-train LLM Dataset for the INDIC Languages: a case study on Hindi
Jul 13, 2024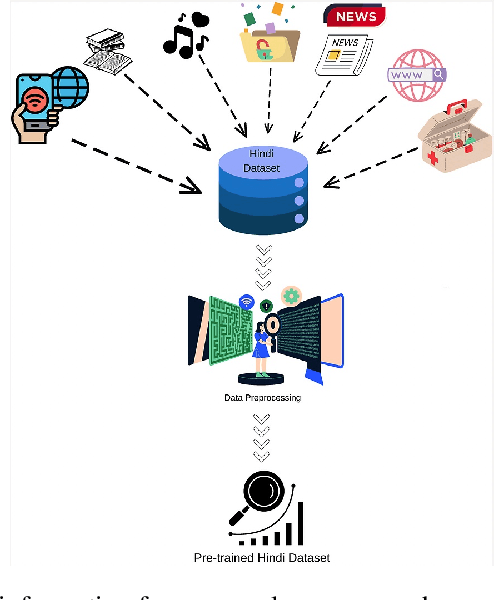
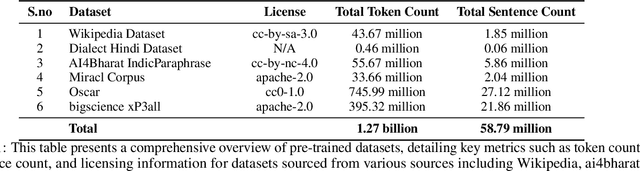
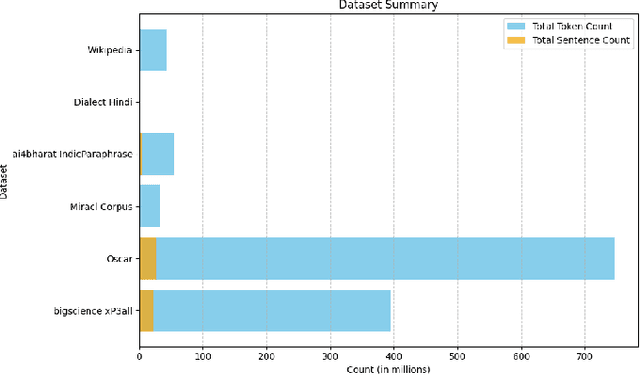
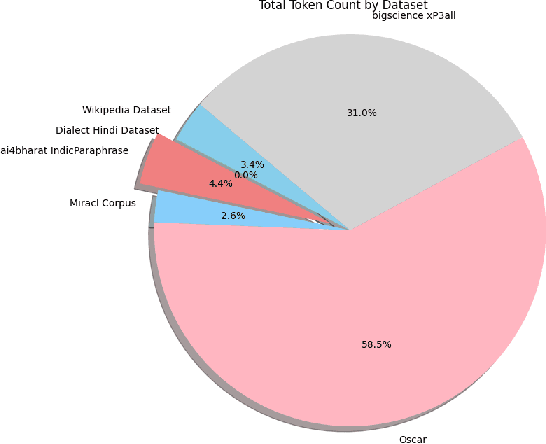
Large language models (LLMs) demonstrated transformative capabilities in many applications that require automatically generating responses based on human instruction. However, the major challenge for building LLMs, particularly in Indic languages, is the availability of high-quality data for building foundation LLMs. In this paper, we are proposing a large pre-train dataset in Hindi useful for the Indic language Hindi. We have collected the data span across several domains including major dialects in Hindi. The dataset contains 1.28 billion Hindi tokens. We have explained our pipeline including data collection, pre-processing, and availability for LLM pre-training. The proposed approach can be easily extended to other Indic and low-resource languages and will be available freely for LLM pre-training and LLM research purposes.
Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text
Aug 04, 2023
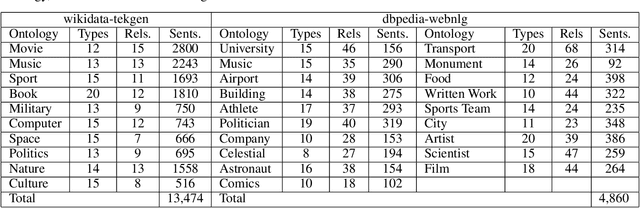


The recent advances in large language models (LLM) and foundation models with emergent capabilities have been shown to improve the performance of many NLP tasks. LLMs and Knowledge Graphs (KG) can complement each other such that LLMs can be used for KG construction or completion while existing KGs can be used for different tasks such as making LLM outputs explainable or fact-checking in Neuro-Symbolic manner. In this paper, we present Text2KGBench, a benchmark to evaluate the capabilities of language models to generate KGs from natural language text guided by an ontology. Given an input ontology and a set of sentences, the task is to extract facts from the text while complying with the given ontology (concepts, relations, domain/range constraints) and being faithful to the input sentences. We provide two datasets (i) Wikidata-TekGen with 10 ontologies and 13,474 sentences and (ii) DBpedia-WebNLG with 19 ontologies and 4,860 sentences. We define seven evaluation metrics to measure fact extraction performance, ontology conformance, and hallucinations by LLMs. Furthermore, we provide results for two baseline models, Vicuna-13B and Alpaca-LoRA-13B using automatic prompt generation from test cases. The baseline results show that there is room for improvement using both Semantic Web and Natural Language Processing techniques.
SMDDH: Singleton Mention detection using Deep Learning in Hindi Text
Jan 23, 2023Mention detection is an important component of coreference resolution system, where mentions such as name, nominal, and pronominals are identified. These mentions can be purely coreferential mentions or singleton mentions (non-coreferential mentions). Coreferential mentions are those mentions in a text that refer to the same entities in a real world. Whereas, singleton mentions are mentioned only once in the text and do not participate in the coreference as they are not mentioned again in the following text. Filtering of these singleton mentions can substantially improve the performance of a coreference resolution process. This paper proposes a singleton mention detection module based on a fully connected network and a Convolutional neural network for Hindi text. This model utilizes a few hand-crafted features and context information, and word embedding for words. The coreference annotated Hindi dataset comprising of 3.6K sentences, and 78K tokens are used for the task. In terms of Precision, Recall, and F-measure, the experimental findings obtained are excellent.