 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding pre-train LLM Dataset for the INDIC Languages: a case study on Hindi
Jul 13, 2024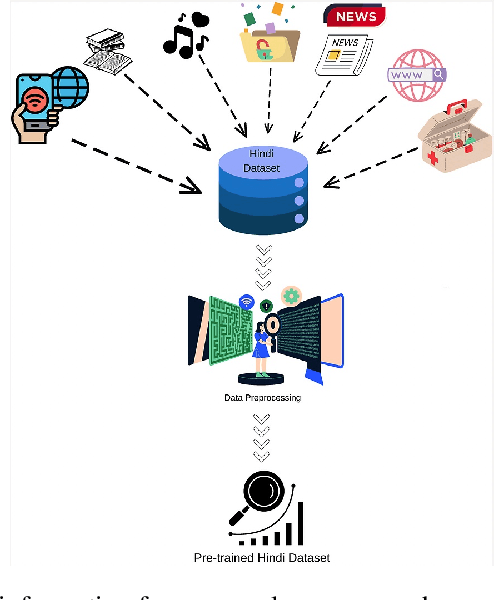
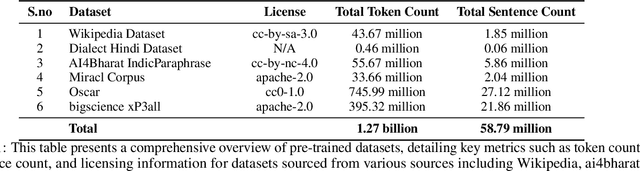
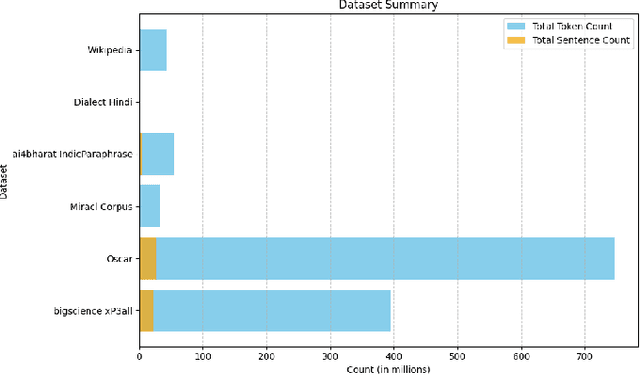
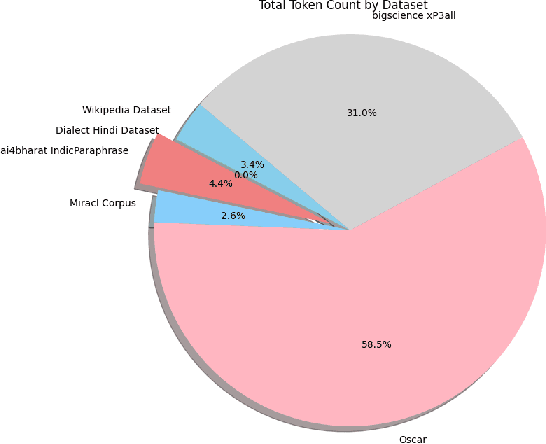
Large language models (LLMs) demonstrated transformative capabilities in many applications that require automatically generating responses based on human instruction. However, the major challenge for building LLMs, particularly in Indic languages, is the availability of high-quality data for building foundation LLMs. In this paper, we are proposing a large pre-train dataset in Hindi useful for the Indic language Hindi. We have collected the data span across several domains including major dialects in Hindi. The dataset contains 1.28 billion Hindi tokens. We have explained our pipeline including data collection, pre-processing, and availability for LLM pre-training. The proposed approach can be easily extended to other Indic and low-resource languages and will be available freely for LLM pre-training and LLM research purposes.
Building a Llama2-finetuned LLM for Odia Language Utilizing Domain Knowledge Instruction Set
Dec 19, 2023Building LLMs for languages other than English is in great demand due to the unavailability and performance of multilingual LLMs, such as understanding the local context. The problem is critical for low-resource languages due to the need for instruction sets. In a multilingual country like India, there is a need for LLMs supporting Indic languages to provide generative AI and LLM-based technologies and services to its citizens. This paper presents our approach of i) generating a large Odia instruction set, including domain knowledge data suitable for LLM fine-tuning, and ii) building a Llama2-finetuned model tailored for enhanced performance in the Odia domain. The proposed work will help researchers build an instruction set and LLM, particularly for Indic languages. We will release the model and instruction set for the public for research and noncommercial purposes.