 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Llama2-finetuned LLM for Odia Language Utilizing Domain Knowledge Instruction Set
Dec 19, 2023Building LLMs for languages other than English is in great demand due to the unavailability and performance of multilingual LLMs, such as understanding the local context. The problem is critical for low-resource languages due to the need for instruction sets. In a multilingual country like India, there is a need for LLMs supporting Indic languages to provide generative AI and LLM-based technologies and services to its citizens. This paper presents our approach of i) generating a large Odia instruction set, including domain knowledge data suitable for LLM fine-tuning, and ii) building a Llama2-finetuned model tailored for enhanced performance in the Odia domain. The proposed work will help researchers build an instruction set and LLM, particularly for Indic languages. We will release the model and instruction set for the public for research and noncommercial purposes.
HaVQA: A Dataset for Visual Question Answering and Multimodal Research in Hausa Language
May 28, 2023

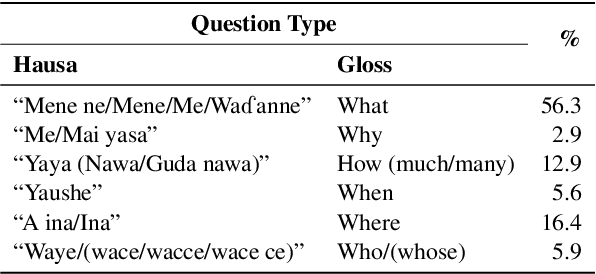
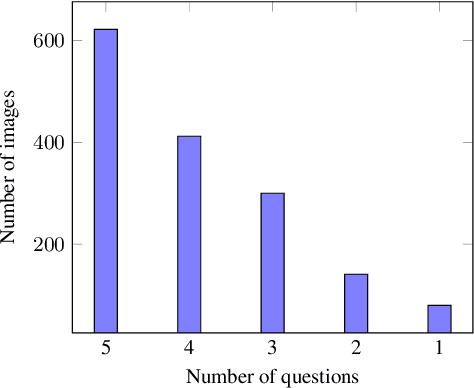
This paper presents HaVQA, the first multimodal dataset for visual question-answering (VQA) tasks in the Hausa language. The dataset was created by manually translating 6,022 English question-answer pairs, which are associated with 1,555 unique images from the Visual Genome dataset. As a result, the dataset provides 12,044 gold standard English-Hausa parallel sentences that were translated in a fashion that guarantees their semantic match with the corresponding visual information. We conducted several baseline experiments on the dataset, including visual question answering, visual question elicitation, text-only and multimodal machine translation.