 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Detection of Coronary Heart Disease Using Hybrid Quantum Machine Learning Approach
Sep 17, 2024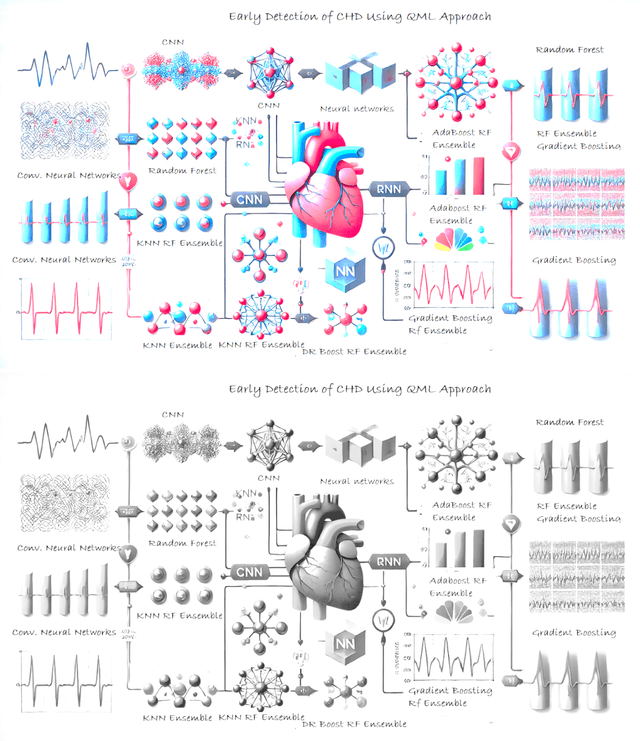



Coronary heart disease (CHD) is a severe cardiac disease, and hence, its early diagnosis is essential as it improves treatment results and saves money on medical care. The prevailing development of quantum computing and machine learning (ML) technologies may bring practical improvement to the performance of CHD diagnosis. Quantum machine learning (QML) is receiving tremendous interest in various disciplines due to its higher performance and capabilities. A quantum leap in the healthcare industry will increase processing power and optimise multiple models. Techniques for QML have the potential to forecast cardiac disease and help in early detection. To predict the risk of coronary heart disease, a hybrid approach utilizing an ensemble machine learning model based on QML classifiers is presented in this paper. Our approach, with its unique ability to address multidimensional healthcare data, reassures the method's robustness by fusing quantum and classical ML algorithms in a multi-step inferential framework. The marked rise in heart disease and death rates impacts worldwide human health and the global economy. Reducing cardiac morbidity and mortality requires early detection of heart disease. In this research, a hybrid approach utilizes techniques with quantum computing capabilities to tackle complex problems that are not amenable to conventional machine learning algorithms and to minimize computational expenses. The proposed method has been developed in the Raspberry Pi 5 Graphics Processing Unit (GPU) platform and tested on a broad dataset that integrates clinical and imaging data from patients suffering from CHD and healthy controls. Compared to classical machine learning models, the accuracy, sensitivity, F1 score, and specificity of the proposed hybrid QML model used with CHD are manifold higher.
Building a Llama2-finetuned LLM for Odia Language Utilizing Domain Knowledge Instruction Set
Dec 19, 2023Building LLMs for languages other than English is in great demand due to the unavailability and performance of multilingual LLMs, such as understanding the local context. The problem is critical for low-resource languages due to the need for instruction sets. In a multilingual country like India, there is a need for LLMs supporting Indic languages to provide generative AI and LLM-based technologies and services to its citizens. This paper presents our approach of i) generating a large Odia instruction set, including domain knowledge data suitable for LLM fine-tuning, and ii) building a Llama2-finetuned model tailored for enhanced performance in the Odia domain. The proposed work will help researchers build an instruction set and LLM, particularly for Indic languages. We will release the model and instruction set for the public for research and noncommercial purposes.
Issues,Challenges and Tools of Clustering Algorithms
Oct 12, 2011Clustering is an unsupervised technique of Data Mining. It means grouping similar objects together and separating the dissimilar ones. Each object in the data set is assigned a class label in the clustering process using a distance measure. This paper has captured the problems that are faced in real when clustering algorithms are implemented .It also considers the most extensively used tools which are readily available and support functions which ease the programming. Once algorithms have been implemented, they also need to be tested for its validity. There exist several validation indexes for testing the performance and accuracy which have also been discussed here.
* 6 PAGES