 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Deep Heteroskedastic Regression
Mar 02, 2026Uncertainty quantification (UQ) in deep learning regression is of wide interest, as it supports critical applications including sequential decision making and risk-sensitive tasks. In heteroskedastic regression, where the uncertainty of the target depends on the input, a common approach is to train a neural network that parameterizes the mean and the variance of the predictive distribution. Still, training deep heteroskedastic regression models poses practical challenges in the trade-off between uncertainty quantification and mean prediction, such as optimization difficulties, representation collapse, and variance overfitting. In this work we identify previously undiscussed fallacies and propose a simple and efficient procedure that addresses these challenges jointly by post-hoc fitting a variance model across the intermediate layers of a pretrained network on a hold-out dataset. We demonstrate that our method achieves on-par or state-of-the-art uncertainty quantification on several molecular graph datasets, without compromising mean prediction accuracy and remaining cheap to use at prediction time.
On Local Posterior Structure in Deep Ensembles
Mar 17, 2025Bayesian Neural Networks (BNNs) often improve model calibration and predictive uncertainty quantification compared to point estimators such as maximum-a-posteriori (MAP). Similarly, deep ensembles (DEs) are also known to improve calibration, and therefore, it is natural to hypothesize that deep ensembles of BNNs (DE-BNNs) should provide even further improvements. In this work, we systematically investigate this across a number of datasets, neural network architectures, and BNN approximation methods and surprisingly find that when the ensembles grow large enough, DEs consistently outperform DE-BNNs on in-distribution data. To shine light on this observation, we conduct several sensitivity and ablation studies. Moreover, we show that even though DE-BNNs outperform DEs on out-of-distribution metrics, this comes at the cost of decreased in-distribution performance. As a final contribution, we open-source the large pool of trained models to facilitate further research on this topic.
Neural machine translation for automated feedback on children's early-stage writing
Nov 15, 2023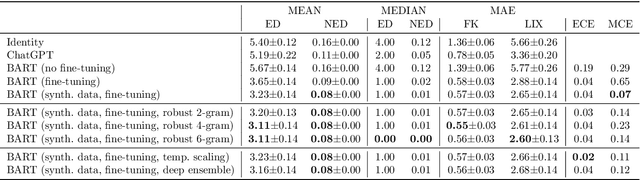
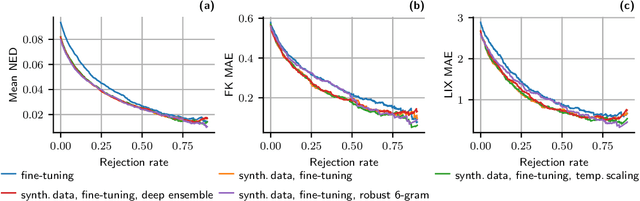
In this work, we address the problem of assessing and constructing feedback for early-stage writing automatically using machine learning. Early-stage writing is typically vastly different from conventional writing due to phonetic spelling and lack of proper grammar, punctuation, spacing etc. Consequently, early-stage writing is highly non-trivial to analyze using common linguistic metrics. We propose to use sequence-to-sequence models for "translating" early-stage writing by students into "conventional" writing, which allows the translated text to be analyzed using linguistic metrics. Furthermore, we propose a novel robust likelihood to mitigate the effect of noise in the dataset. We investigate the proposed methods using a set of numerical experiments and demonstrate that the conventional text can be predicted with high accuracy.