 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl-NeRF: Editable Feature Volumes for Scene Rendering and Manipulation
Apr 22, 2022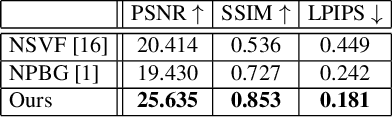
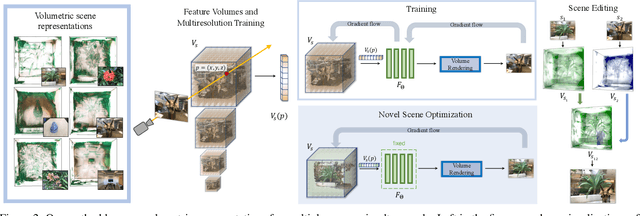
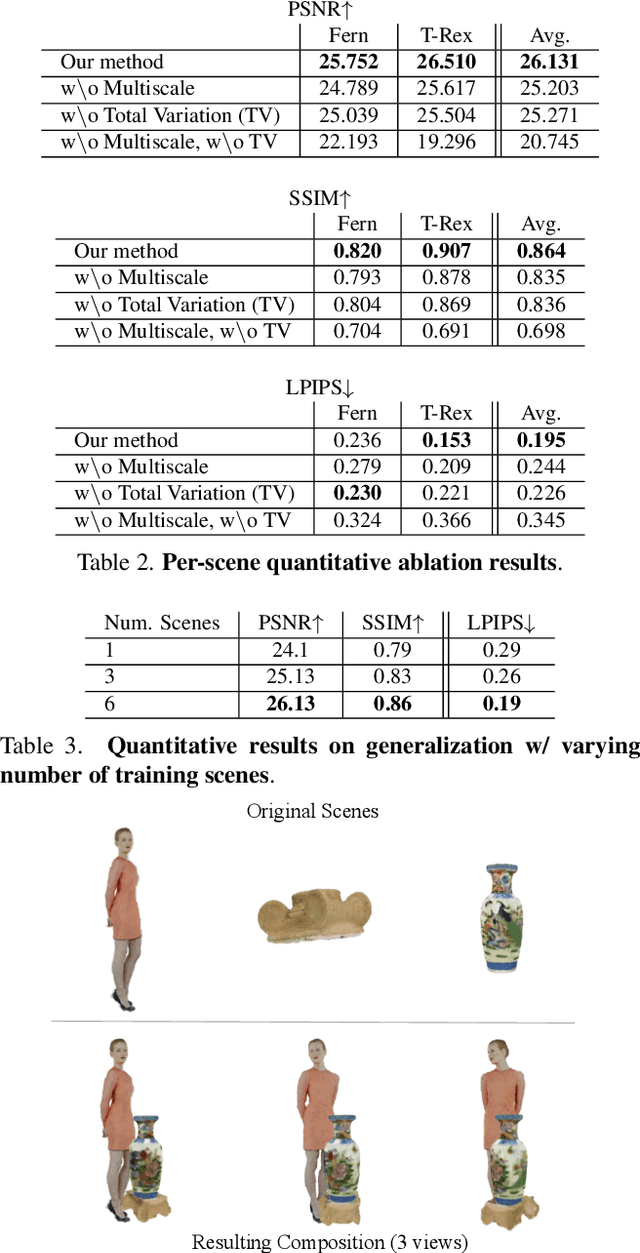

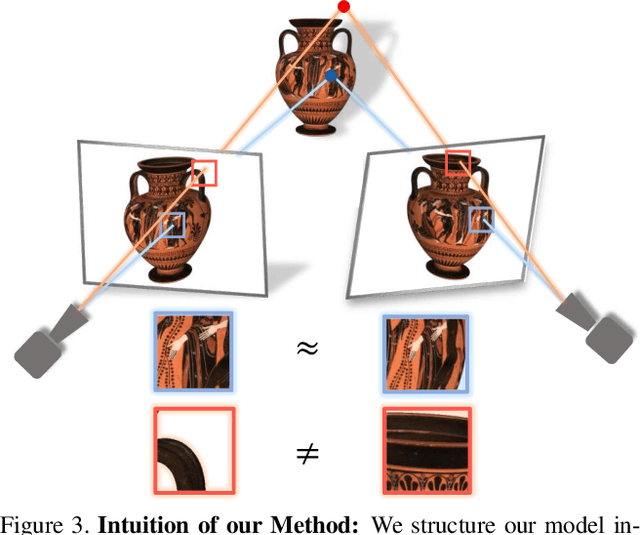
We present a novel method for performing flexible, 3D-aware image content manipulation while enabling high-quality novel view synthesis. While NeRF-based approaches are effective for novel view synthesis, such models memorize the radiance for every point in a scene within a neural network. Since these models are scene-specific and lack a 3D scene representation, classical editing such as shape manipulation, or combining scenes is not possible. Hence, editing and combining NeRF-based scenes has not been demonstrated. With the aim of obtaining interpretable and controllable scene representations, our model couples learnt scene-specific feature volumes with a scene agnostic neural rendering network. With this hybrid representation, we decouple neural rendering from scene-specific geometry and appearance. We can generalize to novel scenes by optimizing only the scene-specific 3D feature representation, while keeping the parameters of the rendering network fixed. The rendering function learnt during the initial training stage can thus be easily applied to new scenes, making our approach more flexible. More importantly, since the feature volumes are independent of the rendering model, we can manipulate and combine scenes by editing their corresponding feature volumes. The edited volume can then be plugged into the rendering model to synthesize high-quality novel views. We demonstrate various scene manipulations, including mixing scenes, deforming objects and inserting objects into scenes, while still producing photo-realistic results.
Stereo Radiance Fields (SRF): Learning View Synthesis for Sparse Views of Novel Scenes
Apr 14, 2021

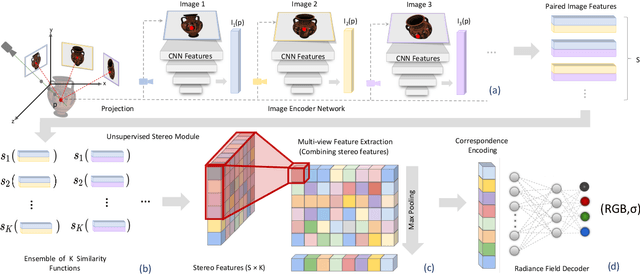
Recent neural view synthesis methods have achieved impressive quality and realism, surpassing classical pipelines which rely on multi-view reconstruction. State-of-the-Art methods, such as NeRF, are designed to learn a single scene with a neural network and require dense multi-view inputs. Testing on a new scene requires re-training from scratch, which takes 2-3 days. In this work, we introduce Stereo Radiance Fields (SRF), a neural view synthesis approach that is trained end-to-end, generalizes to new scenes, and requires only sparse views at test time. The core idea is a neural architecture inspired by classical multi-view stereo methods, which estimates surface points by finding similar image regions in stereo images. In SRF, we predict color and density for each 3D point given an encoding of its stereo correspondence in the input images. The encoding is implicitly learned by an ensemble of pair-wise similarities -- emulating classical stereo. Experiments show that SRF learns structure instead of overfitting on a scene. We train on multiple scenes of the DTU dataset and generalize to new ones without re-training, requiring only 10 sparse and spread-out views as input. We show that 10-15 minutes of fine-tuning further improve the results, achieving significantly sharper, more detailed results than scene-specific models. The code, model, and videos are available at https://virtualhumans.mpi-inf.mpg.de/srf/.
* IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
360-Degree Textures of People in Clothing from a Single Image
Aug 20, 2019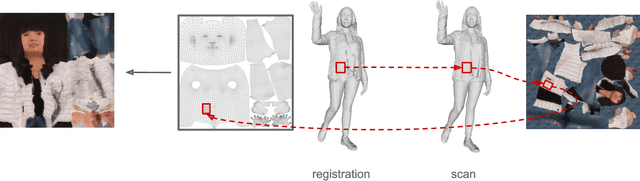

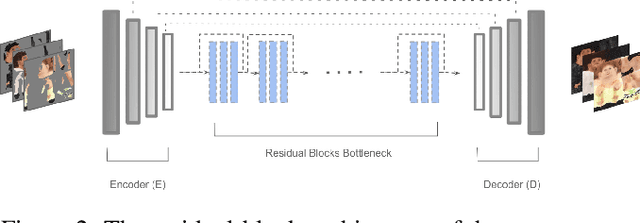
In this paper we predict a full 3D avatar of a person from a single image. We infer texture and geometry in the UV-space of the SMPL model using an image-to-image translation method. Given partial texture and segmentation layout maps derived from the input view, our model predicts the complete segmentation map, the complete texture map, and a displacement map. The predicted maps can be applied to the SMPL model in order to naturally generalize to novel poses, shapes, and even new clothing. In order to learn our model in a common UV-space, we non-rigidly register the SMPL model to thousands of 3D scans, effectively encoding textures and geometries as images in correspondence. This turns a difficult 3D inference task into a simpler image-to-image translation one. Results on rendered scans of people and images from the DeepFashion dataset demonstrate that our method can reconstruct plausible 3D avatars from a single image. We further use our model to digitally change pose, shape, swap garments between people and edit clothing. To encourage research in this direction we will make the source code available for research purpose.