 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360-Degree Textures of People in Clothing from a Single Image
Paper and Code
Aug 20, 2019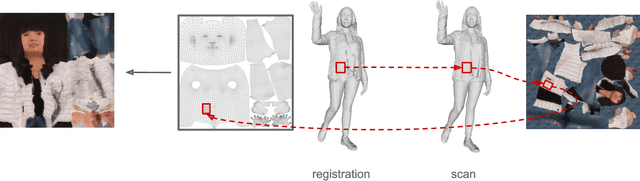

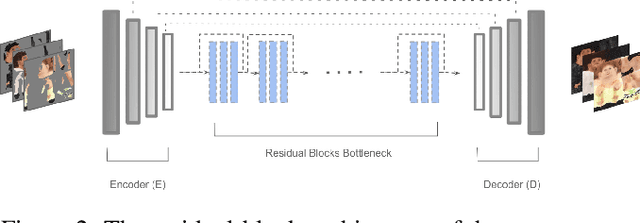
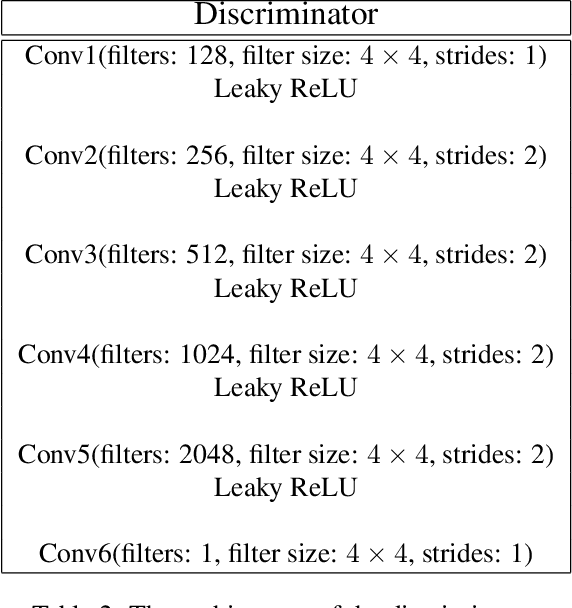
In this paper we predict a full 3D avatar of a person from a single image. We infer texture and geometry in the UV-space of the SMPL model using an image-to-image translation method. Given partial texture and segmentation layout maps derived from the input view, our model predicts the complete segmentation map, the complete texture map, and a displacement map. The predicted maps can be applied to the SMPL model in order to naturally generalize to novel poses, shapes, and even new clothing. In order to learn our model in a common UV-space, we non-rigidly register the SMPL model to thousands of 3D scans, effectively encoding textures and geometries as images in correspondence. This turns a difficult 3D inference task into a simpler image-to-image translation one. Results on rendered scans of people and images from the DeepFashion dataset demonstrate that our method can reconstruct plausible 3D avatars from a single image. We further use our model to digitally change pose, shape, swap garments between people and edit clothing. To encourage research in this direction we will make the source code available for research purpose.