 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Functions in Feature Space for 3D Shape Reconstruction and Completion
Paper and Code
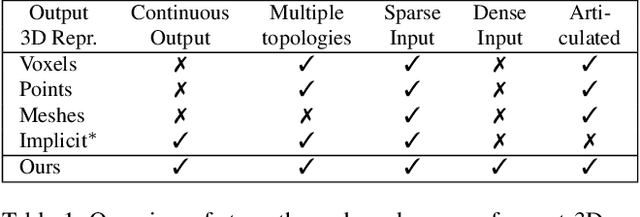
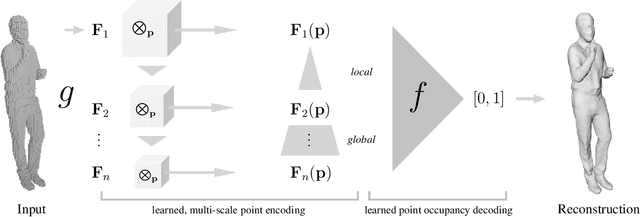
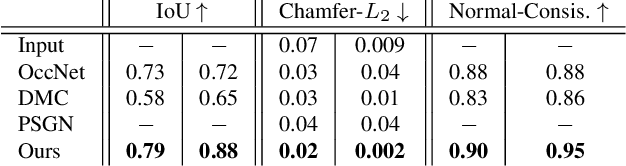
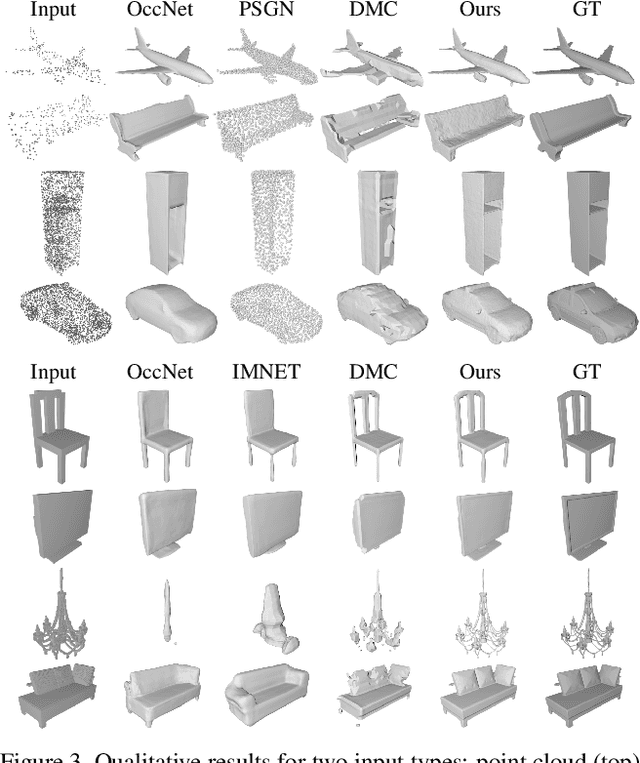
While many works focus on 3D reconstruction from images, in this paper, we focus on 3D shape reconstruction and completion from a variety of 3D inputs, which are deficient in some respect: low and high resolution voxels, sparse and dense point clouds, complete or incomplete. Processing of such 3D inputs is an increasingly important problem as they are the output of 3D scanners, which are becoming more accessible, and are the intermediate output of 3D computer vision algorithms. Recently, learned implicit functions have shown great promise as they produce continuous reconstructions. However, we identified two limitations in reconstruction from 3D inputs: 1) details present in the input data are not retained, and 2) poor reconstruction of articulated humans. To solve this, we propose Implicit Feature Networks (IF-Nets), which deliver continuous outputs, can handle multiple topologies, and complete shapes for missing or sparse input data retaining the nice properties of recent learned implicit functions, but critically they can also retain detail when it is present in the input data, and can reconstruct articulated humans. Our work differs from prior work in two crucial aspects. First, instead of using a single vector to encode a 3D shape, we extract a learnable 3-dimensional multi-scale tensor of deep features, which is aligned with the original Euclidean space embedding the shape. Second, instead of classifying x-y-z point coordinates directly, we classify deep features extracted from the tensor at a continuous query point. We show that this forces our model to make decisions based on global and local shape structure, as opposed to point coordinates, which are arbitrary under Euclidean transformations. Experiments demonstrate that IF-Nets clearly outperform prior work in 3D object reconstruction in ShapeNet, and obtain significantly more accurate 3D human reconstructions.