 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHabitat-GS: A High-Fidelity Navigation Simulator with Dynamic Gaussian Splatting
Apr 14, 2026Training embodied AI agents depends critically on the visual fidelity of simulation environments and the ability to model dynamic humans. Current simulators rely on mesh-based rasterization with limited visual realism, and their support for dynamic human avatars, where available, is constrained to mesh representations, hindering agent generalization to human-populated real-world scenarios. We present Habitat-GS, a navigation-centric embodied AI simulator extended from Habitat-Sim that integrates 3D Gaussian Splatting scene rendering and drivable gaussian avatars while maintaining full compatibility with the Habitat ecosystem. Our system implements a 3DGS renderer for real-time photorealistic rendering and supports scalable 3DGS asset import from diverse sources. For dynamic human modeling, we introduce a gaussian avatar module that enables each avatar to simultaneously serve as a photorealistic visual entity and an effective navigation obstacle, allowing agents to learn human-aware behaviors in realistic settings. Experiments on point-goal navigation demonstrate that agents trained on 3DGS scenes achieve stronger cross-domain generalization, with mixed-domain training being the most effective strategy. Evaluations on avatar-aware navigation further confirm that gaussian avatars enable effective human-aware navigation. Finally, performance benchmarks validate the system's scalability across varying scene complexity and avatar counts.
RA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories
Jun 18, 2025



Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have emerged as powerful tools for 3D reconstruction and SLAM tasks. However, their performance depends heavily on accurate camera pose priors. Existing approaches attempt to address this issue by introducing external constraints but fall short of achieving satisfactory accuracy, particularly when camera trajectories are complex. In this paper, we propose a novel method, RA-NeRF, capable of predicting highly accurate camera poses even with complex camera trajectories. Following the incremental pipeline, RA-NeRF reconstructs the scene using NeRF with photometric consistency and incorporates flow-driven pose regulation to enhance robustness during initialization and localization. Additionally, RA-NeRF employs an implicit pose filter to capture the camera movement pattern and eliminate the noise for pose estimation. To validate our method, we conduct extensive experiments on the Tanks\&Temple dataset for standard evaluation, as well as the NeRFBuster dataset, which presents challenging camera pose trajectories. On both datasets, RA-NeRF achieves state-of-the-art results in both camera pose estimation and visual quality, demonstrating its effectiveness and robustness in scene reconstruction under complex pose trajectories.
A Deep Single Image Rectification Approach for Pan-Tilt-Zoom Cameras
Apr 09, 2025Pan-Tilt-Zoom (PTZ) cameras with wide-angle lenses are widely used in surveillance but often require image rectification due to their inherent nonlinear distortions. Current deep learning approaches typically struggle to maintain fine-grained geometric details, resulting in inaccurate rectification. This paper presents a Forward Distortion and Backward Warping Network (FDBW-Net), a novel framework for wide-angle image rectification. It begins by using a forward distortion model to synthesize barrel-distorted images, reducing pixel redundancy and preventing blur. The network employs a pyramid context encoder with attention mechanisms to generate backward warping flows containing geometric details. Then, a multi-scale decoder is used to restore distorted features and output rectified images. FDBW-Net's performance is validated on diverse datasets: public benchmarks, AirSim-rendered PTZ camera imagery, and real-scene PTZ camera datasets. It demonstrates that FDBW-Net achieves SOTA performance in distortion rectification, boosting the adaptability of PTZ cameras for practical visual applications.
SphereFusion: Efficient Panorama Depth Estimation via Gated Fusion
Feb 09, 2025Due to the rapid development of panorama cameras, the task of estimating panorama depth has attracted significant attention from the computer vision community, especially in applications such as robot sensing and autonomous driving. However, existing methods relying on different projection formats often encounter challenges, either struggling with distortion and discontinuity in the case of equirectangular, cubemap, and tangent projections, or experiencing a loss of texture details with the spherical projection. To tackle these concerns, we present SphereFusion, an end-to-end framework that combines the strengths of various projection methods. Specifically, SphereFusion initially employs 2D image convolution and mesh operations to extract two distinct types of features from the panorama image in both equirectangular and spherical projection domains. These features are then projected onto the spherical domain, where a gate fusion module selects the most reliable features for fusion. Finally, SphereFusion estimates panorama depth within the spherical domain. Meanwhile, SphereFusion employs a cache strategy to improve the efficiency of mesh operation. Extensive experiments on three public panorama datasets demonstrate that SphereFusion achieves competitive results with other state-of-the-art methods, while presenting the fastest inference speed at only 17 ms on a 512$\times$1024 panorama image.
CF-NeRF: Camera Parameter Free Neural Radiance Fields with Incremental Learning
Dec 14, 2023Neural Radiance Fields (NeRF) have demonstrated impressive performance in novel view synthesis. However, NeRF and most of its variants still rely on traditional complex pipelines to provide extrinsic and intrinsic camera parameters, such as COLMAP. Recent works, like NeRFmm, BARF, and L2G-NeRF, directly treat camera parameters as learnable and estimate them through differential volume rendering. However, these methods work for forward-looking scenes with slight motions and fail to tackle the rotation scenario in practice. To overcome this limitation, we propose a novel \underline{c}amera parameter \underline{f}ree neural radiance field (CF-NeRF), which incrementally reconstructs 3D representations and recovers the camera parameters inspired by incremental structure from motion (SfM). Given a sequence of images, CF-NeRF estimates the camera parameters of images one by one and reconstructs the scene through initialization, implicit localization, and implicit optimization. To evaluate our method, we use a challenging real-world dataset NeRFBuster which provides 12 scenes under complex trajectories. Results demonstrate that CF-NeRF is robust to camera rotation and achieves state-of-the-art results without providing prior information and constraints.
Rethinking Disparity: A Depth Range Free Multi-View Stereo Based on Disparity
Dec 04, 2022



Existing learning-based multi-view stereo (MVS) methods rely on the depth range to build the 3D cost volume and may fail when the range is too large or unreliable. To address this problem, we propose a disparity-based MVS method based on the epipolar disparity flow (E-flow), called DispMVS, which infers the depth information from the pixel movement between two views. The core of DispMVS is to construct a 2D cost volume on the image plane along the epipolar line between each pair (between the reference image and several source images) for pixel matching and fuse uncountable depths triangulated from each pair by multi-view geometry to ensure multi-view consistency. To be robust, DispMVS starts from a randomly initialized depth map and iteratively refines the depth map with the help of the coarse-to-fine strategy. Experiments on DTUMVS and Tanks\&Temple datasets show that DispMVS is not sensitive to the depth range and achieves state-of-the-art results with lower GPU memory.
SphereDepth: Panorama Depth Estimation from Spherical Domain
Aug 30, 2022
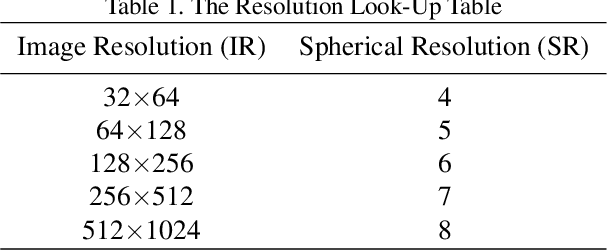
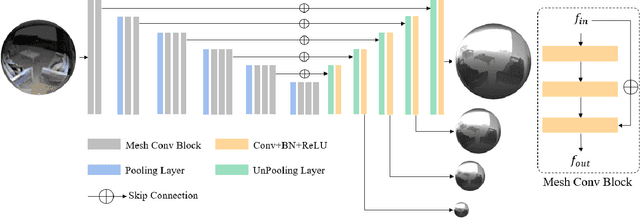
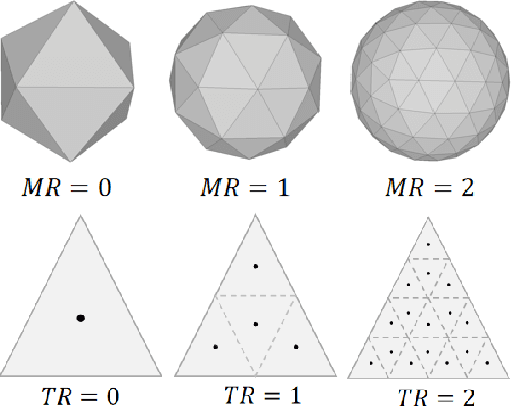
The panorama image can simultaneously demonstrate complete information of the surrounding environment and has many advantages in virtual tourism, games, robotics, etc. However, the progress of panorama depth estimation cannot completely solve the problems of distortion and discontinuity caused by the commonly used projection methods. This paper proposes SphereDepth, a novel panorama depth estimation method that predicts the depth directly on the spherical mesh without projection preprocessing. The core idea is to establish the relationship between the panorama image and the spherical mesh and then use a deep neural network to extract features on the spherical domain to predict depth. To address the efficiency challenges brought by the high-resolution panorama data, we introduce two hyper-parameters for the proposed spherical mesh processing framework to balance the inference speed and accuracy. Validated on three public panorama datasets, SphereDepth achieves comparable results with the state-of-the-art methods of panorama depth estimation. Benefiting from the spherical domain setting, SphereDepth can generate a high-quality point cloud and significantly alleviate the issues of distortion and discontinuity.
RC-MVSNet: Unsupervised Multi-View Stereo with Neural Rendering
Mar 14, 2022
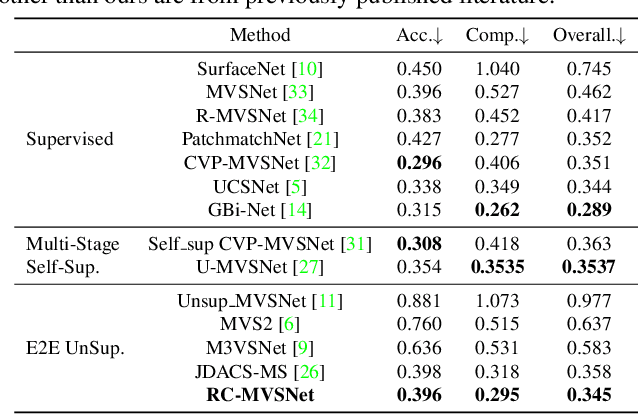
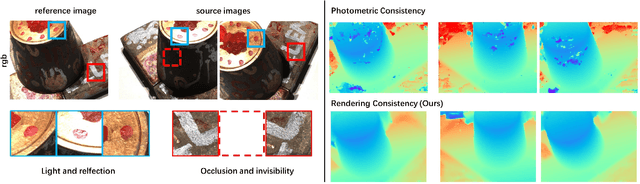
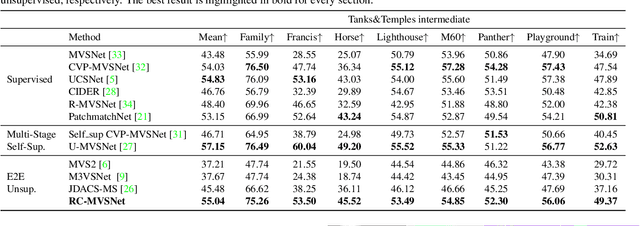
Finding accurate correspondences among different views is the Achilles' heel of unsupervised Multi-View Stereo (MVS). Existing methods are built upon the assumption that corresponding pixels share similar photometric features. However, multi-view images in real scenarios observe non-Lambertian surfaces and experience occlusions. In this work, we propose a novel approach with neural rendering (RC-MVSNet) to solve such ambiguity issues of correspondences among views. Specifically, we impose a depth rendering consistency loss to constrain the geometry features close to the object surface to alleviate occlusions. Concurrently, we introduce a reference view synthesis loss to generate consistent supervision, even for non-Lambertian surfaces. Extensive experiments on DTU and Tanks\&Temples benchmarks demonstrate that our RC-MVSNet approach achieves state-of-the-art performance over unsupervised MVS frameworks and competitive performance to many supervised methods.The trained models and code will be released at https://github.com/Boese0601/RC-MVSNet.
IRS: A Large Synthetic Indoor Robotics Stereo Dataset for Disparity and Surface Normal Estimation
Dec 20, 2019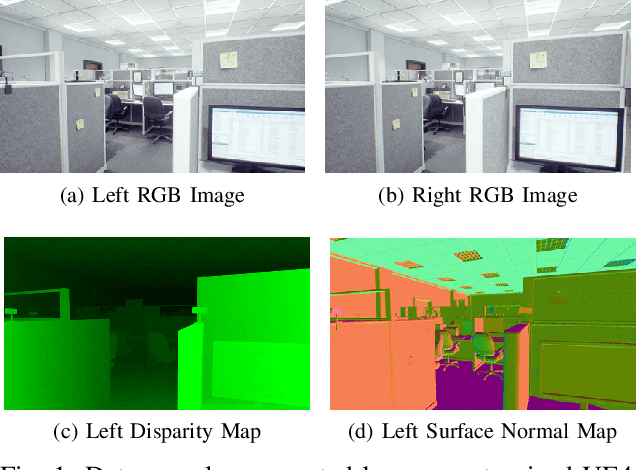


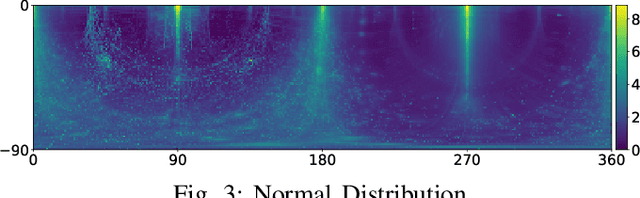
Indoor robotics localization, navigation and interaction heavily rely on scene understanding and reconstruction. Compared to monocular vision which usually does not explicitly introduce any geometrical constraint, stereo vision based schemes are more promising and robust to produce accurate geometrical information, such as surface normal and depth/disparity. Besides, deep learning models trained with large-scale datasets have shown their superior performance in many stereo vision tasks. However, existing stereo datasets rarely contain the high-quality surface normal and disparity ground truth, which hardly satisfy the demand of training a prospective deep model for indoor scenes. To this end, we introduce a large-scale synthetic indoor robotics stereo (IRS) dataset with over 100K stereo RGB images and high-quality surface normal and disparity maps. Leveraging the advanced rendering techniques of our customized rendering engine, the dataset is considerably close to the real-world captured images and covers several visual effects, such as brightness changes, light reflection/transmission, lens flare, vivid shadow, etc. We compare the data distribution of IRS with existing stereo datasets to illustrate the typical visual attributes of indoor scenes. In addition, we present a new deep model DispNormNet to simultaneously infer surface normal and disparity from stereo images. Compared to existing models trained on other datasets, DispNormNet trained with IRS produces much better estimation of surface normal and disparity for indoor scenes.