 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADNet++: Real-Time and Accurate Disparity Estimation with Configurable Networks
Oct 06, 2021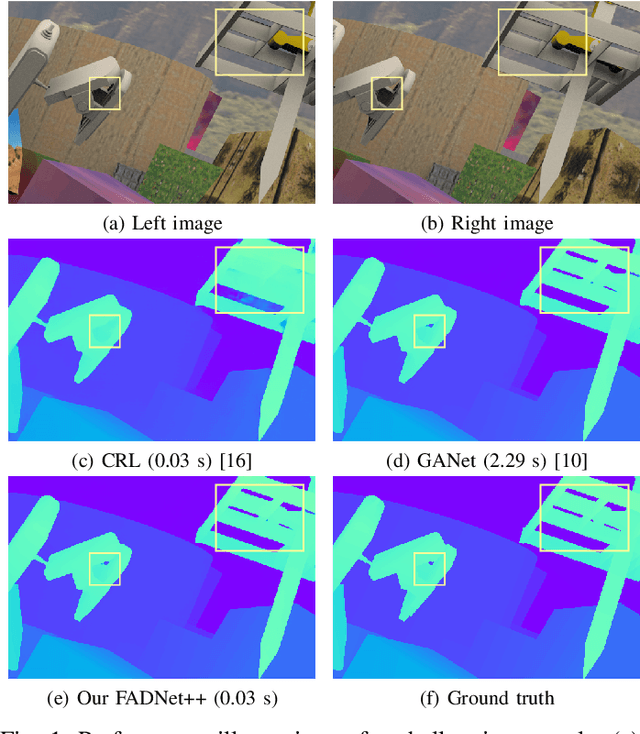
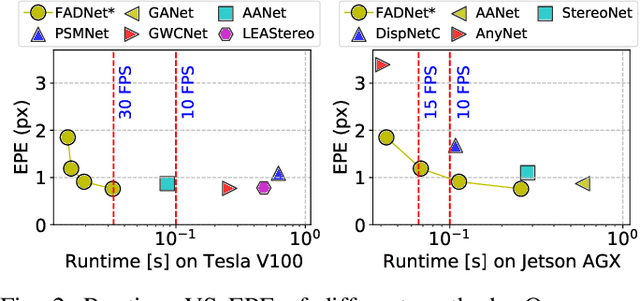
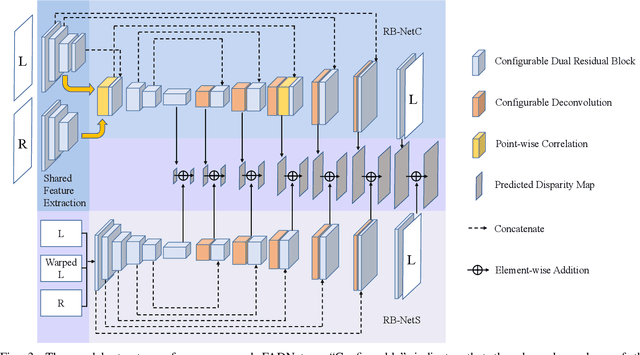
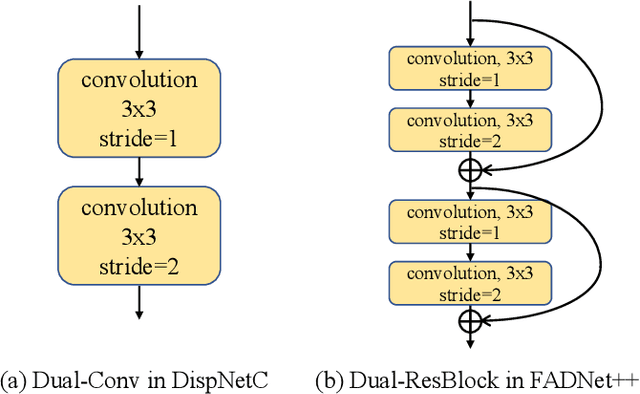
Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy than traditional hand-crafted feature-based methods. However, the existing DNNs hardly serve both efficient computation and rich expression capability, which makes them difficult for deployment in real-time and high-quality applications, especially on mobile devices. To this end, we propose an efficient, accurate, and configurable deep network for disparity estimation named FADNet++. Leveraging several liberal network design and training techniques, FADNet++ can boost its accuracy with a fast model inference speed for real-time applications. Besides, it enables users to easily configure different sizes of models for balancing accuracy and inference efficiency. We conduct extensive experiments to demonstrate the effectiveness of FADNet++ on both synthetic and realistic datasets among six GPU devices varying from server to mobile platforms. Experimental results show that FADNet++ and its variants achieve state-of-the-art prediction accuracy, and run at a significant order of magnitude faster speed than existing 3D models. With the constraint of running at above 15 frames per second (FPS) on a mobile GPU, FADNet++ achieves a new state-of-the-art result for the SceneFlow dataset.
FADNet: A Fast and Accurate Network for Disparity Estimation
Mar 24, 2020
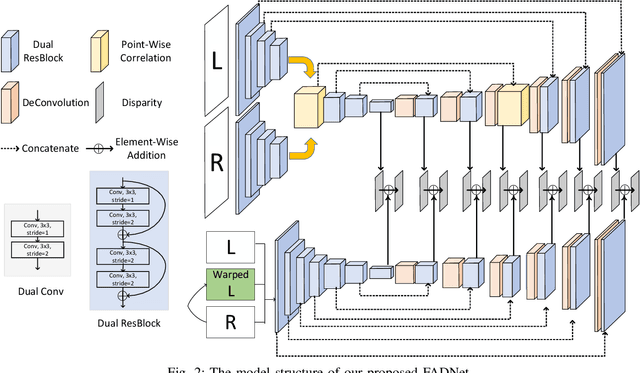


Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy in stereo matching than traditional hand-crafted feature based methods. On one hand, however, the designed DNNs require significant memory and computation resources to accurately predict the disparity, especially for those 3D convolution based networks, which makes it difficult for deployment in real-time applications. On the other hand, existing computation-efficient networks lack expression capability in large-scale datasets so that they cannot make an accurate prediction in many scenarios. To this end, we propose an efficient and accurate deep network for disparity estimation named FADNet with three main features: 1) It exploits efficient 2D based correlation layers with stacked blocks to preserve fast computation; 2) It combines the residual structures to make the deeper model easier to learn; 3) It contains multi-scale predictions so as to exploit a multi-scale weight scheduling training technique to improve the accuracy. We conduct experiments to demonstrate the effectiveness of FADNet on two popular datasets, Scene Flow and KITTI 2015. Experimental results show that FADNet achieves state-of-the-art prediction accuracy, and runs at a significant order of magnitude faster speed than existing 3D models. The codes of FADNet are available at https://github.com/HKBU-HPML/FADNet.
IRS: A Large Synthetic Indoor Robotics Stereo Dataset for Disparity and Surface Normal Estimation
Dec 20, 2019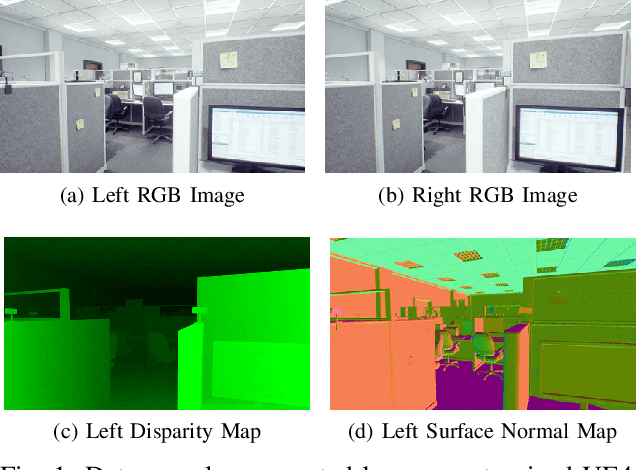


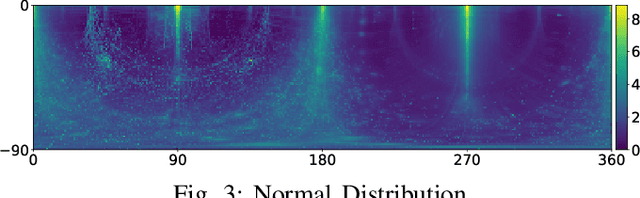
Indoor robotics localization, navigation and interaction heavily rely on scene understanding and reconstruction. Compared to monocular vision which usually does not explicitly introduce any geometrical constraint, stereo vision based schemes are more promising and robust to produce accurate geometrical information, such as surface normal and depth/disparity. Besides, deep learning models trained with large-scale datasets have shown their superior performance in many stereo vision tasks. However, existing stereo datasets rarely contain the high-quality surface normal and disparity ground truth, which hardly satisfy the demand of training a prospective deep model for indoor scenes. To this end, we introduce a large-scale synthetic indoor robotics stereo (IRS) dataset with over 100K stereo RGB images and high-quality surface normal and disparity maps. Leveraging the advanced rendering techniques of our customized rendering engine, the dataset is considerably close to the real-world captured images and covers several visual effects, such as brightness changes, light reflection/transmission, lens flare, vivid shadow, etc. We compare the data distribution of IRS with existing stereo datasets to illustrate the typical visual attributes of indoor scenes. In addition, we present a new deep model DispNormNet to simultaneously infer surface normal and disparity from stereo images. Compared to existing models trained on other datasets, DispNormNet trained with IRS produces much better estimation of surface normal and disparity for indoor scenes.