 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Hidden Parameter MDPs Transferable Model-based RL in a Handful of Trials
Feb 08, 2020
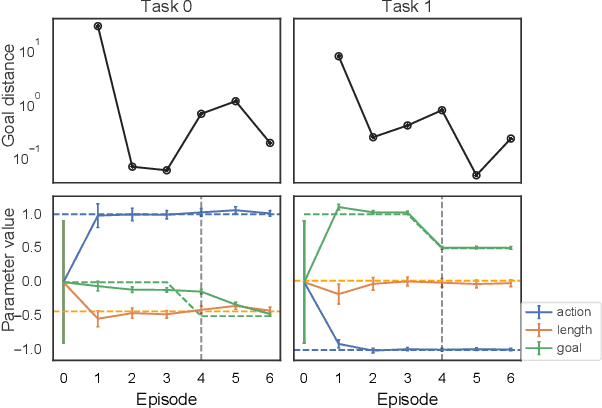

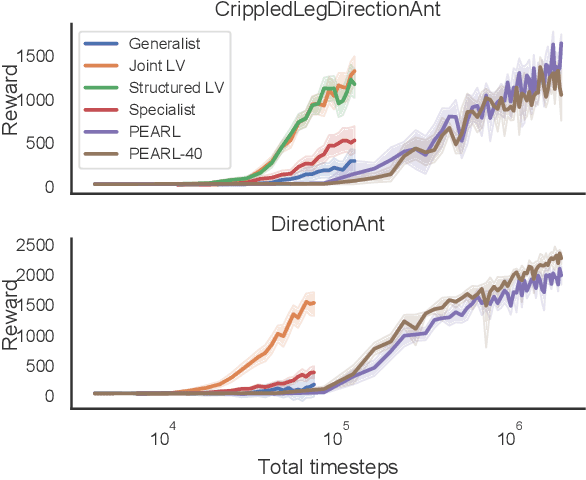
There is broad interest in creating RL agents that can solve many (related) tasks and adapt to new tasks and environments after initial training. Model-based RL leverages learned surrogate models that describe dynamics and rewards of individual tasks, such that planning in a good surrogate can lead to good control of the true system. Rather than solving each task individually from scratch, hierarchical models can exploit the fact that tasks are often related by (unobserved) causal factors of variation in order to achieve efficient generalization, as in learning how the mass of an item affects the force required to lift it can generalize to previously unobserved masses. We propose Generalized Hidden Parameter MDPs (GHP-MDPs) that describe a family of MDPs where both dynamics and reward can change as a function of hidden parameters that vary across tasks. The GHP-MDP augments model-based RL with latent variables that capture these hidden parameters, facilitating transfer across tasks. We also explore a variant of the model that incorporates explicit latent structure mirroring the causal factors of variation across tasks (for instance: agent properties, environmental factors, and goals). We experimentally demonstrate state-of-the-art performance and sample-efficiency on a new challenging MuJoCo task using reward and dynamics latent spaces, while beating a previous state-of-the-art baseline with $>10\times$ less data. Using test-time inference of the latent variables, our approach generalizes in a single episode to novel combinations of dynamics and reward, and to novel rewards.
Efficient transfer learning and online adaptation with latent variable models for continuous control
Dec 08, 2018

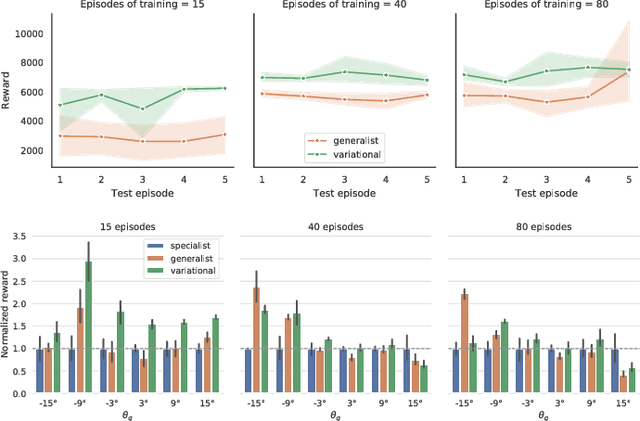
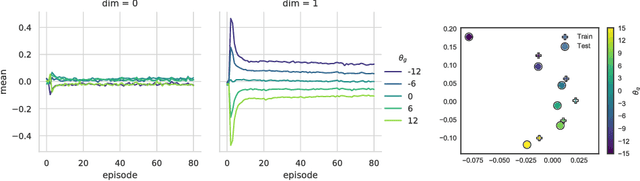
Traditional model-based RL relies on hand-specified or learned models of transition dynamics of the environment. These methods are sample efficient and facilitate learning in the real world but fail to generalize to subtle variations in the underlying dynamics, e.g., due to differences in mass, friction, or actuators across robotic agents or across time. We propose using variational inference to learn an explicit latent representation of unknown environment properties that accelerates learning and facilitates generalization on novel environments at test time. We use Online Bayesian Inference of these learned latents to rapidly adapt online to changes in environments without retaining large replay buffers of recent data. Combined with a neural network ensemble that models dynamics and captures uncertainty over dynamics, our approach demonstrates positive transfer during training and online adaptation on the continuous control task HalfCheetah.