 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Translate and Tell
Paper and Code
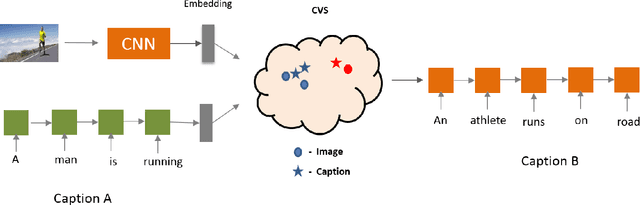
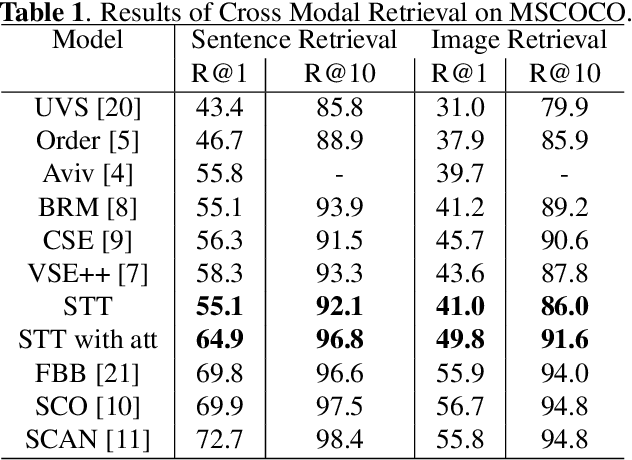
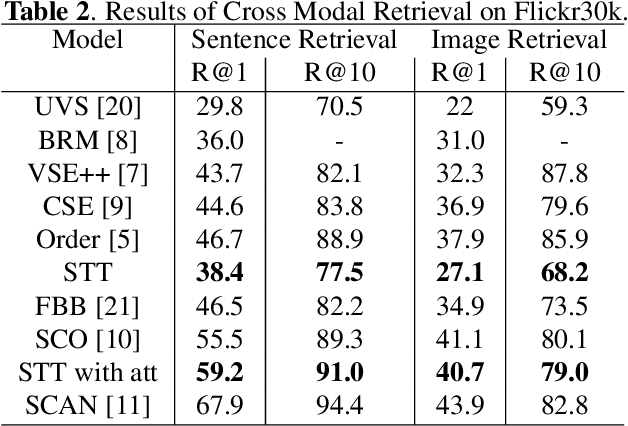
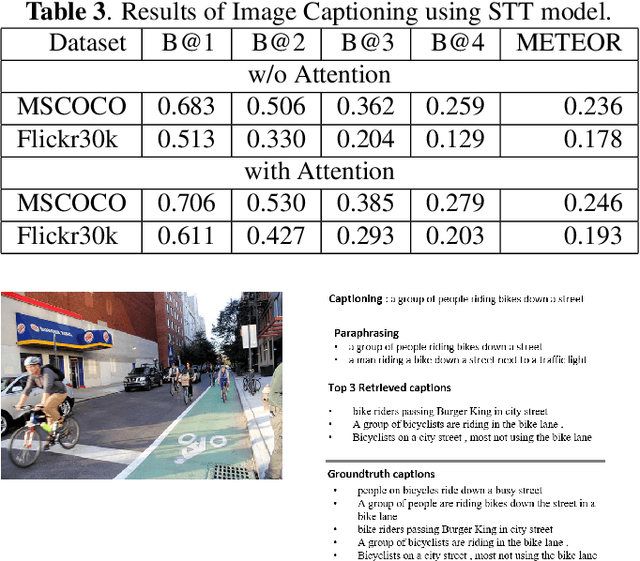
Humans have an incredible ability to process and understand information from multiple sources such as images, video, text, and speech. Recent success of deep neural networks has enabled us to develop algorithms which give machines the ability to understand and interpret this information. There is a need to both broaden their applicability and develop methods which correlate visual information along with semantic content. We propose a unified model which jointly trains on images and captions, and learns to generate new captions given either an image or a caption query. We evaluate our model on three different tasks namely cross-modal retrieval, image captioning, and sentence paraphrasing. Our model gains insight into cross-modal vector embeddings, generalizes well on multiple tasks and is competitive to state of the art methods on retrieval.