 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix-QSAM: Mixed-Precision Quantization of the Segment Anything Model
May 08, 2025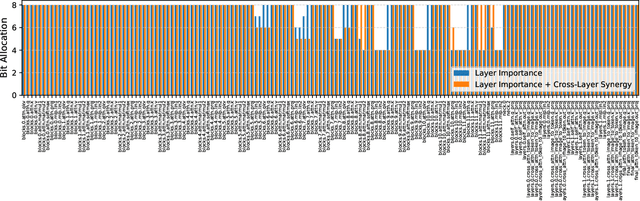
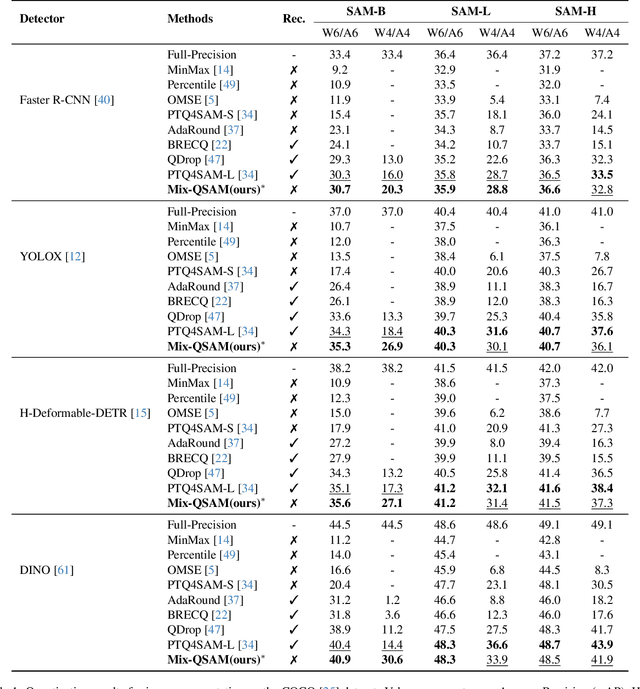
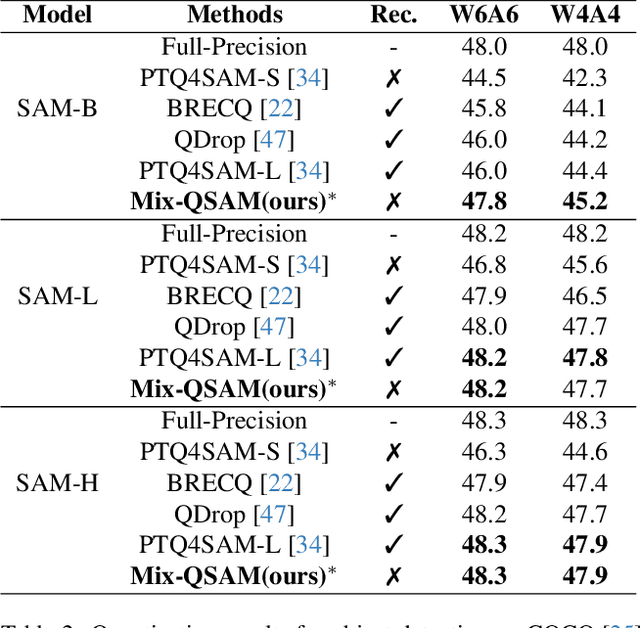

The Segment Anything Model (SAM) is a popular vision foundation model; however, its high computational and memory demands make deployment on resource-constrained devices challenging. While Post-Training Quantization (PTQ) is a practical approach for reducing computational overhead, existing PTQ methods rely on fixed bit-width quantization, leading to suboptimal accuracy and efficiency. To address this limitation, we propose Mix-QSAM, a mixed-precision PTQ framework for SAM. First, we introduce a layer-wise importance score, derived using Kullback-Leibler (KL) divergence, to quantify each layer's contribution to the model's output. Second, we introduce cross-layer synergy, a novel metric based on causal mutual information, to capture dependencies between adjacent layers. This ensures that highly interdependent layers maintain similar bit-widths, preventing abrupt precision mismatches that degrade feature propagation and numerical stability. Using these metrics, we formulate an Integer Quadratic Programming (IQP) problem to determine optimal bit-width allocation under model size and bit-operation constraints, assigning higher precision to critical layers while minimizing bit-width in less influential layers. Experimental results demonstrate that Mix-QSAM consistently outperforms existing PTQ methods on instance segmentation and object detection tasks, achieving up to 20% higher average precision under 6-bit and 4-bit mixed-precision settings, while maintaining computational efficiency.
Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven by Layer Importance and Quantization Sensitivity
Jan 10, 2025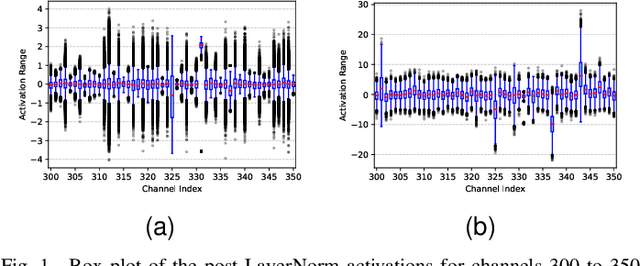
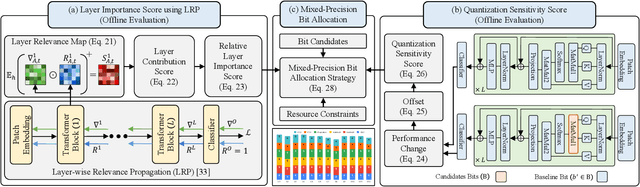
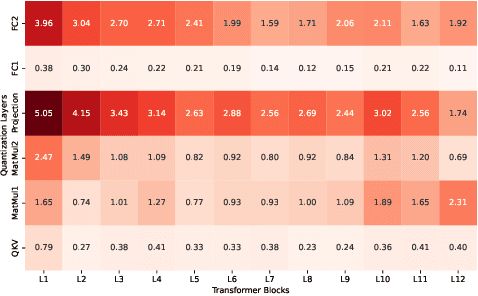
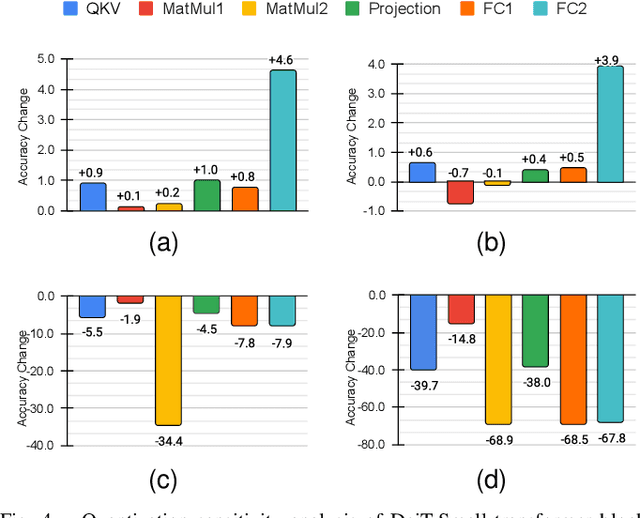
In this paper, we propose Mix-QViT, an explainability-driven MPQ framework that systematically allocates bit-widths to each layer based on two criteria: layer importance, assessed via Layer-wise Relevance Propagation (LRP), which identifies how much each layer contributes to the final classification, and quantization sensitivity, determined by evaluating the performance impact of quantizing each layer at various precision levels while keeping others layers at a baseline. Additionally, for post-training quantization (PTQ), we introduce a clipped channel-wise quantization method designed to reduce the effects of extreme outliers in post-LayerNorm activations by removing severe inter-channel variations. We validate our approach by applying Mix-QViT to ViT, DeiT, and Swin Transformer models across multiple datasets. Our experimental results for PTQ demonstrate that both fixed-bit and mixed-bit methods outperform existing techniques, particularly at 3-bit, 4-bit, and 6-bit precision. Furthermore, in quantization-aware training, Mix-QViT achieves superior performance with 2-bit mixed-precision.
Waterfall Transformer for Multi-person Pose Estimation
Nov 28, 2024
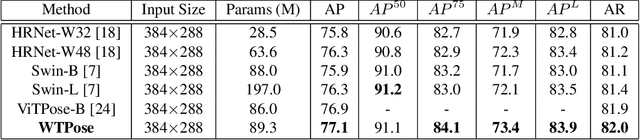
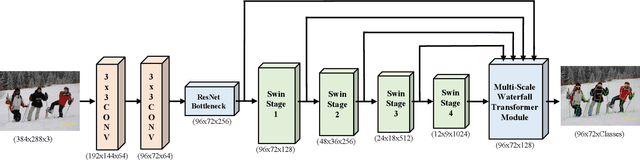
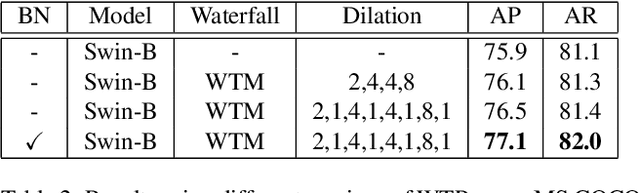
We propose the Waterfall Transformer architecture for Pose estimation (WTPose), a single-pass, end-to-end trainable framework designed for multi-person pose estimation. Our framework leverages a transformer-based waterfall module that generates multi-scale feature maps from various backbone stages. The module performs filtering in the cascade architecture to expand the receptive fields and to capture local and global context, therefore increasing the overall feature representation capability of the network. Our experiments on the COCO dataset demonstrate that the proposed WTPose architecture, with a modified Swin backbone and transformer-based waterfall module, outperforms other transformer architectures for multi-person pose estimation
MoPEFT: A Mixture-of-PEFTs for the Segment Anything Model
May 01, 2024The emergence of foundation models, such as the Segment Anything Model (SAM), has sparked interest in Parameter-Efficient Fine-Tuning (PEFT) methods that tailor these large models to application domains outside their training data. However, different PEFT techniques modify the representation of a model differently, making it a non-trivial task to select the most appropriate method for the domain of interest. We propose a new framework, Mixture-of-PEFTs methods (MoPEFT), that is inspired by traditional Mixture-of-Experts (MoE) methodologies and is utilized for fine-tuning SAM. Our MoPEFT framework incorporates three different PEFT techniques as submodules and dynamically learns to activate the ones that are best suited for a given data-task setup. We test our method on the Segment Anything Model and show that MoPEFT consistently outperforms other fine-tuning methods on the MESS benchmark.
LRP-QViT: Mixed-Precision Vision Transformer Quantization via Layer-wise Relevance Propagation
Jan 20, 2024Vision transformers (ViTs) have demonstrated remarkable performance across various visual tasks. However, ViT models suffer from substantial computational and memory requirements, making it challenging to deploy them on resource-constrained platforms. Quantization is a popular approach for reducing model size, but most studies mainly focus on equal bit-width quantization for the entire network, resulting in sub-optimal solutions. While there are few works on mixed precision quantization (MPQ) for ViTs, they typically rely on search space-based methods or employ mixed precision arbitrarily. In this paper, we introduce LRP-QViT, an explainability-based method for assigning mixed-precision bit allocations to different layers based on their importance during classification. Specifically, to measure the contribution score of each layer in predicting the target class, we employ the Layer-wise Relevance Propagation (LRP) method. LRP assigns local relevance at the output layer and propagates it through all layers, distributing the relevance until it reaches the input layers. These relevance scores serve as indicators for computing the layer contribution score. Additionally, we have introduced a clipped channel-wise quantization aimed at eliminating outliers from post-LayerNorm activations to alleviate severe inter-channel variations. To validate and assess our approach, we employ LRP-QViT across ViT, DeiT, and Swin transformer models on various datasets. Our experimental findings demonstrate that both our fixed-bit and mixed-bit post-training quantization methods surpass existing models in the context of 4-bit and 6-bit quantization.
Unknown Sample Discovery for Source Free Open Set Domain Adaptation
Dec 05, 2023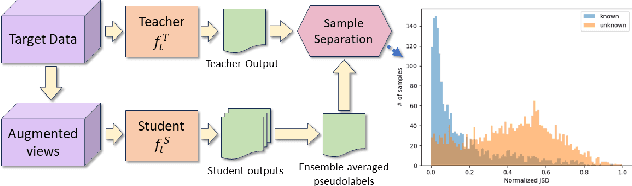
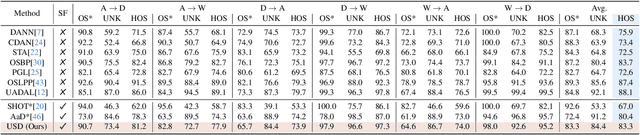
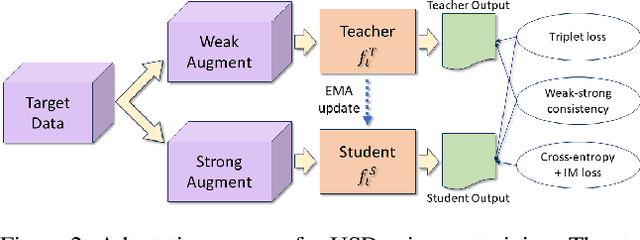
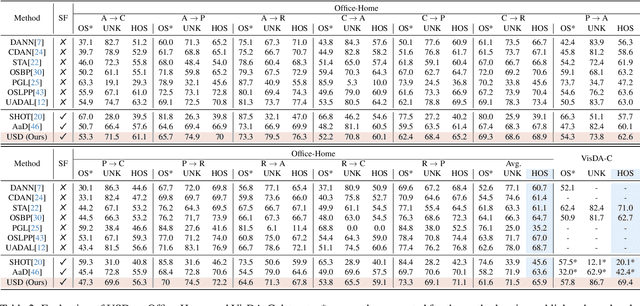
Open Set Domain Adaptation (OSDA) aims to adapt a model trained on a source domain to a target domain that undergoes distribution shift and contains samples from novel classes outside the source domain. Source-free OSDA (SF-OSDA) techniques eliminate the need to access source domain samples, but current SF-OSDA methods utilize only the known classes in the target domain for adaptation, and require access to the entire target domain even during inference after adaptation, to make the distinction between known and unknown samples. In this paper, we introduce Unknown Sample Discovery (USD) as an SF-OSDA method that utilizes a temporally ensembled teacher model to conduct known-unknown target sample separation and adapts the student model to the target domain over all classes using co-training and temporal consistency between the teacher and the student. USD promotes Jensen-Shannon distance (JSD) as an effective measure for known-unknown sample separation. Our teacher-student framework significantly reduces error accumulation resulting from imperfect known-unknown sample separation, while curriculum guidance helps to reliably learn the distinction between target known and target unknown subspaces. USD appends the target model with an unknown class node, thus readily classifying a target sample into any of the known or unknown classes in subsequent post-adaptation inference stages. Empirical results show that USD is superior to existing SF-OSDA methods and is competitive with current OSDA models that utilize both source and target domains during adaptation.
Continual Domain Adaptation on Aerial Images under Gradually Degrading Weather
Aug 14, 2023Domain adaptation (DA) strives to mitigate the domain gap between the source domain where a model is trained, and the target domain where the model is deployed. When a deep learning model is deployed on an aerial platform, it may face gradually degrading weather conditions during operation, leading to widening domain gaps between the training data and the encountered evaluation data. We synthesize two such gradually worsening weather conditions on real images from two existing aerial imagery datasets, generating a total of four benchmark datasets. Under the continual, or test-time adaptation setting, we evaluate three DA models on our datasets: a baseline standard DA model and two continual DA models. In such setting, the models can access only one small portion, or one batch of the target data at a time, and adaptation takes place continually, and over only one epoch of the data. The combination of the constraints of continual adaptation, and gradually deteriorating weather conditions provide the practical DA scenario for aerial deployment. Among the evaluated models, we consider both convolutional and transformer architectures for comparison. We discover stability issues during adaptation for existing buffer-fed continual DA methods, and offer gradient normalization as a simple solution to curb training instability.
Curriculum Guided Domain Adaptation in the Dark
Aug 02, 2023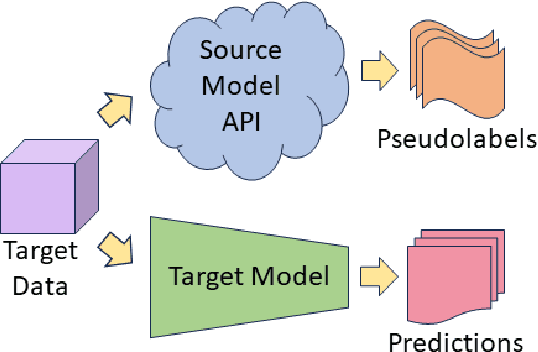
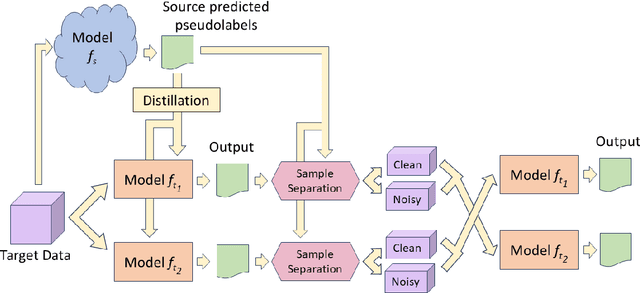
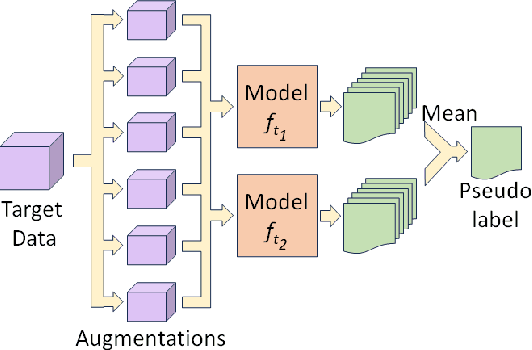
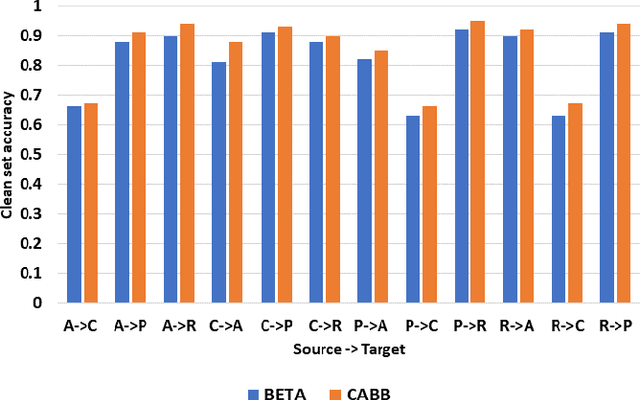
Addressing the rising concerns of privacy and security, domain adaptation in the dark aims to adapt a black-box source trained model to an unlabeled target domain without access to any source data or source model parameters. The need for domain adaptation of black-box predictors becomes even more pronounced to protect intellectual property as deep learning based solutions are becoming increasingly commercialized. Current methods distill noisy predictions on the target data obtained from the source model to the target model, and/or separate clean/noisy target samples before adapting using traditional noisy label learning algorithms. However, these methods do not utilize the easy-to-hard learning nature of the clean/noisy data splits. Also, none of the existing methods are end-to-end, and require a separate fine-tuning stage and an initial warmup stage. In this work, we present Curriculum Adaptation for Black-Box (CABB) which provides a curriculum guided adaptation approach to gradually train the target model, first on target data with high confidence (clean) labels, and later on target data with noisy labels. CABB utilizes Jensen-Shannon divergence as a better criterion for clean-noisy sample separation, compared to the traditional criterion of cross entropy loss. Our method utilizes co-training of a dual-branch network to suppress error accumulation resulting from confirmation bias. The proposed approach is end-to-end trainable and does not require any extra finetuning stage, unlike existing methods. Empirical results on standard domain adaptation datasets show that CABB outperforms existing state-of-the-art black-box DA models and is comparable to white-box domain adaptation models.
DeepRM: Deep Recurrent Matching for 6D Pose Refinement
Jun 07, 2022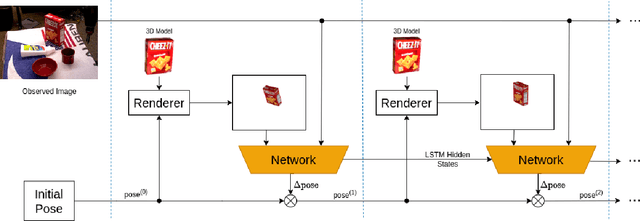
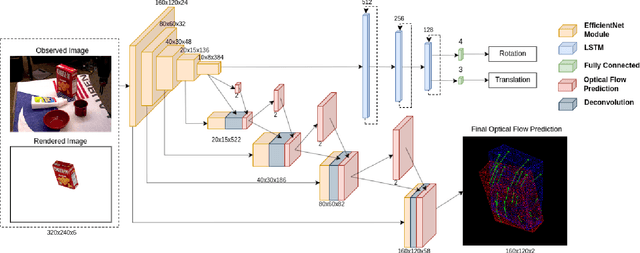
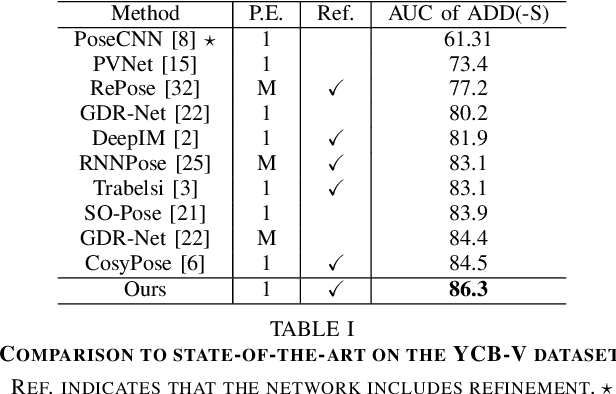
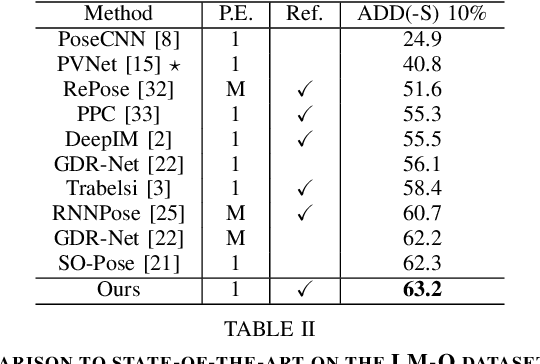
Precise 6D pose estimation of rigid objects from RGB images is a critical but challenging task in robotics and augmented reality. To address this problem, we propose DeepRM, a novel recurrent network architecture for 6D pose refinement. DeepRM leverages initial coarse pose estimates to render synthetic images of target objects. The rendered images are then matched with the observed images to predict a rigid transform for updating the previous pose estimate. This process is repeated to incrementally refine the estimate at each iteration. LSTM units are used to propagate information through each refinement step, significantly improving overall performance. In contrast to many 2-stage Perspective-n-Point based solutions, DeepRM is trained end-to-end, and uses a scalable backbone that can be tuned via a single parameter for accuracy and efficiency. During training, a multi-scale optical flow head is added to predict the optical flow between the observed and synthetic images. Optical flow prediction stabilizes the training process, and enforces the learning of features that are relevant to the task of pose estimation. Our results demonstrate that DeepRM achieves state-of-the-art performance on two widely accepted challenging datasets.
BAPose: Bottom-Up Pose Estimation with Disentangled Waterfall Representations
Dec 20, 2021
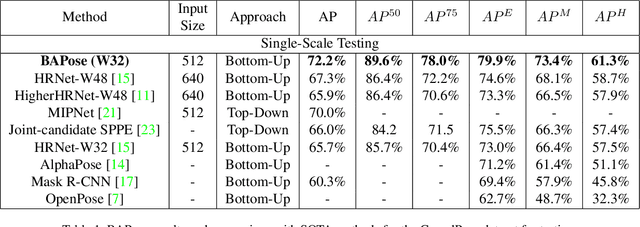
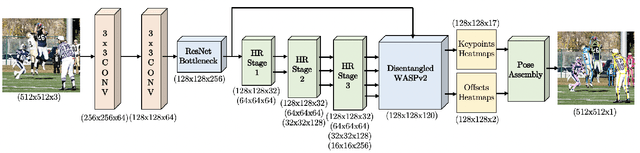
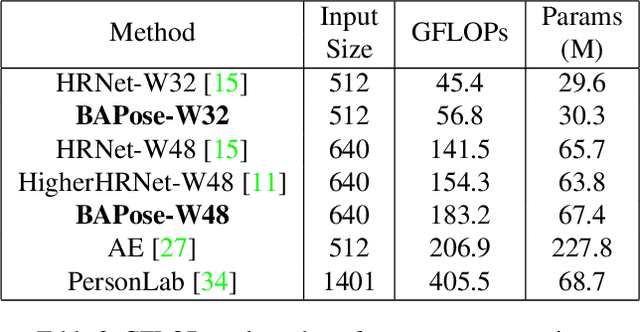
We propose BAPose, a novel bottom-up approach that achieves state-of-the-art results for multi-person pose estimation. Our end-to-end trainable framework leverages a disentangled multi-scale waterfall architecture and incorporates adaptive convolutions to infer keypoints more precisely in crowded scenes with occlusions. The multi-scale representations, obtained by the disentangled waterfall module in BAPose, leverage the efficiency of progressive filtering in the cascade architecture, while maintaining multi-scale fields-of-view comparable to spatial pyramid configurations. Our results on the challenging COCO and CrowdPose datasets demonstrate that BAPose is an efficient and robust framework for multi-person pose estimation, achieving significant improvements on state-of-the-art accuracy.