 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix-QViT: Mixed-Precision Vision Transformer Quantization Driven by Layer Importance and Quantization Sensitivity
Paper and Code
Jan 10, 2025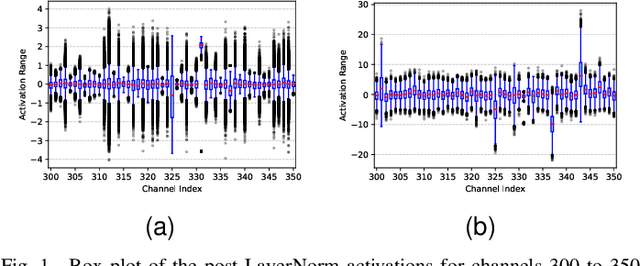
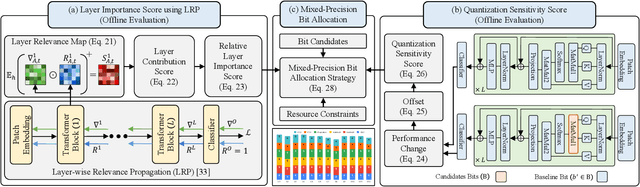
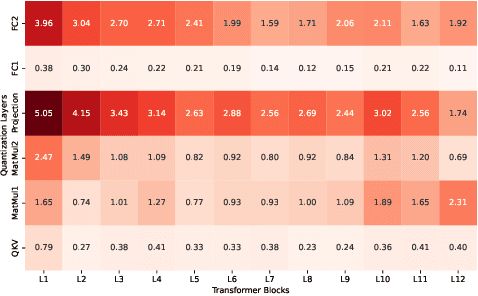
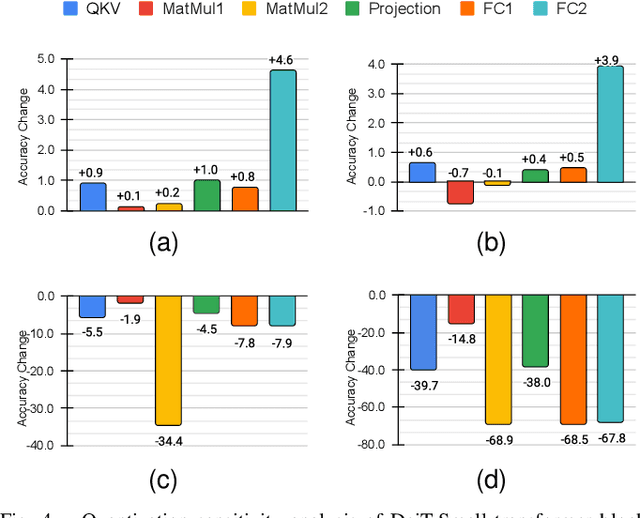
In this paper, we propose Mix-QViT, an explainability-driven MPQ framework that systematically allocates bit-widths to each layer based on two criteria: layer importance, assessed via Layer-wise Relevance Propagation (LRP), which identifies how much each layer contributes to the final classification, and quantization sensitivity, determined by evaluating the performance impact of quantizing each layer at various precision levels while keeping others layers at a baseline. Additionally, for post-training quantization (PTQ), we introduce a clipped channel-wise quantization method designed to reduce the effects of extreme outliers in post-LayerNorm activations by removing severe inter-channel variations. We validate our approach by applying Mix-QViT to ViT, DeiT, and Swin Transformer models across multiple datasets. Our experimental results for PTQ demonstrate that both fixed-bit and mixed-bit methods outperform existing techniques, particularly at 3-bit, 4-bit, and 6-bit precision. Furthermore, in quantization-aware training, Mix-QViT achieves superior performance with 2-bit mixed-precision.