 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix-QSAM: Mixed-Precision Quantization of the Segment Anything Model
May 08, 2025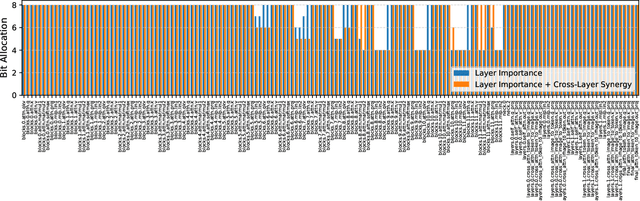
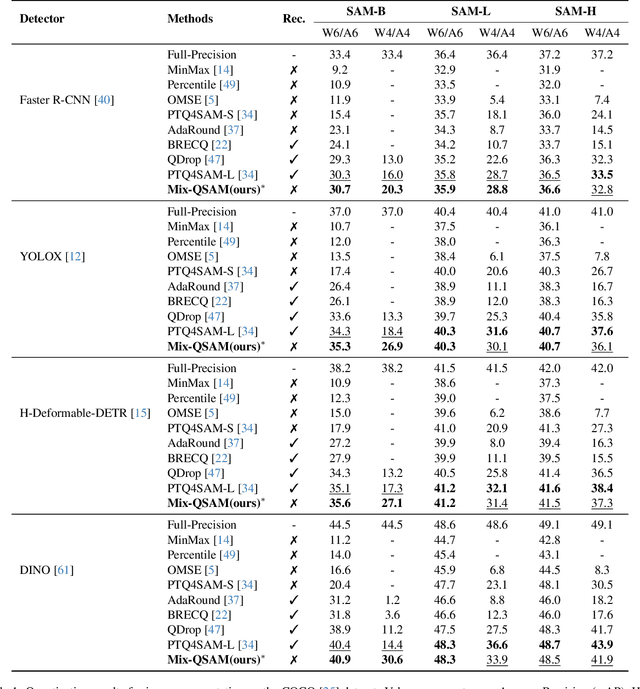
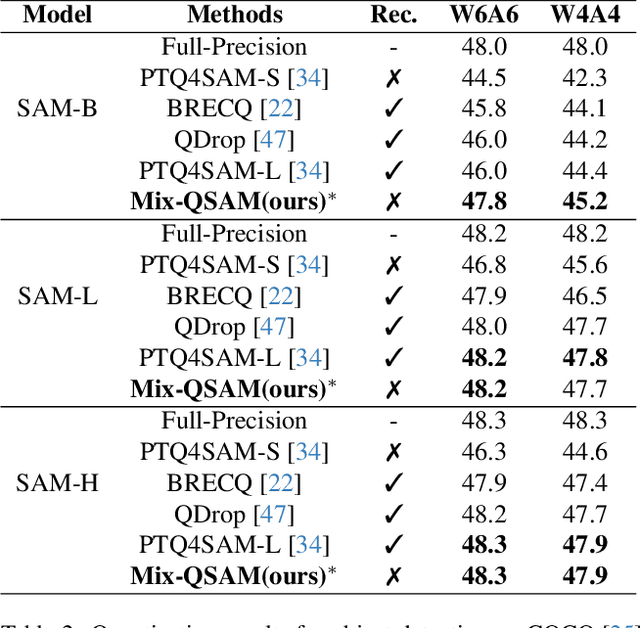

The Segment Anything Model (SAM) is a popular vision foundation model; however, its high computational and memory demands make deployment on resource-constrained devices challenging. While Post-Training Quantization (PTQ) is a practical approach for reducing computational overhead, existing PTQ methods rely on fixed bit-width quantization, leading to suboptimal accuracy and efficiency. To address this limitation, we propose Mix-QSAM, a mixed-precision PTQ framework for SAM. First, we introduce a layer-wise importance score, derived using Kullback-Leibler (KL) divergence, to quantify each layer's contribution to the model's output. Second, we introduce cross-layer synergy, a novel metric based on causal mutual information, to capture dependencies between adjacent layers. This ensures that highly interdependent layers maintain similar bit-widths, preventing abrupt precision mismatches that degrade feature propagation and numerical stability. Using these metrics, we formulate an Integer Quadratic Programming (IQP) problem to determine optimal bit-width allocation under model size and bit-operation constraints, assigning higher precision to critical layers while minimizing bit-width in less influential layers. Experimental results demonstrate that Mix-QSAM consistently outperforms existing PTQ methods on instance segmentation and object detection tasks, achieving up to 20% higher average precision under 6-bit and 4-bit mixed-precision settings, while maintaining computational efficiency.
Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven by Layer Importance and Quantization Sensitivity
Jan 10, 2025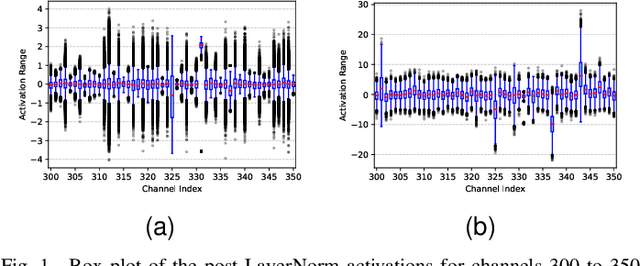
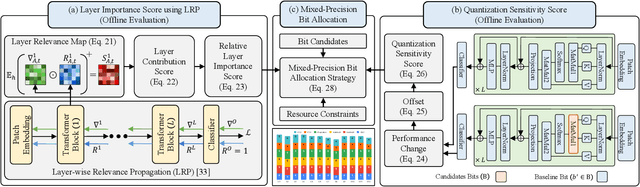
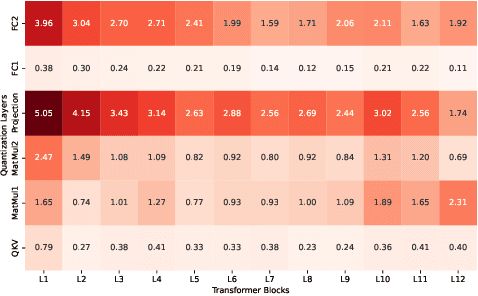
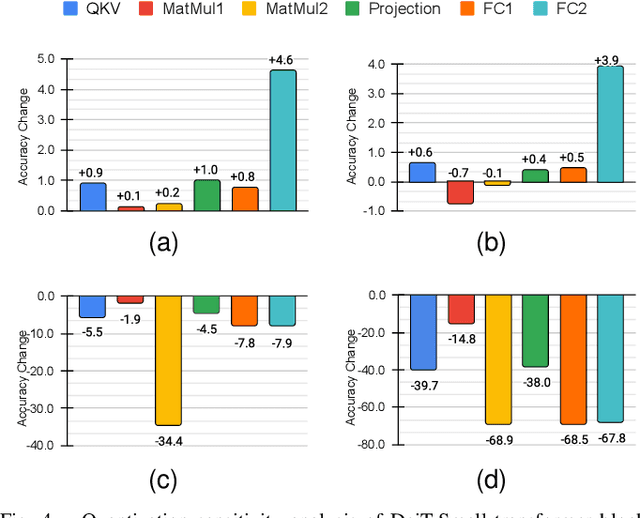
In this paper, we propose Mix-QViT, an explainability-driven MPQ framework that systematically allocates bit-widths to each layer based on two criteria: layer importance, assessed via Layer-wise Relevance Propagation (LRP), which identifies how much each layer contributes to the final classification, and quantization sensitivity, determined by evaluating the performance impact of quantizing each layer at various precision levels while keeping others layers at a baseline. Additionally, for post-training quantization (PTQ), we introduce a clipped channel-wise quantization method designed to reduce the effects of extreme outliers in post-LayerNorm activations by removing severe inter-channel variations. We validate our approach by applying Mix-QViT to ViT, DeiT, and Swin Transformer models across multiple datasets. Our experimental results for PTQ demonstrate that both fixed-bit and mixed-bit methods outperform existing techniques, particularly at 3-bit, 4-bit, and 6-bit precision. Furthermore, in quantization-aware training, Mix-QViT achieves superior performance with 2-bit mixed-precision.
Waterfall Transformer for Multi-person Pose Estimation
Nov 28, 2024
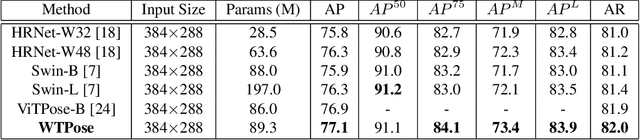
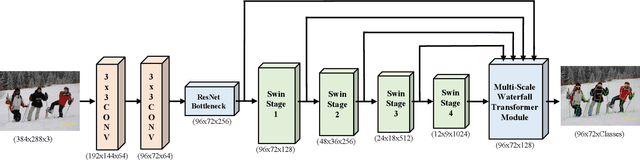
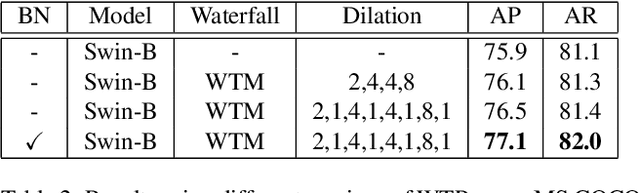
We propose the Waterfall Transformer architecture for Pose estimation (WTPose), a single-pass, end-to-end trainable framework designed for multi-person pose estimation. Our framework leverages a transformer-based waterfall module that generates multi-scale feature maps from various backbone stages. The module performs filtering in the cascade architecture to expand the receptive fields and to capture local and global context, therefore increasing the overall feature representation capability of the network. Our experiments on the COCO dataset demonstrate that the proposed WTPose architecture, with a modified Swin backbone and transformer-based waterfall module, outperforms other transformer architectures for multi-person pose estimation
LRP-QViT: Mixed-Precision Vision Transformer Quantization via Layer-wise Relevance Propagation
Jan 20, 2024Vision transformers (ViTs) have demonstrated remarkable performance across various visual tasks. However, ViT models suffer from substantial computational and memory requirements, making it challenging to deploy them on resource-constrained platforms. Quantization is a popular approach for reducing model size, but most studies mainly focus on equal bit-width quantization for the entire network, resulting in sub-optimal solutions. While there are few works on mixed precision quantization (MPQ) for ViTs, they typically rely on search space-based methods or employ mixed precision arbitrarily. In this paper, we introduce LRP-QViT, an explainability-based method for assigning mixed-precision bit allocations to different layers based on their importance during classification. Specifically, to measure the contribution score of each layer in predicting the target class, we employ the Layer-wise Relevance Propagation (LRP) method. LRP assigns local relevance at the output layer and propagates it through all layers, distributing the relevance until it reaches the input layers. These relevance scores serve as indicators for computing the layer contribution score. Additionally, we have introduced a clipped channel-wise quantization aimed at eliminating outliers from post-LayerNorm activations to alleviate severe inter-channel variations. To validate and assess our approach, we employ LRP-QViT across ViT, DeiT, and Swin transformer models on various datasets. Our experimental findings demonstrate that both our fixed-bit and mixed-bit post-training quantization methods surpass existing models in the context of 4-bit and 6-bit quantization.