 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaterfall Transformer for Multi-person Pose Estimation
Nov 28, 2024
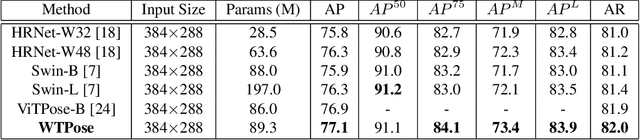
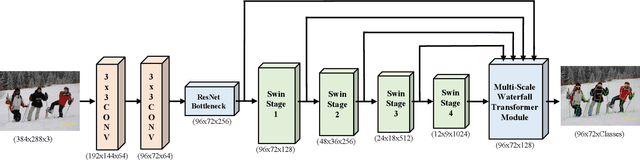
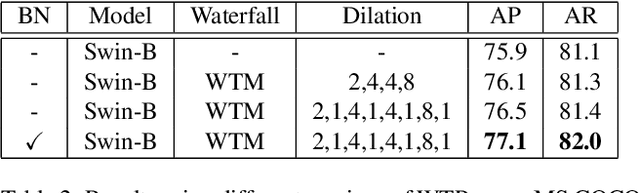
We propose the Waterfall Transformer architecture for Pose estimation (WTPose), a single-pass, end-to-end trainable framework designed for multi-person pose estimation. Our framework leverages a transformer-based waterfall module that generates multi-scale feature maps from various backbone stages. The module performs filtering in the cascade architecture to expand the receptive fields and to capture local and global context, therefore increasing the overall feature representation capability of the network. Our experiments on the COCO dataset demonstrate that the proposed WTPose architecture, with a modified Swin backbone and transformer-based waterfall module, outperforms other transformer architectures for multi-person pose estimation
BAPose: Bottom-Up Pose Estimation with Disentangled Waterfall Representations
Dec 20, 2021
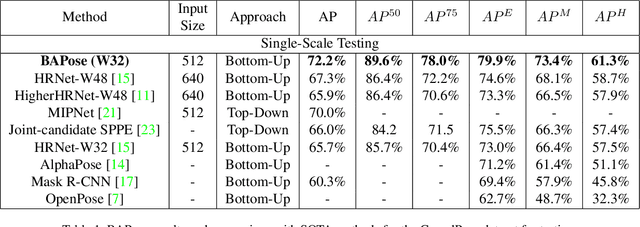
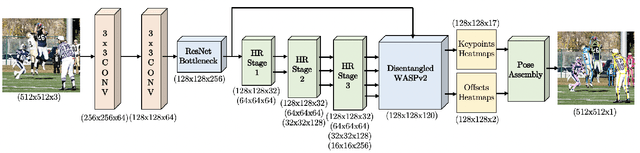
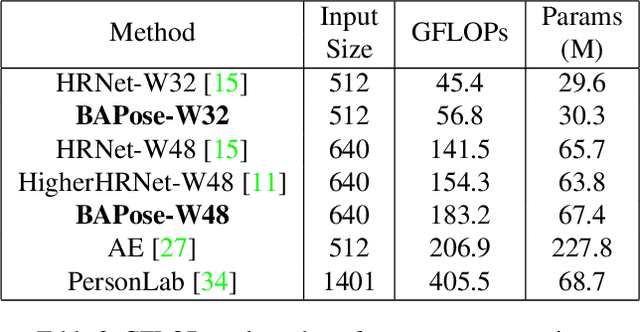
We propose BAPose, a novel bottom-up approach that achieves state-of-the-art results for multi-person pose estimation. Our end-to-end trainable framework leverages a disentangled multi-scale waterfall architecture and incorporates adaptive convolutions to infer keypoints more precisely in crowded scenes with occlusions. The multi-scale representations, obtained by the disentangled waterfall module in BAPose, leverage the efficiency of progressive filtering in the cascade architecture, while maintaining multi-scale fields-of-view comparable to spatial pyramid configurations. Our results on the challenging COCO and CrowdPose datasets demonstrate that BAPose is an efficient and robust framework for multi-person pose estimation, achieving significant improvements on state-of-the-art accuracy.
OmniPose: A Multi-Scale Framework for Multi-Person Pose Estimation
Mar 18, 2021
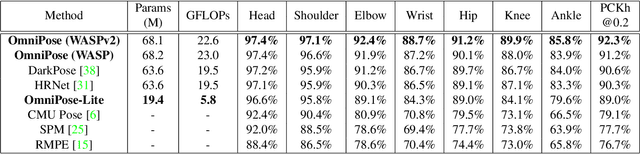

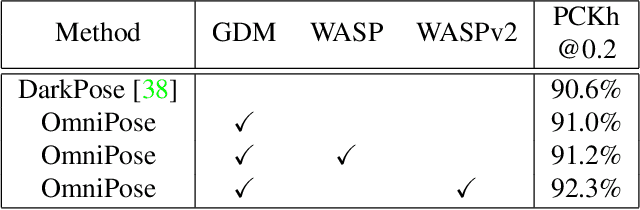
We propose OmniPose, a single-pass, end-to-end trainable framework, that achieves state-of-the-art results for multi-person pose estimation. Using a novel waterfall module, the OmniPose architecture leverages multi-scale feature representations that increase the effectiveness of backbone feature extractors, without the need for post-processing. OmniPose incorporates contextual information across scales and joint localization with Gaussian heatmap modulation at the multi-scale feature extractor to estimate human pose with state-of-the-art accuracy. The multi-scale representations, obtained by the improved waterfall module in OmniPose, leverage the efficiency of progressive filtering in the cascade architecture, while maintaining multi-scale fields-of-view comparable to spatial pyramid configurations. Our results on multiple datasets demonstrate that OmniPose, with an improved HRNet backbone and waterfall module, is a robust and efficient architecture for multi-person pose estimation that achieves state-of-the-art results.
UniPose: Unified Human Pose Estimation in Single Images and Videos
Jan 22, 2020
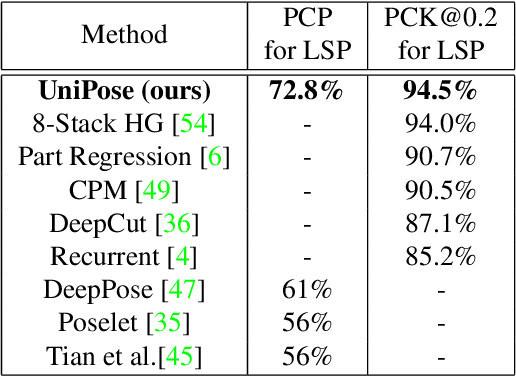

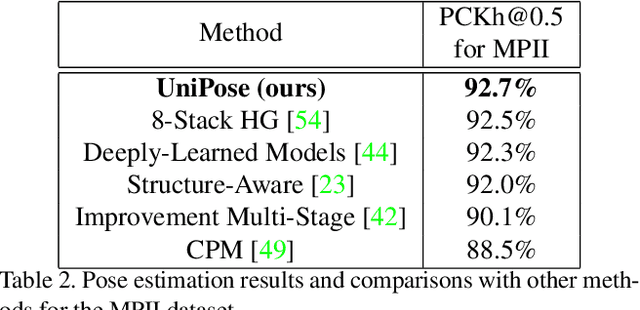
We propose UniPose, a unified framework for human pose estimation, based on our "Waterfall" Atrous Spatial Pooling architecture, that achieves state-of-art-results on several pose estimation metrics. Current pose estimation methods utilizing standard CNN architectures heavily rely on statistical postprocessing or predefined anchor poses for joint localization. UniPose incorporates contextual segmentation and joint localization to estimate the human pose in a single stage, with high accuracy, without relying on statistical postprocessing methods. The Waterfall module in UniPose leverages the efficiency of progressive filtering in the cascade architecture, while maintaining multi-scale fields-of-view comparable to spatial pyramid configurations. Additionally, our method is extended to UniPose-LSTM for multi-frame processing and achieves state-of-the-art results for temporal pose estimation in Video. Our results on multiple datasets demonstrate that UniPose, with a ResNet backbone and Waterfall module, is a robust and efficient architecture for pose estimation obtaining state-of-the-art results in single person pose detection for both single images and videos.
Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation
Dec 06, 2019
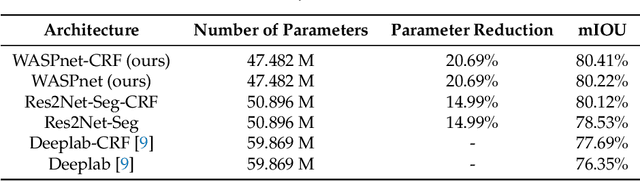
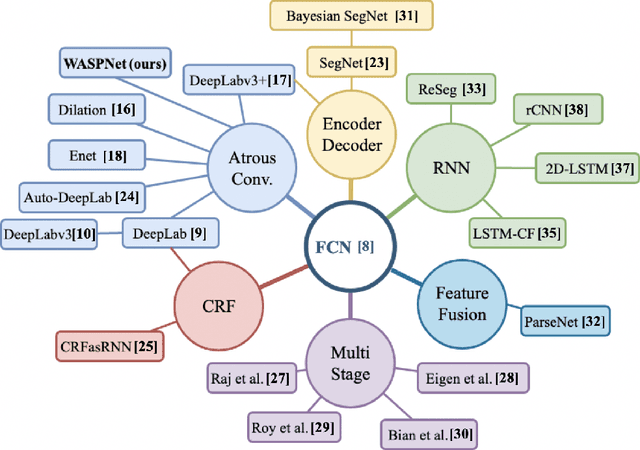

We propose a new efficient architecture for semantic segmentation, based on a "Waterfall" Atrous Spatial Pooling architecture, that achieves a considerable accuracy increase while decreasing the number of network parameters and memory footprint. The proposed Waterfall architecture leverages the efficiency of progressive filtering in the cascade architecture while maintaining multiscale fields-of-view comparable to spatial pyramid configurations. Additionally, our method does not rely on a postprocessing stage with Conditional Random Fields, which further reduces complexity and required training time. We demonstrate that the Waterfall approach with a ResNet backbone is a robust and efficient architecture for semantic segmentation obtaining state-of-the-art results with significant reduction in the number of parameters for the Pascal VOC dataset and the Cityscapes dataset.
* 17 pages, 11 figures