 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnknown Sample Discovery for Source Free Open Set Domain Adaptation
Dec 05, 2023Open Set Domain Adaptation (OSDA) aims to adapt a model trained on a source domain to a target domain that undergoes distribution shift and contains samples from novel classes outside the source domain. Source-free OSDA (SF-OSDA) techniques eliminate the need to access source domain samples, but current SF-OSDA methods utilize only the known classes in the target domain for adaptation, and require access to the entire target domain even during inference after adaptation, to make the distinction between known and unknown samples. In this paper, we introduce Unknown Sample Discovery (USD) as an SF-OSDA method that utilizes a temporally ensembled teacher model to conduct known-unknown target sample separation and adapts the student model to the target domain over all classes using co-training and temporal consistency between the teacher and the student. USD promotes Jensen-Shannon distance (JSD) as an effective measure for known-unknown sample separation. Our teacher-student framework significantly reduces error accumulation resulting from imperfect known-unknown sample separation, while curriculum guidance helps to reliably learn the distinction between target known and target unknown subspaces. USD appends the target model with an unknown class node, thus readily classifying a target sample into any of the known or unknown classes in subsequent post-adaptation inference stages. Empirical results show that USD is superior to existing SF-OSDA methods and is competitive with current OSDA models that utilize both source and target domains during adaptation.
Continual Domain Adaptation on Aerial Images under Gradually Degrading Weather
Aug 14, 2023Domain adaptation (DA) strives to mitigate the domain gap between the source domain where a model is trained, and the target domain where the model is deployed. When a deep learning model is deployed on an aerial platform, it may face gradually degrading weather conditions during operation, leading to widening domain gaps between the training data and the encountered evaluation data. We synthesize two such gradually worsening weather conditions on real images from two existing aerial imagery datasets, generating a total of four benchmark datasets. Under the continual, or test-time adaptation setting, we evaluate three DA models on our datasets: a baseline standard DA model and two continual DA models. In such setting, the models can access only one small portion, or one batch of the target data at a time, and adaptation takes place continually, and over only one epoch of the data. The combination of the constraints of continual adaptation, and gradually deteriorating weather conditions provide the practical DA scenario for aerial deployment. Among the evaluated models, we consider both convolutional and transformer architectures for comparison. We discover stability issues during adaptation for existing buffer-fed continual DA methods, and offer gradient normalization as a simple solution to curb training instability.
Curriculum Guided Domain Adaptation in the Dark
Aug 02, 2023Addressing the rising concerns of privacy and security, domain adaptation in the dark aims to adapt a black-box source trained model to an unlabeled target domain without access to any source data or source model parameters. The need for domain adaptation of black-box predictors becomes even more pronounced to protect intellectual property as deep learning based solutions are becoming increasingly commercialized. Current methods distill noisy predictions on the target data obtained from the source model to the target model, and/or separate clean/noisy target samples before adapting using traditional noisy label learning algorithms. However, these methods do not utilize the easy-to-hard learning nature of the clean/noisy data splits. Also, none of the existing methods are end-to-end, and require a separate fine-tuning stage and an initial warmup stage. In this work, we present Curriculum Adaptation for Black-Box (CABB) which provides a curriculum guided adaptation approach to gradually train the target model, first on target data with high confidence (clean) labels, and later on target data with noisy labels. CABB utilizes Jensen-Shannon divergence as a better criterion for clean-noisy sample separation, compared to the traditional criterion of cross entropy loss. Our method utilizes co-training of a dual-branch network to suppress error accumulation resulting from confirmation bias. The proposed approach is end-to-end trainable and does not require any extra finetuning stage, unlike existing methods. Empirical results on standard domain adaptation datasets show that CABB outperforms existing state-of-the-art black-box DA models and is comparable to white-box domain adaptation models.
ConDA: Continual Unsupervised Domain Adaptation
Apr 07, 2021
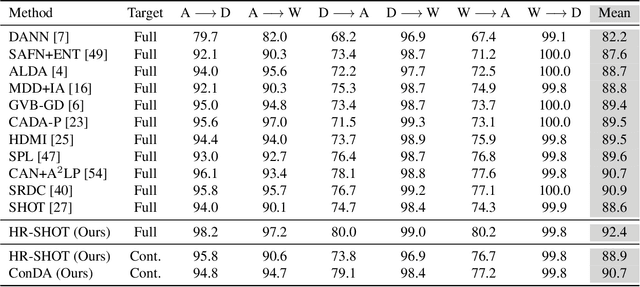
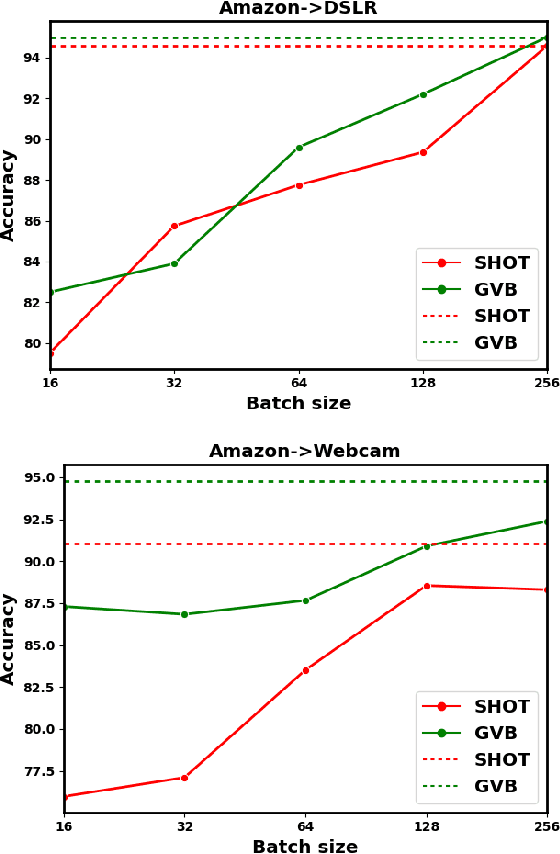
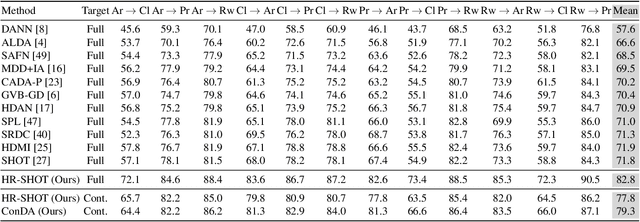
Domain Adaptation (DA) techniques are important for overcoming the domain shift between the source domain used for training and the target domain where testing takes place. However, current DA methods assume that the entire target domain is available during adaptation, which may not hold in practice. This paper considers a more realistic scenario, where target data become available in smaller batches and adaptation on the entire target domain is not feasible. In our work, we introduce a new, data-constrained DA paradigm where unlabeled target samples are received in batches and adaptation is performed continually. We propose a novel source-free method for continual unsupervised domain adaptation that utilizes a buffer for selective replay of previously seen samples. In our continual DA framework, we selectively mix samples from incoming batches with data stored in a buffer using buffer management strategies and use the combination to incrementally update our model. We evaluate the classification performance of the continual DA approach with state-of-the-art DA methods based on the entire target domain. Our results on three popular DA datasets demonstrate that our method outperforms many existing state-of-the-art DA methods with access to the entire target domain during adaptation.