 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciPIP: An LLM-based Scientific Paper Idea Proposer
Oct 30, 2024



The exponential growth of knowledge and the increasing complexity of interdisciplinary research pose significant challenges for researchers, including information overload and difficulties in exploring novel ideas. The advancements in large language models (LLMs), such as GPT-4, have shown great potential in enhancing idea proposals, but how to effectively utilize large models for reasonable idea proposal has not been thoroughly explored. This paper proposes a scientific paper idea proposer (SciPIP). Based on a user-provided research background, SciPIP retrieves helpful papers from a literature database while leveraging the capabilities of LLMs to generate more novel and feasible ideas. To this end, 1) we construct a literature retrieval database, extracting lots of papers' multi-dimension information for fast access. Then, a literature retrieval method based on semantics, entity, and citation co-occurrences is proposed to search relevant literature from multiple aspects based on the user-provided background. 2) After literature retrieval, we introduce dual-path idea proposal strategies, where one path infers solutions from the retrieved literature and the other path generates original ideas through model brainstorming. We then combine the two to achieve a good balance between feasibility and originality. Through extensive experiments on the natural language processing (NLP) field, we demonstrate that SciPIP can retrieve citations similar to those of existing top conference papers and generate many ideas consistent with them. Additionally, we evaluate the originality of other ideas generated by SciPIP using large language models, further validating the effectiveness of our proposed method. The code and the database are released at https://github.com/cheerss/SciPIP.
Model Compression and Efficient Inference for Large Language Models: A Survey
Feb 15, 2024



Transformer based large language models have achieved tremendous success. However, the significant memory and computational costs incurred during the inference process make it challenging to deploy large models on resource-constrained devices. In this paper, we investigate compression and efficient inference methods for large language models from an algorithmic perspective. Regarding taxonomy, similar to smaller models, compression and acceleration algorithms for large language models can still be categorized into quantization, pruning, distillation, compact architecture design, dynamic networks. However, Large language models have two prominent characteristics compared to smaller models: (1) Most of compression algorithms require finetuning or even retraining the model after compression. The most notable aspect of large models is the very high cost associated with model finetuning or training. Therefore, many algorithms for large models, such as quantization and pruning, start to explore tuning-free algorithms. (2) Large models emphasize versatility and generalization rather than performance on a single task. Hence, many algorithms, such as knowledge distillation, focus on how to preserving their versatility and generalization after compression. Since these two characteristics were not very pronounced in early large models, we further distinguish large language models into medium models and ``real'' large models. Additionally, we also provide an introduction to some mature frameworks for efficient inference of large models, which can support basic compression or acceleration algorithms, greatly facilitating model deployment for users.
SANDFORMER: CNN and Transformer under Gated Fusion for Sand Dust Image Restoration
Mar 08, 2023Although Convolutional Neural Networks (CNN) have made good progress in image restoration, the intrinsic equivalence and locality of convolutions still constrain further improvements in image quality. Recent vision transformer and self-attention have achieved promising results on various computer vision tasks. However, directly utilizing Transformer for image restoration is a challenging task. In this paper, we introduce an effective hybrid architecture for sand image restoration tasks, which leverages local features from CNN and long-range dependencies captured by transformer to improve the results further. We propose an efficient hybrid structure for sand dust image restoration to solve the feature inconsistency issue between Transformer and CNN. The framework complements each representation by modulating features from the CNN-based and Transformer-based branches rather than simply adding or concatenating features. Experiments demonstrate that SandFormer achieves significant performance improvements in synthetic and real dust scenes compared to previous sand image restoration methods.
Optimising Stochastic Routing for Taxi Fleets with Model Enhanced Reinforcement Learning
Oct 22, 2020
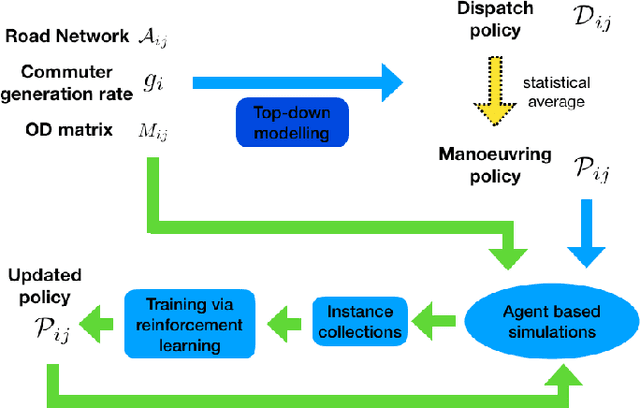
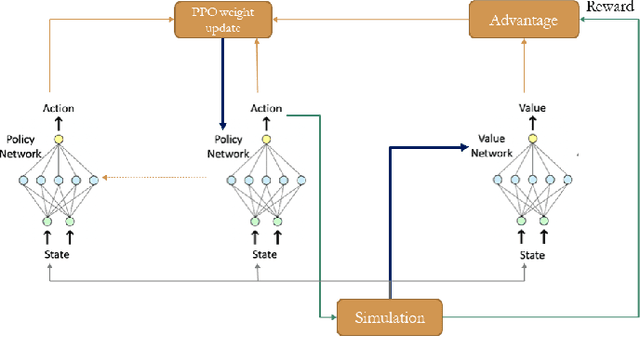
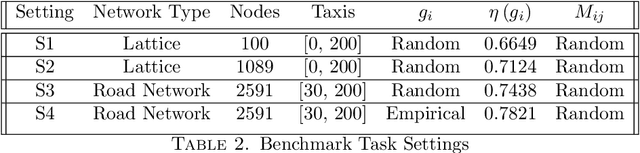
The future of mobility-as-a-Service (Maas)should embrace an integrated system of ride-hailing, street-hailing and ride-sharing with optimised intelligent vehicle routing in response to a real-time, stochastic demand pattern. We aim to optimise routing policies for a large fleet of vehicles for street-hailing services, given a stochastic demand pattern in small to medium-sized road networks. A model-based dispatch algorithm, a high performance model-free reinforcement learning based algorithm and a novel hybrid algorithm combining the benefits of both the top-down approach and the model-free reinforcement learning have been proposed to route the \emph{vacant} vehicles. We design our reinforcement learning based routing algorithm using proximal policy optimisation and combined intrinsic and extrinsic rewards to strike a balance between exploration and exploitation. Using a large-scale agent-based microscopic simulation platform to evaluate our proposed algorithms, our model-free reinforcement learning and hybrid algorithm show excellent performance on both artificial road network and community-based Singapore road network with empirical demands, and our hybrid algorithm can significantly accelerate the model-free learner in the process of learning.