 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
PI2I: A Personalized Item-Based Collaborative Filtering Retrieval Framework
Jan 23, 2026Efficiently selecting relevant content from vast candidate pools is a critical challenge in modern recommender systems. Traditional methods, such as item-to-item collaborative filtering (CF) and two-tower models, often fall short in capturing the complex user-item interactions due to uniform truncation strategies and overdue user-item crossing. To address these limitations, we propose Personalized Item-to-Item (PI2I), a novel two-stage retrieval framework that enhances the personalization capabilities of CF. In the first Indexer Building Stage (IBS), we optimize the retrieval pool by relaxing truncation thresholds to maximize Hit Rate, thereby temporarily retaining more items users might be interested in. In the second Personalized Retrieval Stage (PRS), we introduce an interactive scoring model to overcome the limitations of inner product calculations, allowing for richer modeling of intricate user-item interactions. Additionally, we construct negative samples based on the trigger-target (item-to-item) relationship, ensuring consistency between offline training and online inference. Offline experiments on large-scale real-world datasets demonstrate that PI2I outperforms traditional CF methods and rivals Two-Tower models. Deployed in the "Guess You Like" section on Taobao, PI2I achieved a 1.05% increase in online transaction rates. In addition, we have released a large-scale recommendation dataset collected from Taobao, containing 130 million real-world user interactions used in the experiments of this paper. The dataset is publicly available at https://huggingface.co/datasets/PI2I/PI2I, which could serve as a valuable benchmark for the research community.
RecGPT-V2 Technical Report
Dec 16, 2025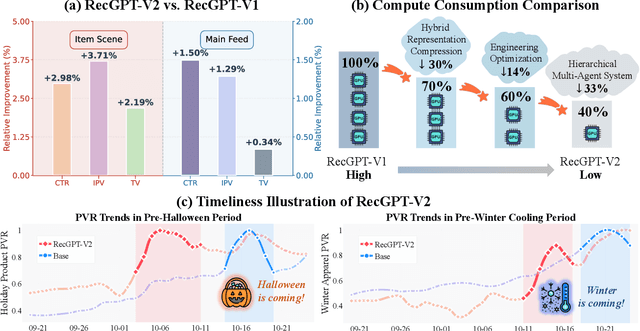
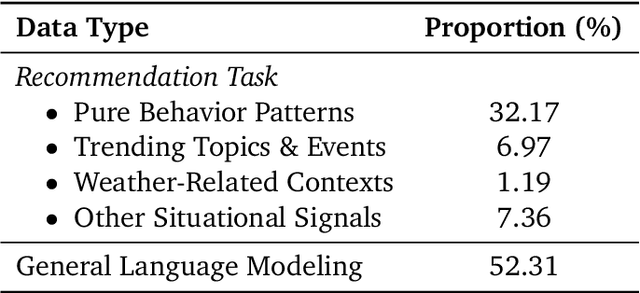
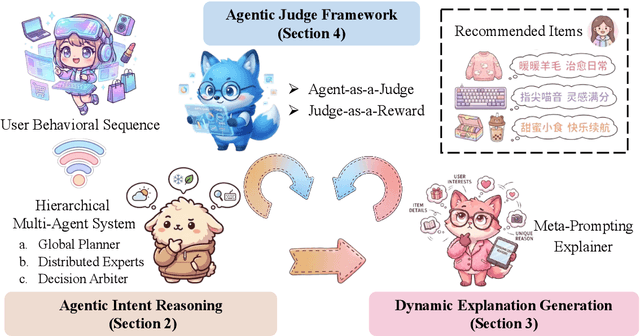

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
DuFFin: A Dual-Level Fingerprinting Framework for LLMs IP Protection
May 22, 2025Large language models (LLMs) are considered valuable Intellectual Properties (IP) for legitimate owners due to the enormous computational cost of training. It is crucial to protect the IP of LLMs from malicious stealing or unauthorized deployment. Despite existing efforts in watermarking and fingerprinting LLMs, these methods either impact the text generation process or are limited in white-box access to the suspect model, making them impractical. Hence, we propose DuFFin, a novel $\textbf{Du}$al-Level $\textbf{Fin}$gerprinting $\textbf{F}$ramework for black-box setting ownership verification. DuFFin extracts the trigger pattern and the knowledge-level fingerprints to identify the source of a suspect model. We conduct experiments on a variety of models collected from the open-source website, including four popular base models as protected LLMs and their fine-tuning, quantization, and safety alignment versions, which are released by large companies, start-ups, and individual users. Results show that our method can accurately verify the copyright of the base protected LLM on their model variants, achieving the IP-ROC metric greater than 0.95. Our code is available at https://github.com/yuliangyan0807/llm-fingerprint.
SlimGPT: Layer-wise Structured Pruning for Large Language Models
Dec 24, 2024



Large language models (LLMs) have garnered significant attention for their remarkable capabilities across various domains, whose vast parameter scales present challenges for practical deployment. Structured pruning is an effective method to balance model performance with efficiency, but performance restoration under computational resource constraints is a principal challenge in pruning LLMs. Therefore, we present a low-cost and fast structured pruning method for LLMs named SlimGPT based on the Optimal Brain Surgeon framework. We propose Batched Greedy Pruning for rapid and near-optimal pruning, which enhances the accuracy of head-wise pruning error estimation through grouped Cholesky decomposition and improves the pruning efficiency of FFN via Dynamic Group Size, thereby achieving approximate local optimal pruning results within one hour. Besides, we explore the limitations of layer-wise pruning from the perspective of error accumulation and propose Incremental Pruning Ratio, a non-uniform pruning strategy to reduce performance degradation. Experimental results on the LLaMA benchmark show that SlimGPT outperforms other methods and achieves state-of-the-art results.
Simple but Efficient: A Multi-Scenario Nearline Retrieval Framework for Recommendation on Taobao
Aug 06, 2024



In recommendation systems, the matching stage is becoming increasingly critical, serving as the upper limit for the entire recommendation process. Recently, some studies have started to explore the use of multi-scenario information for recommendations, such as model-based and data-based approaches. However, the matching stage faces significant challenges due to the need for ultra-large-scale retrieval and meeting low latency requirements. As a result, the methods applied at this stage (collaborative filtering and two-tower models) are often designed to be lightweight, hindering the full utilization of extensive information. On the other hand, the ranking stage features the most sophisticated models with the strongest scoring capabilities, but due to the limited screen size of mobile devices, most of the ranked results may not gain exposure or be displayed. In this paper, we introduce an innovative multi-scenario nearline retrieval framework. It operates by harnessing ranking logs from various scenarios through Flink, allowing us to incorporate finely ranked results from other scenarios into our matching stage in near real-time. Besides, we propose a streaming scoring module, which selects a crucial subset from the candidate pool. Implemented on the "Guess You Like" (homepage of the Taobao APP), China's premier e-commerce platform, our method has shown substantial improvements-most notably, a 5% uptick in product transactions. Furthermore, the proposed approach is not only model-free but also highly efficient, suggesting it can be quickly implemented in diverse scenarios and demonstrate promising performance.
ChemLLM: A Chemical Large Language Model
Feb 10, 2024



Large language models (LLMs) have made impressive progress in chemistry applications, including molecular property prediction, molecular generation, experimental protocol design, etc. However, the community lacks a dialogue-based model specifically designed for chemistry. The challenge arises from the fact that most chemical data and scientific knowledge are primarily stored in structured databases, and the direct use of these structured data compromises the model's ability to maintain coherent dialogue. To tackle this issue, we develop a novel template-based instruction construction method that transforms structured knowledge into plain dialogue, making it suitable for language model training. By leveraging this approach, we develop ChemLLM, the first large language model dedicated to chemistry, capable of performing various tasks across chemical disciplines with smooth dialogue interaction. ChemLLM beats GPT-3.5 on all three principal tasks in chemistry, i.e., name conversion, molecular caption, and reaction prediction, and surpasses GPT-4 on two of them. Remarkably, ChemLLM also shows exceptional adaptability to related mathematical and physical tasks despite being trained mainly on chemical-centric corpora. Furthermore, ChemLLM demonstrates proficiency in specialized NLP tasks within chemistry, such as literature translation and cheminformatic programming. ChemLLM opens up a new avenue for exploration within chemical studies, while our method of integrating structured chemical knowledge into dialogue systems sets a new frontier for developing LLMs across various scientific fields. Codes, Datasets, and Model weights are publicly accessible at hf.co/AI4Chem/ChemLLM-7B-Chat.