 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI2I: A Personalized Item-Based Collaborative Filtering Retrieval Framework
Jan 23, 2026Efficiently selecting relevant content from vast candidate pools is a critical challenge in modern recommender systems. Traditional methods, such as item-to-item collaborative filtering (CF) and two-tower models, often fall short in capturing the complex user-item interactions due to uniform truncation strategies and overdue user-item crossing. To address these limitations, we propose Personalized Item-to-Item (PI2I), a novel two-stage retrieval framework that enhances the personalization capabilities of CF. In the first Indexer Building Stage (IBS), we optimize the retrieval pool by relaxing truncation thresholds to maximize Hit Rate, thereby temporarily retaining more items users might be interested in. In the second Personalized Retrieval Stage (PRS), we introduce an interactive scoring model to overcome the limitations of inner product calculations, allowing for richer modeling of intricate user-item interactions. Additionally, we construct negative samples based on the trigger-target (item-to-item) relationship, ensuring consistency between offline training and online inference. Offline experiments on large-scale real-world datasets demonstrate that PI2I outperforms traditional CF methods and rivals Two-Tower models. Deployed in the "Guess You Like" section on Taobao, PI2I achieved a 1.05% increase in online transaction rates. In addition, we have released a large-scale recommendation dataset collected from Taobao, containing 130 million real-world user interactions used in the experiments of this paper. The dataset is publicly available at https://huggingface.co/datasets/PI2I/PI2I, which could serve as a valuable benchmark for the research community.
Simple but Efficient: A Multi-Scenario Nearline Retrieval Framework for Recommendation on Taobao
Aug 06, 2024



In recommendation systems, the matching stage is becoming increasingly critical, serving as the upper limit for the entire recommendation process. Recently, some studies have started to explore the use of multi-scenario information for recommendations, such as model-based and data-based approaches. However, the matching stage faces significant challenges due to the need for ultra-large-scale retrieval and meeting low latency requirements. As a result, the methods applied at this stage (collaborative filtering and two-tower models) are often designed to be lightweight, hindering the full utilization of extensive information. On the other hand, the ranking stage features the most sophisticated models with the strongest scoring capabilities, but due to the limited screen size of mobile devices, most of the ranked results may not gain exposure or be displayed. In this paper, we introduce an innovative multi-scenario nearline retrieval framework. It operates by harnessing ranking logs from various scenarios through Flink, allowing us to incorporate finely ranked results from other scenarios into our matching stage in near real-time. Besides, we propose a streaming scoring module, which selects a crucial subset from the candidate pool. Implemented on the "Guess You Like" (homepage of the Taobao APP), China's premier e-commerce platform, our method has shown substantial improvements-most notably, a 5% uptick in product transactions. Furthermore, the proposed approach is not only model-free but also highly efficient, suggesting it can be quickly implemented in diverse scenarios and demonstrate promising performance.
Query-based Interactive Recommendation by Meta-Path and Adapted Attention-GRU
Jun 24, 2019
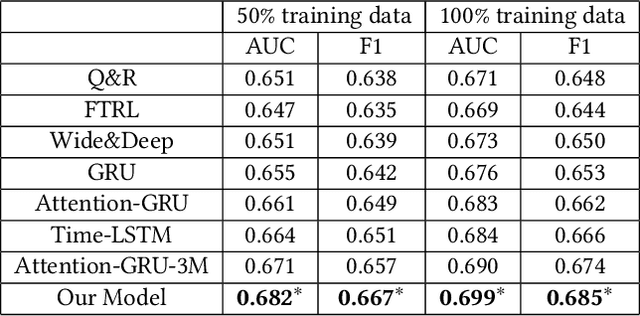


Recently, interactive recommender systems are becoming increasingly popular. The insight is that, with the interaction between users and the system, (1) users can actively intervene the recommendation results rather than passively receive them, and (2) the system learns more about users so as to provide better recommendation. We focus on the single-round interaction, i.e. the system asks the user a question (Step 1), and exploits his feedback to generate better recommendation (Step 2). A novel query-based interactive recommender system is proposed in this paper, where \textbf{personalized questions are accurately generated from millions of automatically constructed questions} in Step 1, and \textbf{the recommendation is ensured to be closely-related to users' feedback} in Step 2. We achieve this by transforming Step 1 into a query recommendation task and Step 2 into a retrieval task. The former task is our key challenge. We firstly propose a model based on Meta-Path to efficiently retrieve hundreds of query candidates from the large query pool. Then an adapted Attention-GRU model is developed to effectively rank these candidates for recommendation. Offline and online experiments on Taobao, a large-scale e-commerce platform in China, verify the effectiveness of our interactive system. The system has already gone into production in the homepage of Taobao App since Nov. 11, 2018 (see https://v.qq.com/x/page/s0833tkp1uo.html on how it works online). Our code and dataset are public in https://github.com/zyody/QueryQR.