 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiTv2: Scalable and Improved Flexible Vision Transformer for Diffusion Model
Oct 17, 2024



\textit{Nature is infinitely resolution-free}. In the context of this reality, existing diffusion models, such as Diffusion Transformers, often face challenges when processing image resolutions outside of their trained domain. To address this limitation, we conceptualize images as sequences of tokens with dynamic sizes, rather than traditional methods that perceive images as fixed-resolution grids. This perspective enables a flexible training strategy that seamlessly accommodates various aspect ratios during both training and inference, thus promoting resolution generalization and eliminating biases introduced by image cropping. On this basis, we present the \textbf{Flexible Vision Transformer} (FiT), a transformer architecture specifically designed for generating images with \textit{unrestricted resolutions and aspect ratios}. We further upgrade the FiT to FiTv2 with several innovative designs, includingthe Query-Key vector normalization, the AdaLN-LoRA module, a rectified flow scheduler, and a Logit-Normal sampler. Enhanced by a meticulously adjusted network structure, FiTv2 exhibits $2\times$ convergence speed of FiT. When incorporating advanced training-free extrapolation techniques, FiTv2 demonstrates remarkable adaptability in both resolution extrapolation and diverse resolution generation. Additionally, our exploration of the scalability of the FiTv2 model reveals that larger models exhibit better computational efficiency. Furthermore, we introduce an efficient post-training strategy to adapt a pre-trained model for the high-resolution generation. Comprehensive experiments demonstrate the exceptional performance of FiTv2 across a broad range of resolutions. We have released all the codes and models at \url{https://github.com/whlzy/FiT} to promote the exploration of diffusion transformer models for arbitrary-resolution image generation.
PredBench: Benchmarking Spatio-Temporal Prediction across Diverse Disciplines
Jul 11, 2024

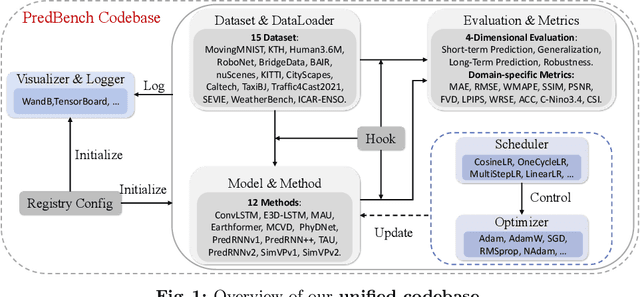

In this paper, we introduce PredBench, a benchmark tailored for the holistic evaluation of spatio-temporal prediction networks. Despite significant progress in this field, there remains a lack of a standardized framework for a detailed and comparative analysis of various prediction network architectures. PredBench addresses this gap by conducting large-scale experiments, upholding standardized and appropriate experimental settings, and implementing multi-dimensional evaluations. This benchmark integrates 12 widely adopted methods with 15 diverse datasets across multiple application domains, offering extensive evaluation of contemporary spatio-temporal prediction networks. Through meticulous calibration of prediction settings across various applications, PredBench ensures evaluations relevant to their intended use and enables fair comparisons. Moreover, its multi-dimensional evaluation framework broadens the analysis with a comprehensive set of metrics, providing deep insights into the capabilities of models. The findings from our research offer strategic directions for future developments in the field. Our codebase is available at https://github.com/WZDTHU/PredBench.