 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Intent Attribute-Aware Text Matching in Searching
Feb 12, 2024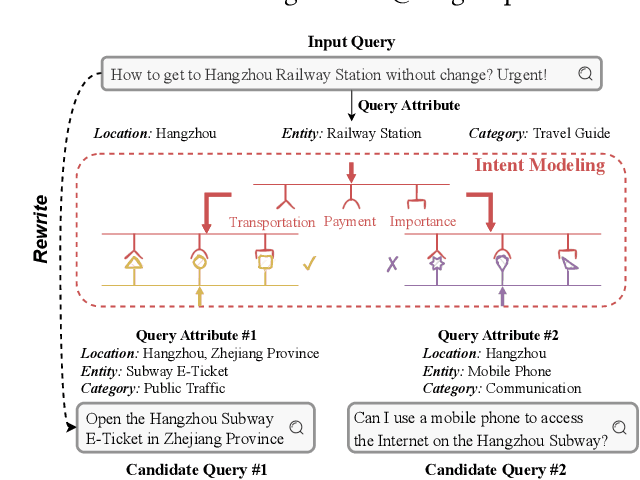
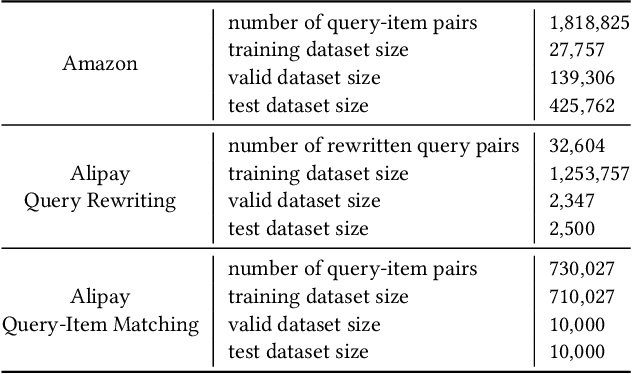
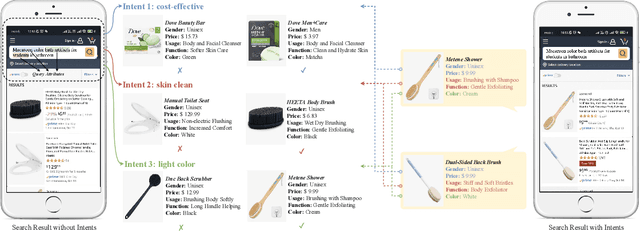
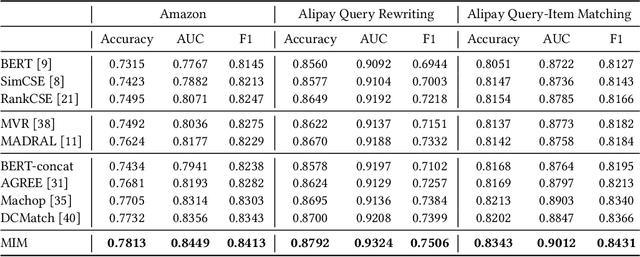
Text matching systems have become a fundamental service in most searching platforms. For instance, they are responsible for matching user queries to relevant candidate items, or rewriting the user-input query to a pre-selected high-performing one for a better search experience. In practice, both the queries and items often contain multiple attributes, such as the category of the item and the location mentioned in the query, which represent condensed key information that is helpful for matching. However, most of the existing works downplay the effectiveness of attributes by integrating them into text representations as supplementary information. Hence, in this work, we focus on exploring the relationship between the attributes from two sides. Since attributes from two ends are often not aligned in terms of number and type, we propose to exploit the benefit of attributes by multiple-intent modeling. The intents extracted from attributes summarize the diverse needs of queries and provide rich content of items, which are more refined and abstract, and can be aligned for paired inputs. Concretely, we propose a multi-intent attribute-aware matching model (MIM), which consists of three main components: attribute-aware encoder, multi-intent modeling, and intent-aware matching. In the attribute-aware encoder, the text and attributes are weighted and processed through a scaled attention mechanism with regard to the attributes' importance. Afterward, the multi-intent modeling extracts intents from two ends and aligns them. Herein, we come up with a distribution loss to ensure the learned intents are diverse but concentrated, and a kullback-leibler divergence loss that aligns the learned intents. Finally, in the intent-aware matching, the intents are evaluated by a self-supervised masking task, and then incorporated to output the final matching result.
The Extreme Cardiac MRI Analysis Challenge under Respiratory Motion (CMRxMotion)
Oct 12, 2022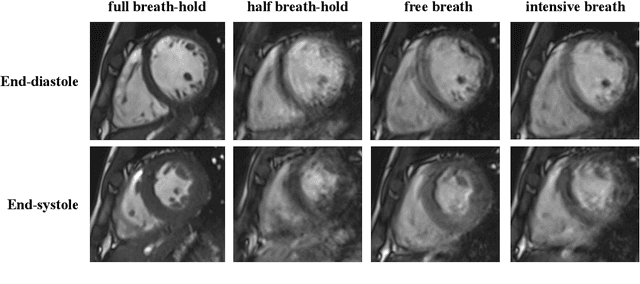
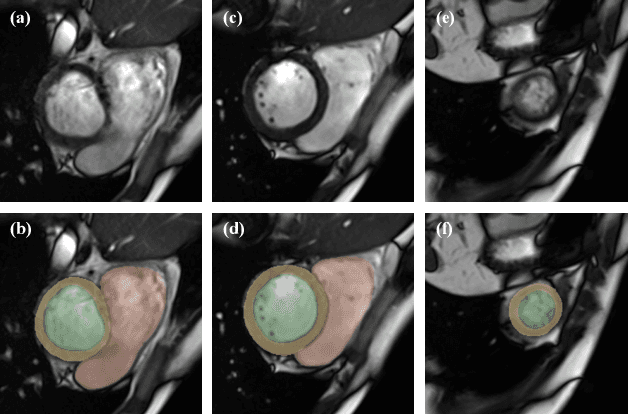

The quality of cardiac magnetic resonance (CMR) imaging is susceptible to respiratory motion artifacts. The model robustness of automated segmentation techniques in face of real-world respiratory motion artifacts is unclear. This manuscript describes the design of extreme cardiac MRI analysis challenge under respiratory motion (CMRxMotion Challenge). The challenge aims to establish a public benchmark dataset to assess the effects of respiratory motion on image quality and examine the robustness of segmentation models. The challenge recruited 40 healthy volunteers to perform different breath-hold behaviors during one imaging visit, obtaining paired cine imaging with artifacts. Radiologists assessed the image quality and annotated the level of respiratory motion artifacts. For those images with diagnostic quality, radiologists further segmented the left ventricle, left ventricle myocardium and right ventricle. The images of training set (20 volunteers) along with the annotations are released to the challenge participants, to develop an automated image quality assessment model (Task 1) and an automated segmentation model (Task 2). The images of validation set (5 volunteers) are released to the challenge participants but the annotations are withheld for online evaluation of submitted predictions. Both the images and annotations of the test set (15 volunteers) were withheld and only used for offline evaluation of submitted containerized dockers. The image quality assessment task is quantitatively evaluated by the Cohen's kappa statistics and the segmentation task is evaluated by the Dice scores and Hausdorff distances.
SelfMix: Robust Learning Against Textual Label Noise with Self-Mixup Training
Oct 11, 2022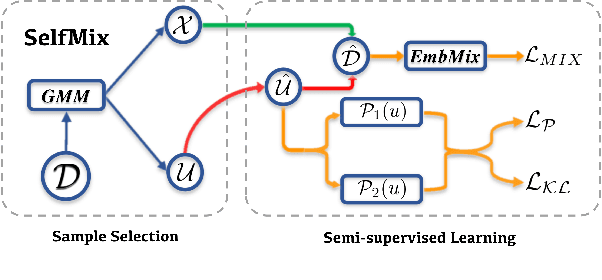

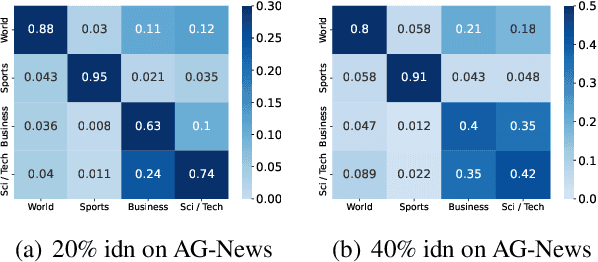
The conventional success of textual classification relies on annotated data, and the new paradigm of pre-trained language models (PLMs) still requires a few labeled data for downstream tasks. However, in real-world applications, label noise inevitably exists in training data, damaging the effectiveness, robustness, and generalization of the models constructed on such data. Recently, remarkable achievements have been made to mitigate this dilemma in visual data, while only a few explore textual data. To fill this gap, we present SelfMix, a simple yet effective method, to handle label noise in text classification tasks. SelfMix uses the Gaussian Mixture Model to separate samples and leverages semi-supervised learning. Unlike previous works requiring multiple models, our method utilizes the dropout mechanism on a single model to reduce the confirmation bias in self-training and introduces a textual-level mixup training strategy. Experimental results on three text classification benchmarks with different types of text show that the performance of our proposed method outperforms these strong baselines designed for both textual and visual data under different noise ratios and noise types. Our code is available at \url{https://github.com/noise-learning/SelfMix}.