 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfMix: Robust Learning Against Textual Label Noise with Self-Mixup Training
Paper and Code
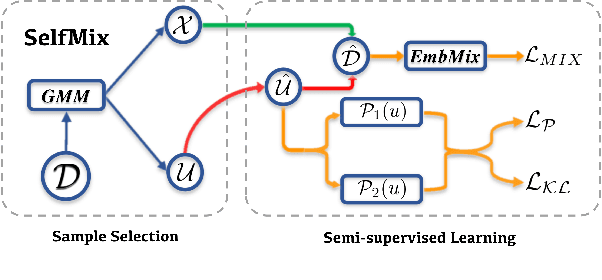

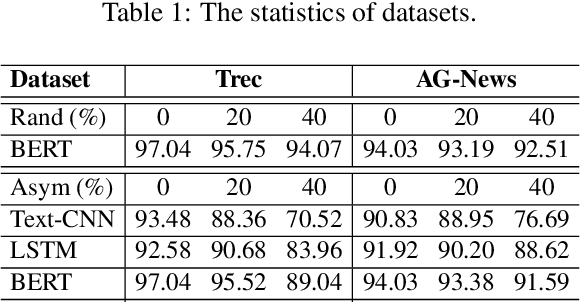
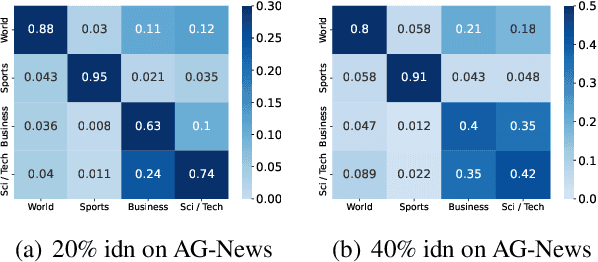
The conventional success of textual classification relies on annotated data, and the new paradigm of pre-trained language models (PLMs) still requires a few labeled data for downstream tasks. However, in real-world applications, label noise inevitably exists in training data, damaging the effectiveness, robustness, and generalization of the models constructed on such data. Recently, remarkable achievements have been made to mitigate this dilemma in visual data, while only a few explore textual data. To fill this gap, we present SelfMix, a simple yet effective method, to handle label noise in text classification tasks. SelfMix uses the Gaussian Mixture Model to separate samples and leverages semi-supervised learning. Unlike previous works requiring multiple models, our method utilizes the dropout mechanism on a single model to reduce the confirmation bias in self-training and introduces a textual-level mixup training strategy. Experimental results on three text classification benchmarks with different types of text show that the performance of our proposed method outperforms these strong baselines designed for both textual and visual data under different noise ratios and noise types. Our code is available at \url{https://github.com/noise-learning/SelfMix}.