 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Multimodal Video Sequence Fusion via Learning Modality-Exclusive and -Agnostic Representations
Paper and Code
Jul 06, 2024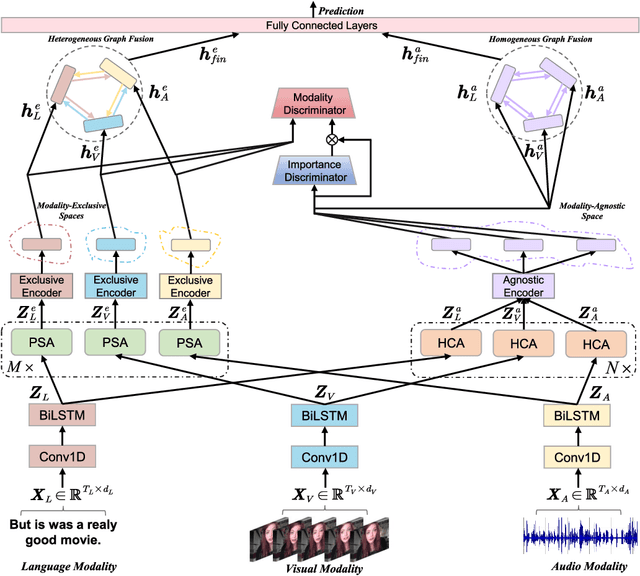
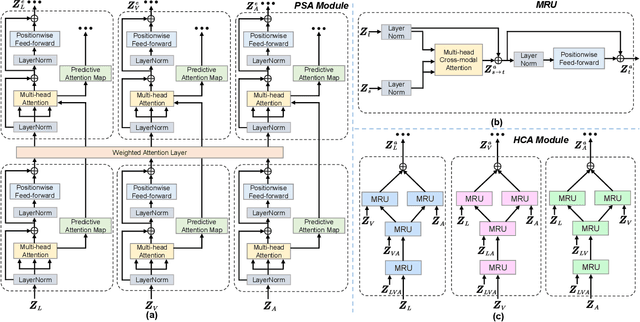

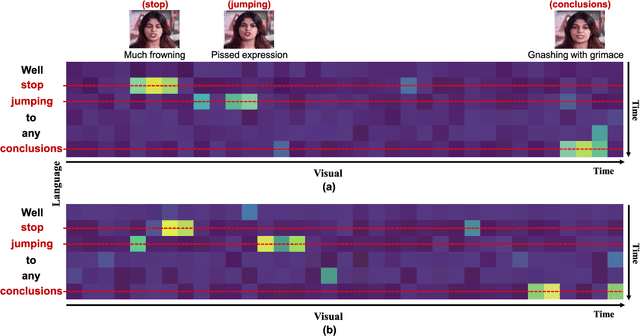
Understanding human intentions (e.g., emotions) from videos has received considerable attention recently. Video streams generally constitute a blend of temporal data stemming from distinct modalities, including natural language, facial expressions, and auditory clues. Despite the impressive advancements of previous works via attention-based paradigms, the inherent temporal asynchrony and modality heterogeneity challenges remain in multimodal sequence fusion, causing adverse performance bottlenecks. To tackle these issues, we propose a Multimodal fusion approach for learning modality-Exclusive and modality-Agnostic representations (MEA) to refine multimodal features and leverage the complementarity across distinct modalities. On the one hand, MEA introduces a predictive self-attention module to capture reliable context dynamics within modalities and reinforce unique features over the modality-exclusive spaces. On the other hand, a hierarchical cross-modal attention module is designed to explore valuable element correlations among modalities over the modality-agnostic space. Meanwhile, a double-discriminator strategy is presented to ensure the production of distinct representations in an adversarial manner. Eventually, we propose a decoupled graph fusion mechanism to enhance knowledge exchange across heterogeneous modalities and learn robust multimodal representations for downstream tasks. Numerous experiments are implemented on three multimodal datasets with asynchronous sequences. Systematic analyses show the necessity of our approach.