 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARSEFIT: Few-shot Prompting with Sparse Fine-tuning for Jointly Generating Predictions and Natural Language Explanations
Paper and Code
May 23, 2023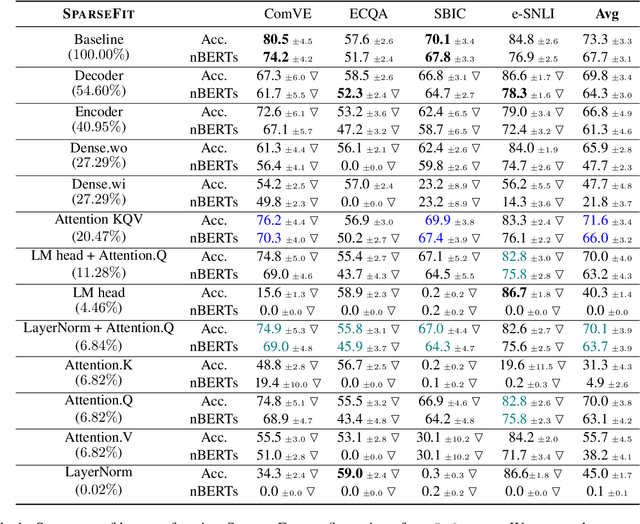
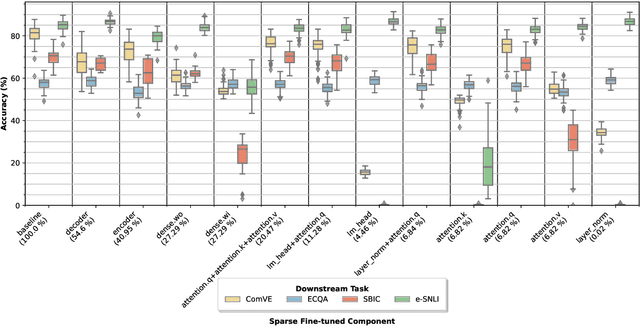
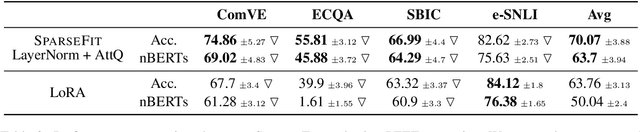
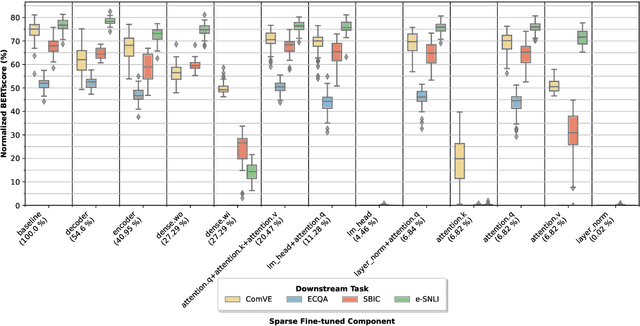
Explaining the decisions of neural models is crucial for ensuring their trustworthiness at deployment time. Using Natural Language Explanations (NLEs) to justify a model's predictions has recently gained increasing interest. However, this approach usually demands large datasets of human-written NLEs for the ground-truth answers, which are expensive and potentially infeasible for some applications. For models to generate high-quality NLEs when only a few NLEs are available, the fine-tuning of Pre-trained Language Models (PLMs) in conjunction with prompt-based learning recently emerged. However, PLMs typically have billions of parameters, making fine-tuning expensive. We propose SparseFit, a sparse few-shot fine-tuning strategy that leverages discrete prompts to jointly generate predictions and NLEs. We experiment with SparseFit on the T5 model and four datasets and compare it against state-of-the-art parameter-efficient fine-tuning techniques. We perform automatic and human evaluations to assess the quality of the model-generated NLEs, finding that fine-tuning only 6.8% of the model parameters leads to competitive results for both the task performance and the quality of the NLEs.